Navigating the Minefield of MT Beam Search in Cascaded Streaming Speech Translation

0
🗣️
Sign in to get full access
Overview
- This paper explores the challenges of using beam search, a commonly used technique in machine translation (MT), in the context of cascaded streaming speech translation systems.
- The authors investigate how beam search can introduce issues like translation errors and latency, and propose strategies to address these problems.
- The paper provides insights into the trade-offs between translation quality and latency in real-time speech translation systems.
Plain English Explanation
Machine translation (MT) is the process of automatically translating text from one language to another. One of the key techniques used in MT is called "beam search," which helps the system choose the most likely translation by considering multiple possibilities simultaneously.
However, when using beam search in the context of cascaded streaming speech translation systems, where audio is translated to text in real-time, the authors of this paper found that it can introduce some challenges. Specifically, they discovered that beam search can lead to translation errors and increased latency (delay) in the translation process.
To address these issues, the authors propose several strategies, such as blending large language models into the translation pipeline and using probabilistically sound beam search approaches. These techniques aim to improve the accuracy and speed of the translation, while maintaining the real-time nature of the system.
The insights from this research can help developers of end-to-end speech translation systems navigate the trade-offs between translation quality and latency, and build more robust and efficient real-time translation solutions.
Technical Explanation
The paper examines the use of beam search, a common technique in machine translation (MT), in the context of cascaded streaming speech translation systems. Beam search is a heuristic search algorithm that considers multiple translation hypotheses simultaneously, selecting the most likely one.
The authors found that while beam search is effective in traditional MT, it can introduce challenges in the cascaded streaming speech translation setting. Specifically, the paper shows that beam search can lead to translation errors and increased latency, which are critical issues for real-time speech translation systems.
To address these problems, the authors propose several strategies:
-
Blending large language models (LLMs) into the translation pipeline: The authors explore incorporating LLMs, which have shown strong performance in natural language tasks, to improve the accuracy and fluency of the translations.
-
Using probabilistically sound beam search approaches: The paper investigates more principled beam search methods that consider the uncertainty of the translation process, aiming to reduce errors and latency.
-
Leveraging uncertainty-guided optimization for large language model search: The authors explore techniques to efficiently search and select the most appropriate LLMs for the speech translation task, taking into account the trade-offs between translation quality and latency.
-
Developing segmentation-free streaming machine translation: The paper explores methods to perform translation on the audio stream without relying on explicit segmentation, which can introduce additional latency.
Through these approaches, the authors aim to navigate the "minefield" of beam search in cascaded streaming speech translation, improving the overall performance and real-time capabilities of these systems.
Critical Analysis
The paper provides a thorough analysis of the challenges associated with using beam search in cascaded streaming speech translation systems. The authors acknowledge the inherent trade-offs between translation quality and latency, and their proposed strategies aim to address these issues.
One potential limitation of the research is the lack of extensive real-world evaluation of the proposed techniques. While the paper presents promising results, further testing in diverse real-time scenarios would help validate the effectiveness of the approaches and provide a more comprehensive understanding of their practical implications.
Additionally, the paper does not delve deeply into the computational and resource requirements of the proposed solutions, such as the increased model complexity or processing power needed for the LLM-based approaches. These practical considerations may be important for developers in resource-constrained environments.
Another area for further exploration could be the impact of different language pairs and domains on the performance of the cascaded streaming speech translation system. The paper focuses on a specific use case, and it would be valuable to understand how the findings and proposed solutions scale to a broader range of languages and applications.
Overall, the paper offers valuable insights and strategies for navigating the challenges of beam search in real-time speech translation systems. The authors' dedication to addressing these issues is commendable, and their work provides a solid foundation for future research and development in this important field.
Conclusion
This paper delves into the complexities of using beam search, a widely adopted technique in machine translation, in the context of cascaded streaming speech translation systems. The authors' findings highlight the challenges that beam search can introduce, such as translation errors and increased latency, which are critical issues for real-time speech translation.
To address these problems, the paper presents several innovative strategies, including blending large language models into the translation pipeline, using probabilistically sound beam search approaches, leveraging uncertainty-guided optimization for LLM selection, and developing segmentation-free streaming machine translation. These techniques aim to strike a better balance between translation quality and latency, ultimately improving the overall performance and real-time capabilities of cascaded streaming speech translation systems.
