Navigating the Labyrinth: Evaluating and Enhancing LLMs' Ability to Reason About Search Problems
2406.12172
0
0
🏷️
Abstract
Recently, Large Language Models (LLMs) attained impressive performance in math and reasoning benchmarks. However, they still often struggle with logic problems and puzzles that are relatively easy for humans. To further investigate this, we introduce a new benchmark, SearchBench, containing 11 unique search problem types, each equipped with automated pipelines to generate an arbitrary number of instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions. We show that even the most advanced LLMs fail to solve these problems end-to-end in text, e.g. GPT4 solves only 1.4%. SearchBench problems require considering multiple pathways to the solution as well as backtracking, posing a significant challenge to auto-regressive models. Instructing LLMs to generate code that solves the problem helps, but only slightly, e.g., GPT4's performance rises to 11.7%. In this work, we show that in-context learning with A* algorithm implementations enhances performance. The full potential of this promoting approach emerges when combined with our proposed Multi-Stage-Multi-Try method, which breaks down the algorithm implementation into two stages and verifies the first stage against unit tests, raising GPT-4's performance above 57%.
Create account to get full access
Overview
- The paper introduces a new benchmark called SearchBench to evaluate the performance of large language models (LLMs) on various search problem types.
- SearchBench contains 11 unique search problem types, each with automated pipelines to generate instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions.
- The authors show that even the most advanced LLMs, like GPT-4, struggle to solve these problems end-to-end in text, with GPT-4 only solving 1.4% of the problems.
- The paper suggests that these problems require considering multiple pathways to the solution and backtracking, posing a significant challenge to autoregressive models.
- Instructing LLMs to generate code that solves the problem helps, but only slightly, with GPT-4's performance rising to 11.7%.
- The authors demonstrate that in-context learning with A* algorithm implementations and their proposed Multi-Stage-Multi-Try method can significantly enhance LLM performance, with GPT-4's performance rising above 57%.
Plain English Explanation
Large language models (LLMs) like GPT-4 have made impressive strides in various areas, including math and reasoning. However, they still struggle with tasks that are relatively easy for humans, such as logic problems and puzzles. To better understand this, the researchers created a new benchmark called SearchBench, which contains 11 different types of search problems.
These search problems require the LLMs to consider multiple possible solutions and go back and forth to find the best one, which is a significant challenge for models that generate text sequentially. The researchers found that even the powerful GPT-4 could only solve about 1.4% of these problems when asked to provide the solution in text form.
Interestingly, the performance improved slightly when the LLMs were instructed to generate code to solve the problems, with GPT-4 reaching 11.7% success. The researchers then discovered that providing the LLMs with information about the A* algorithm, a commonly used search algorithm, and using a multi-stage approach to verify the solutions, boosted GPT-4's performance to over 57%.
This research suggests that while LLMs are impressive in many ways, they still struggle with complex problem-solving that requires strategic thinking and the ability to consider multiple possible solutions. The SearchBench benchmark provides a useful tool for evaluating the reasoning capabilities of these models and identifying areas for improvement.
Technical Explanation
The paper introduces a new benchmark called SearchBench to evaluate the performance of large language models (LLMs) on various search problem types. The benchmark contains 11 unique search problem types, each with automated pipelines to generate an arbitrary number of instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions.
The researchers tested the performance of state-of-the-art LLMs, including GPT-4, on these problems. They found that even the most advanced LLMs fail to solve these problems end-to-end in text, with GPT-4 only solving 1.4% of the problems. The authors attribute this to the fact that these problems require considering multiple pathways to the solution and backtracking, which poses a significant challenge to autoregressive models.
To address this, the researchers experimented with instructing the LLMs to generate code that solves the problem. This approach slightly improved the performance, with GPT-4's success rate rising to 11.7%. The authors then explored the use of in-context learning with A* algorithm implementations, which further enhanced the LLMs' performance.
The researchers' proposed Multi-Stage-Multi-Try method, which breaks down the algorithm implementation into two stages and verifies the first stage against unit tests, proved to be the most effective approach. This method, combined with the in-context learning of the A* algorithm, raised GPT-4's performance above 57%.
The SearchBench benchmark and the insights gained from this research contribute to the ongoing efforts to understand the limitations of LLMs and develop more effective evaluators for structured reasoning capabilities.
Critical Analysis
The paper provides valuable insights into the limitations of current large language models (LLMs) in solving complex search problems that require strategic thinking and the consideration of multiple solution pathways. The introduction of the SearchBench benchmark is a significant contribution, as it offers a structured way to evaluate the reasoning capabilities of LLMs.
One potential limitation of the research is the scope of the benchmark, as it focuses primarily on search problems. While this is an essential aspect of problem-solving, it may not capture the full breadth of reasoning skills required in real-world scenarios. Expanding the benchmark to include a wider range of problem types, such as mathematical reasoning or strategic decision-making, could provide a more comprehensive assessment of LLM capabilities.
