LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs

0

Sign in to get full access
Overview
- The paper argues that large language models (LLMs) are not true "intelligent thinkers" and introduces a new benchmark called the Mathematical Topics Tree (MATT) to comprehensively evaluate the reasoning abilities of LLMs.
- The MATT benchmark is designed to assess LLMs' understanding of a wide range of mathematical topics, from basic arithmetic to advanced concepts like topology and number theory.
- The authors claim that existing benchmarks for evaluating LLMs often focus on narrow or superficial tasks, and fail to capture the depth and breadth of mathematical reasoning required for true intelligence.
Plain English Explanation
The researchers behind this paper believe that current AI systems, specifically large language models (LLMs), are not actually intelligent in the way that humans are. To demonstrate this, they have created a new test called the Mathematical Topics Tree (MATT) that challenges LLMs to show their understanding of a wide range of mathematical concepts, from simple arithmetic to complex areas like topology and number theory.
The key idea is that true intelligence requires the ability to reason deeply about abstract topics, not just perform well on narrow, superficial tasks. Existing benchmarks for evaluating LLMs often focus on things like answering trivia questions or completing sentence completion exercises, which the researchers argue don't capture the full scope of human-level mathematical reasoning.
By testing LLMs on a diverse set of mathematical topics organized into a structured "topic tree," the MATT benchmark aims to provide a more comprehensive assessment of their capabilities. The researchers believe that if LLMs struggle with the MATT test, it would suggest that they are not truly intelligent thinkers, but rather highly capable pattern matchers that excel at specific tasks without deeper understanding.
Technical Explanation
The paper introduces the Mathematical Topics Tree (MATT) benchmark to comprehensively evaluate the mathematical reasoning abilities of large language models (LLMs). The MATT benchmark is structured as a hierarchical tree of mathematical topics, covering a wide range of concepts from basic arithmetic to advanced areas like topology and number theory.
The authors argue that existing benchmarks for evaluating LLMs, such as GradeSchoolMath, LogicBench, and GradeSchoolBench, often focus on narrow or superficial tasks that do not capture the depth and breadth of mathematical reasoning required for true intelligence. In contrast, the MATT benchmark is designed to assess LLMs' understanding of a diverse set of mathematical topics in a more structured and comprehensive manner.
The paper describes the process of constructing the MATT benchmark, including the selection of mathematical topics, the creation of a hierarchical topic tree, and the generation of evaluation tasks for each topic. The authors also discuss the use of techniques like few-shot learning and prompt engineering to assess LLMs' performance on the MATT benchmark.
Critical Analysis
The paper raises valid concerns about the limitations of existing benchmarks for evaluating the mathematical reasoning abilities of large language models (LLMs). The authors make a compelling argument that these models may excel at narrow, superficial tasks without truly understanding the underlying mathematical concepts.
One potential limitation of the MATT benchmark is the challenge of creating a comprehensive and representative set of evaluation tasks for each mathematical topic. While the hierarchical topic tree structure is a step in the right direction, there may be inherent biases or gaps in the coverage of mathematical concepts that could affect the validity of the results.
Additionally, the paper does not address the potential impact of model architecture, training data, and other factors on LLMs' performance on the MATT benchmark. It would be valuable to explore how different LLM approaches and design choices might affect their ability to reason about mathematical concepts.
Despite these potential concerns, the MATT benchmark represents a significant step forward in the quest to develop more comprehensive and meaningful evaluations of AI systems' reasoning abilities. The authors' emphasis on assessing the depth and breadth of mathematical understanding, rather than just surface-level performance, is a crucial consideration for the field of AI as it continues to grapple with the question of what it means to be truly intelligent.
Conclusion
This paper introduces the Mathematical Topics Tree (MATT) benchmark as a novel approach to evaluating the mathematical reasoning capabilities of large language models (LLMs). The authors argue that existing benchmarks often fail to capture the depth and breadth of mathematical understanding required for true intelligence, and they propose the MATT benchmark as a more comprehensive and structured way to assess LLMs' abilities.
The MATT benchmark's focus on a wide range of mathematical topics, from basic arithmetic to advanced concepts, represents a significant advancement in the field of AI evaluation. By challenging LLMs to demonstrate their understanding of these topics in a more systematic manner, the MATT benchmark has the potential to shed light on the limitations of current AI systems and drive the development of more robust and intelligent models in the future.
As the field of AI continues to evolve, the insights and approaches presented in this paper will likely become increasingly important for researchers and practitioners alike, as they strive to create AI systems that can truly think and reason like humans, rather than just excel at narrow, superficial tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs
Arash Gholami Davoodi, Seyed Pouyan Mousavi Davoudi, Pouya Pezeshkpour
Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that the most advanced model, GPT-4, achieved a mere 54% accuracy in a multiple-choice scenario. Interestingly, even when employing Chain-of-Thought prompting, we observe mostly no notable improvement. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. Further detailed analysis of the LLMs' performance across a range of topics showed significant discrepancy even for closely related subtopics within the same general mathematical area. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
Read more6/11/2024

0
Benchmarking Large Language Models for Math Reasoning Tasks
Kathrin Se{ss}ler, Yao Rong, Emek Gozluklu, Enkelejda Kasneci
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.
Read more8/21/2024
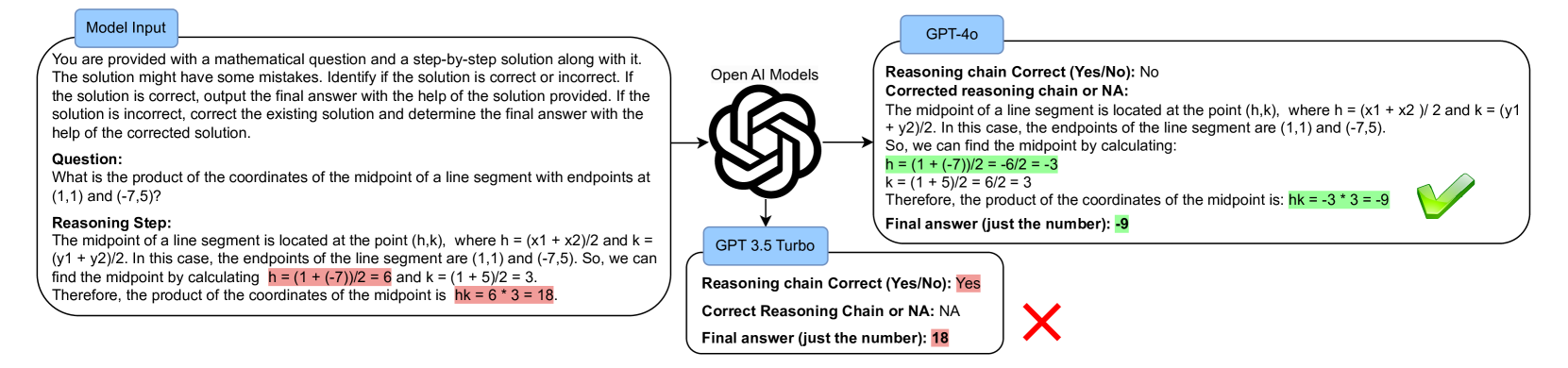
0
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
Read more6/18/2024

0
Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
Read more6/28/2024