The insights from this research can help developers and researchers in the field of speech translation navigate the trade-offs and build more robust and efficient real-time translation solutions. By addressing the "minefield" of beam search, the authors have made a valuable contribution to advancing the state of the art in this important and rapidly evolving area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Navigating the Minefield of MT Beam Search in Cascaded Streaming Speech Translation
Rastislav Rabatin, Frank Seide, Ernie Chang
We adapt the well-known beam-search algorithm for machine translation to operate in a cascaded real-time speech translation system. This proved to be more complex than initially anticipated, due to four key challenges: (1) real-time processing of intermediate and final transcriptions with incomplete words from ASR, (2) emitting intermediate and final translations with minimal user perceived latency, (3) handling beam search hypotheses that have unequal length and different model state, and (4) handling sentence boundaries. Previous work in the field of simultaneous machine translation only implemented greedy decoding. We present a beam-search realization that handles all of the above, providing guidance through the minefield of challenges. Our approach increases the BLEU score by 1 point compared to greedy search, reduces the CPU time by up to 40% and character flicker rate by 20+% compared to a baseline heuristic that just retranslates input repeatedly.
Read more7/17/2024

0
Enabling Beam Search for Language Model-Based Text-to-Speech Synthesis
Zehai Tu, Guangyan Zhang, Yiting Lu, Adaeze Adigwe, Simon King, Yiwen Guo
Tokenising continuous speech into sequences of discrete tokens and modelling them with language models (LMs) has led to significant success in text-to-speech (TTS) synthesis. Although these models can generate speech with high quality and naturalness, their synthesised samples can still suffer from artefacts, mispronunciation, word repeating, etc. In this paper, we argue these undesirable properties could partly be caused by the randomness of sampling-based strategies during the autoregressive decoding of LMs. Therefore, we look at maximisation-based decoding approaches and propose Temporal Repetition Aware Diverse Beam Search (TRAD-BS) to find the most probable sequences of the generated speech tokens. Experiments with two state-of-the-art LM-based TTS models demonstrate that our proposed maximisation-based decoding strategy generates speech with fewer mispronunciations and improved speaker consistency.
Read more8/30/2024
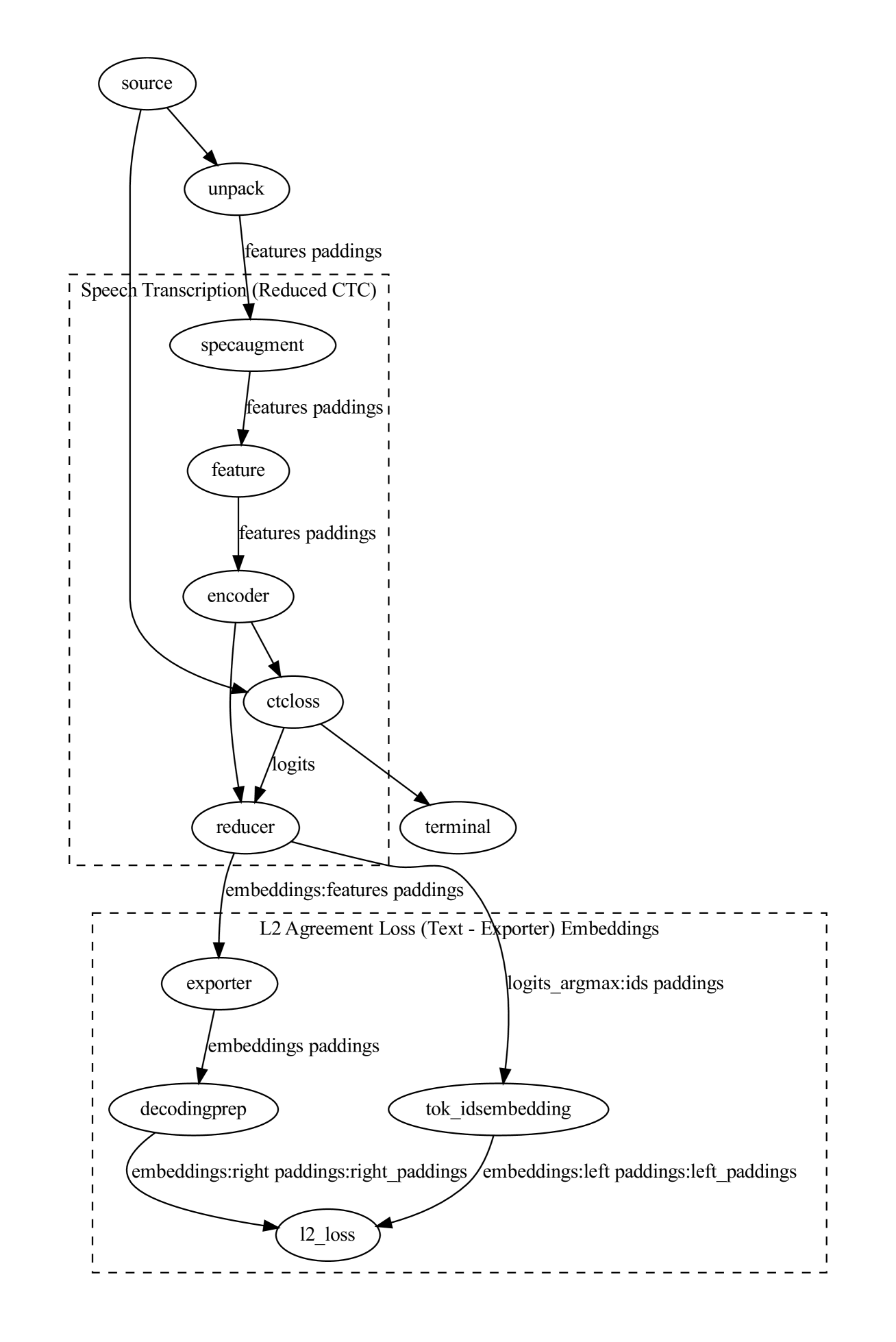
0
Coupling Speech Encoders with Downstream Text Models