Additionally, the paper could have explored the performance of LLMs on structured graph reasoning tasks, as these types of problems often involve similar cognitive processes to the search problems presented in the benchmark.
Overall, the research presented in this paper is a valuable contribution to the ongoing efforts to understand the limitations of LLMs and develop more effective ways to evaluate their reasoning capabilities. The SearchBench benchmark and the insights gained from this study can help drive the development of more advanced language models that can better tackle complex problem-solving tasks.
Conclusion
The paper's introduction of the SearchBench benchmark and the insights it provides into the limitations of current large language models (LLMs) in solving complex search problems are significant contributions to the field of natural language processing and artificial intelligence.
The research demonstrates that even the most advanced LLMs, like GPT-4, struggle to solve these types of problems when asked to provide the solution in text form. By exploring alternative approaches, such as instructing the LLMs to generate code and using in-context learning with A* algorithm implementations, the authors were able to significantly improve the performance of these models.
The SearchBench benchmark and the findings of this study underscore the need for continued research and development in the area of structured reasoning and strategic problem-solving capabilities in LLMs. As these models become more integrated into our daily lives and decision-making processes, it is crucial that we understand their limitations and work to address them.
The insights gained from this paper can inform the design of future language models and contribute to the broader efforts to create more intelligent and capable artificial intelligence systems that can tackle complex, competition-level problems with ease.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Puzzle Solving using Reasoning of Large Language Models: A Survey
Panagiotis Giadikiaroglou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
0
0
Exploring the capabilities of Large Language Models (LLMs) in puzzle solving unveils critical insights into their potential and challenges in AI, marking a significant step towards understanding their applicability in complex reasoning tasks. This survey leverages a unique taxonomy -- dividing puzzles into rule-based and rule-less categories -- to critically assess LLMs through various methodologies, including prompting techniques, neuro-symbolic approaches, and fine-tuning. Through a critical review of relevant datasets and benchmarks, we assess LLMs' performance, identifying significant challenges in complex puzzle scenarios. Our findings highlight the disparity between LLM capabilities and human-like reasoning, particularly in those requiring advanced logical inference. The survey underscores the necessity for novel strategies and richer datasets to advance LLMs' puzzle-solving proficiency and contribute to AI's logical reasoning and creative problem-solving advancements.
4/23/2024

LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs
Arash Gholami Davoodi, Seyed Pouyan Mousavi Davoudi, Pouya Pezeshkpour
0
0
Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that the most advanced model, GPT-4, achieved a mere 54% accuracy in a multiple-choice scenario. Interestingly, even when employing Chain-of-Thought prompting, we observe mostly no notable improvement. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. Further detailed analysis of the LLMs' performance across a range of topics showed significant discrepancy even for closely related subtopics within the same general mathematical area. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
6/11/2024
📉
Competition-Level Problems are Effective LLM Evaluators
Yiming Huang, Zhenghao Lin, Xiao Liu, Yeyun Gong, Shuai Lu, Fangyu Lei, Yaobo Liang, Yelong Shen, Chen Lin, Nan Duan, Weizhu Chen
0
0
Large language models (LLMs) have demonstrated impressive reasoning capabilities, yet there is ongoing debate about these abilities and the potential data contamination problem recently. This paper aims to evaluate the reasoning capacities of LLMs, specifically in solving recent competition-level programming problems in Codeforces, which are expert-crafted and unique, requiring deep understanding and robust reasoning skills. We first provide a comprehensive evaluation of GPT-4's peiceived zero-shot performance on this task, considering various aspects such as problems' release time, difficulties, and types of errors encountered. Surprisingly, the peiceived performance of GPT-4 has experienced a cliff like decline in problems after September 2021 consistently across all the difficulties and types of problems, which shows the potential data contamination, as well as the challenges for any existing LLM to solve unseen complex reasoning problems. We further explore various approaches such as fine-tuning, Chain-of-Thought prompting and problem description simplification, unfortunately none of them is able to consistently mitigate the challenges. Through our work, we emphasis the importance of this excellent data source for assessing the genuine reasoning capabilities of LLMs, and foster the development of LLMs with stronger reasoning abilities and better generalization in the future.
