Enabling Beam Search for Language Model-Based Text-to-Speech Synthesis

0

Sign in to get full access
Overview
- This paper explores enabling beam search for language model-based text-to-speech (TTS) synthesis.
- Beam search is a widely used algorithm in natural language processing, but it has not been commonly applied to TTS systems.
- The authors propose a method to integrate beam search into language model-based TTS, which can lead to improved speech quality.
Plain English Explanation
The paper discusses a technique called beam search for text-to-speech (TTS) synthesis. Beam search is a common algorithm used in many natural language processing tasks, but it has not been widely used in TTS systems before.
The authors propose a way to integrate beam search into language model-based TTS. This could potentially lead to better quality synthetic speech compared to existing TTS methods. The key idea is to use beam search to explore multiple possible output sequences during the synthesis process, rather than just choosing the single most likely sequence.
By considering a broader set of possibilities, the system may be able to generate more natural-sounding and coherent speech. This could be particularly useful for improving the robustness of large language model-based speech synthesis to handle a wider range of input text.
Technical Explanation
The paper presents a method for enabling beam search in language model-based text-to-speech (TTS) synthesis. Traditionally, TTS systems have relied on greedy decoding approaches that only consider the single most likely output sequence.
The authors propose integrating beam search, a widely used algorithm in natural language processing, into the TTS pipeline. Beam search explores multiple possible output sequences in parallel, allowing the system to consider a broader set of alternatives during synthesis.
The key technical contributions include:
- Modifying the TTS architecture to support beam search decoding
- Designing a beam search algorithm tailored for language model-based TTS
- Evaluating the proposed approach on benchmark TTS datasets
The authors demonstrate that enabling beam search can lead to improved speech quality compared to greedy decoding, as measured by both objective and subjective metrics. This suggests that the broader exploration of output sequences facilitated by beam search can be beneficial for enhancing the robustness of large language model-based speech synthesis.
Critical Analysis
The paper presents a promising approach for improving text-to-speech synthesis by leveraging beam search, a powerful algorithm commonly used in other natural language tasks. The authors provide a thorough technical explanation and evaluation of their proposed method.
However, the paper does not address some potential limitations or areas for further research. For example, the impact of beam search on the computational efficiency and latency of the TTS system is not discussed. Larger beam sizes may improve quality but could also significantly increase inference time, which is an important consideration for real-world TTS applications.
Additionally, the paper focuses on evaluating the approach on standard TTS benchmarks, but does not explore its performance on more diverse or challenging input text, such as phonetically-enhanced language modeling for TTS. Further research could investigate the robustness of the beam search-enabled TTS system to a broader range of input characteristics.
Conclusion
This paper presents a novel method for enabling beam search in language model-based text-to-speech synthesis. The authors demonstrate that incorporating beam search can lead to improved speech quality compared to traditional greedy decoding approaches.
The proposed technique has the potential to enhance the robustness of large language model-based speech synthesis by considering a broader set of possible output sequences during the synthesis process. Further research could explore the practical implications and limitations of this approach, such as its impact on computational efficiency and performance on more diverse input data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enabling Beam Search for Language Model-Based Text-to-Speech Synthesis
Zehai Tu, Guangyan Zhang, Yiting Lu, Adaeze Adigwe, Simon King, Yiwen Guo
Tokenising continuous speech into sequences of discrete tokens and modelling them with language models (LMs) has led to significant success in text-to-speech (TTS) synthesis. Although these models can generate speech with high quality and naturalness, their synthesised samples can still suffer from artefacts, mispronunciation, word repeating, etc. In this paper, we argue these undesirable properties could partly be caused by the randomness of sampling-based strategies during the autoregressive decoding of LMs. Therefore, we look at maximisation-based decoding approaches and propose Temporal Repetition Aware Diverse Beam Search (TRAD-BS) to find the most probable sequences of the generated speech tokens. Experiments with two state-of-the-art LM-based TTS models demonstrate that our proposed maximisation-based decoding strategy generates speech with fewer mispronunciations and improved speaker consistency.