Ciprian Chelba, Johan Schalkwyk
We present a modular approach to building cascade speech translation (AST) models that guarantees that the resulting model performs no worse than the 1-best cascade baseline while preserving state-of-the-art speech recognition (ASR) and text translation (MT) performance for a given task. Our novel contribution is the use of an ``exporter'' layer that is trained under L2-loss to ensure a strong match between ASR embeddings and the MT token embeddings for the 1-best sequence. The ``exporter'' output embeddings are fed directly to the MT model in lieu of 1-best token embeddings, thus guaranteeing that the resulting model performs no worse than the 1-best cascade baseline, while allowing back-propagation gradient to flow from the MT model into the ASR components. The matched-embeddings cascade architecture provide a significant improvement over its 1-best counterpart in scenarios where incremental training of the MT model is not an option and yet we seek to improve quality by leveraging (speech, transcription, translated transcription) data provided with the AST task. The gain disappears when the MT model is incrementally trained on the parallel text data available with the AST task. The approach holds promise for other scenarios that seek to couple ASR encoders and immutable text models, such at large language models (LLM).
Read more7/26/2024
0
Uncertainty-Guided Optimization on Large Language Model Search Trees
Julia Grosse, Ruotian Wu, Ahmad Rashid, Philipp Hennig, Pascal Poupart, Agustinus Kristiadi
Beam search is a standard tree search algorithm when it comes to finding sequences of maximum likelihood, for example, in the decoding processes of large language models. However, it is myopic since it does not take the whole path from the root to a leaf into account. Moreover, it is agnostic to prior knowledge available about the process: For example, it does not consider that the objective being maximized is a likelihood and thereby has specific properties, like being bound in the unit interval. Taking a probabilistic approach, we define a prior belief over the LLMs' transition probabilities and obtain a posterior belief over the most promising paths in each iteration. These beliefs are helpful to define a non-myopic Bayesian-optimization-like acquisition function that allows for a more data-efficient exploration scheme than standard beam search. We discuss how to select the prior and demonstrate in on- and off-model experiments with recent large language models, including Llama-2-7b, that our method achieves higher efficiency than beam search: Our method achieves the same or a higher likelihood while expanding fewer nodes than beam search.
Read more7/8/2024