6/5/2024
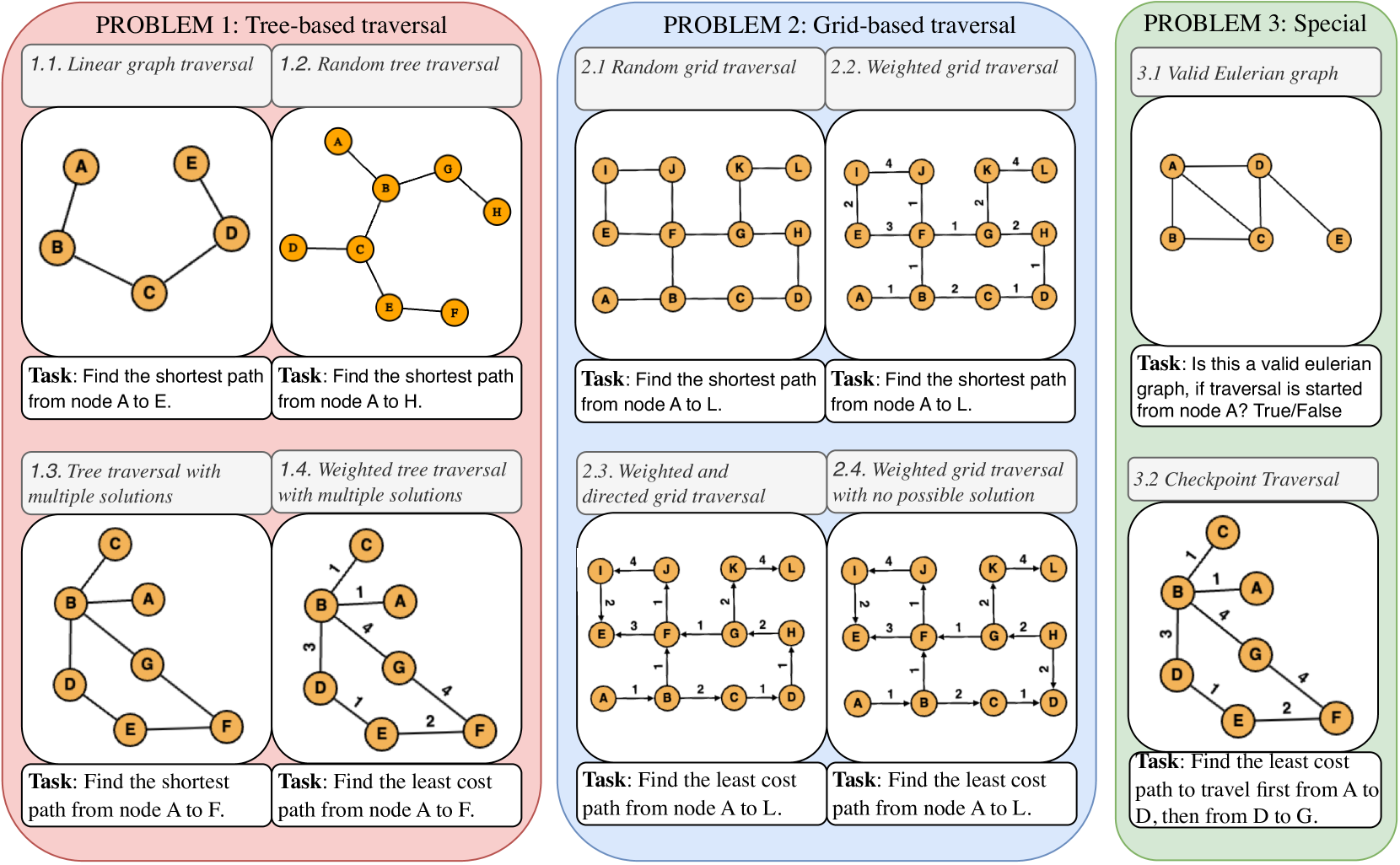
Can LLMs perform structured graph reasoning?
Palaash Agrawal, Shavak Vasania, Cheston Tan
0
0
Pretrained Large Language Models (LLMs) have demonstrated various reasoning capabilities through language-based prompts alone, particularly in unstructured task settings (tasks purely based on language semantics). However, LLMs often struggle with structured tasks, because of the inherent incompatibility of input representation. Reducing structured tasks to uni-dimensional language semantics often renders the problem trivial. Keeping the trade-off between LLM compatibility and structure complexity in mind, we design various graph reasoning tasks as a proxy to semi-structured tasks in this paper, in order to test the ability to navigate through representations beyond plain text in various LLMs. Particularly, we design 10 distinct problems of graph traversal, each representing increasing levels of complexity, and benchmark 5 different instruct-finetuned LLMs (GPT-4, GPT-3.5, Claude-2, Llama-2 and Palm-2) on the aforementioned tasks. Further, we analyse the performance of models across various settings such as varying sizes of graphs as well as different forms of k-shot prompting. We highlight various limitations, biases and properties of LLMs through this benchmarking process, such as an inverse relation to the average degrees of freedom of traversal per node in graphs, the overall negative impact of k-shot prompting on graph reasoning tasks, and a positive response bias which prevents LLMs from identifying the absence of a valid solution. Finally, we introduce a new prompting technique specially designed for graph traversal tasks (PathCompare), which demonstrates a notable increase in the performance of LLMs in comparison to standard prompting techniques such as Chain-of-Thought (CoT).
4/19/2024