Read more8/30/2024
0
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
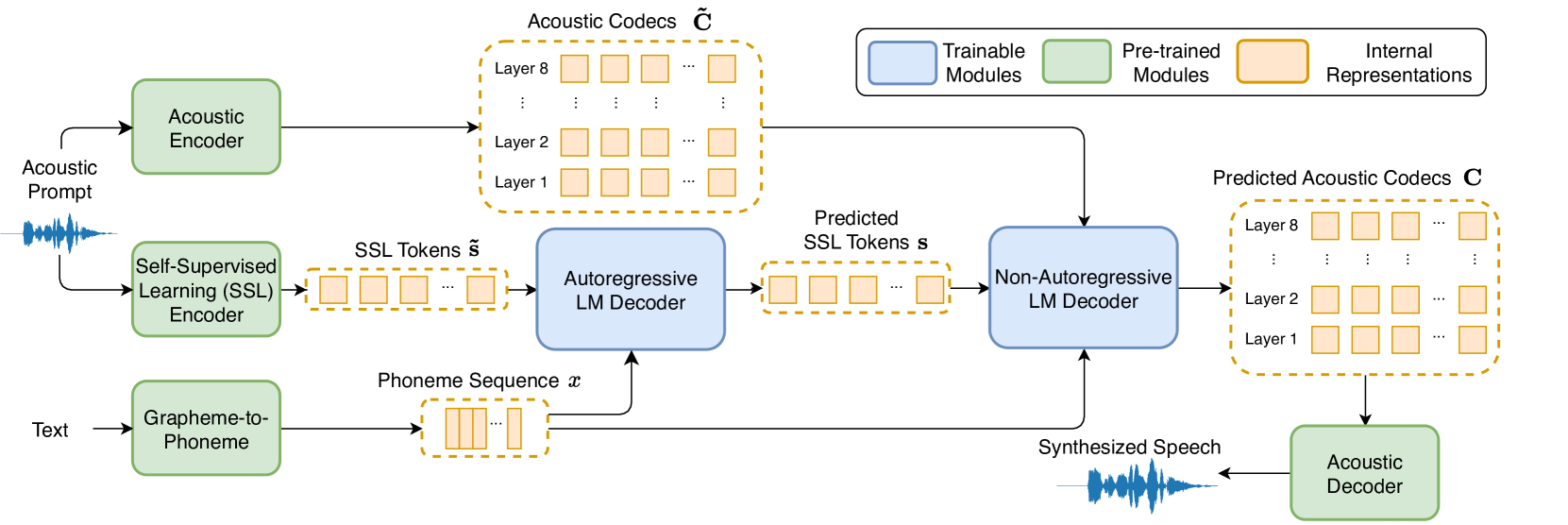
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Read more6/13/2024
0
Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
Siyang Wang, 'Eva Sz'ekely
Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.
Read more5/17/2024
0
Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment
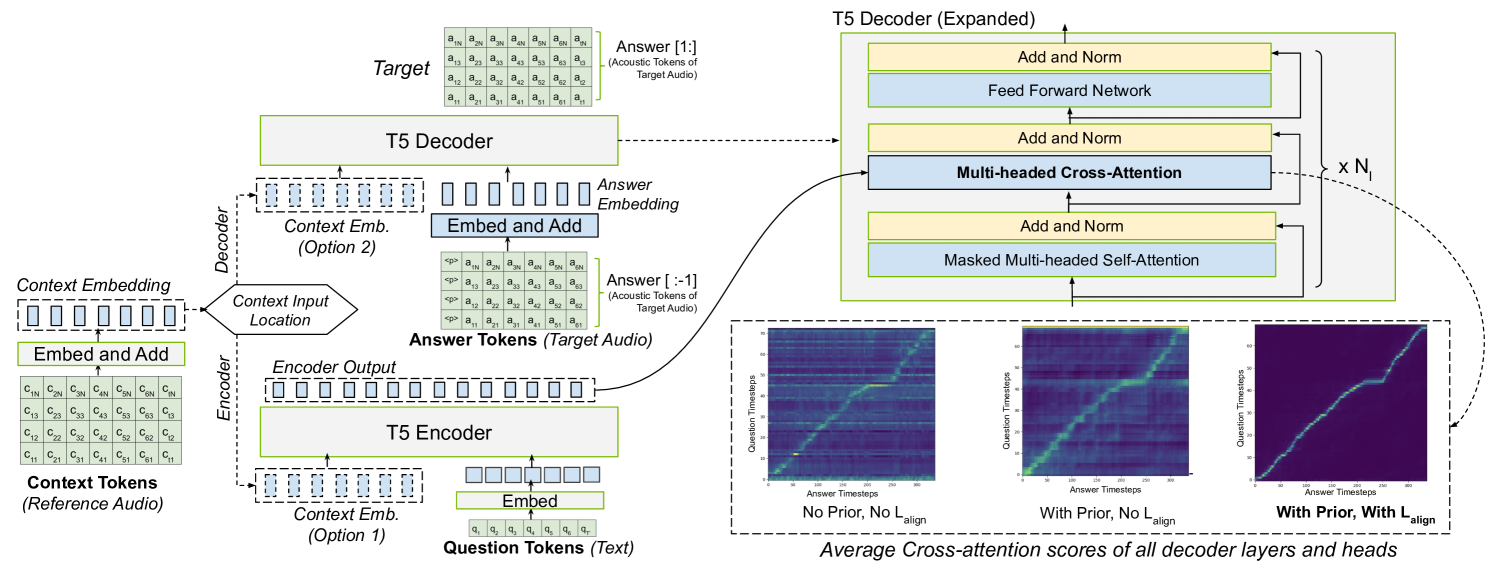
Paarth Neekhara, Shehzeen Hussain, Subhankar Ghosh, Jason Li, Rafael Valle, Rohan Badlani, Boris Ginsburg
Large Language Model (LLM) based text-to-speech (TTS) systems have demonstrated remarkable capabilities in handling large speech datasets and generating natural speech for new speakers. However, LLM-based TTS models are not robust as the generated output can contain repeating words, missing words and mis-aligned speech (referred to as hallucinations or attention errors), especially when the text contains multiple occurrences of the same token. We examine these challenges in an encoder-decoder transformer model and find that certain cross-attention heads in such models implicitly learn the text and speech alignment when trained for predicting speech tokens for a given text. To make the alignment more robust, we propose techniques utilizing CTC loss and attention priors that encourage monotonic cross-attention over the text tokens. Our guided attention training technique does not introduce any new learnable parameters and significantly improves robustness of LLM-based TTS models.
Read more6/27/2024