The Need for Guardrails with Large Language Models in Medical Safety-Critical Settings: An Artificial Intelligence Application in the Pharmacovigilance Ecosystem

0

Sign in to get full access
Overview
- Large language models (LLMs) have become widely used in various applications, including medical and safety-critical settings
- However, the potential risks and challenges of deploying LLMs in these sensitive domains have raised concerns
- This paper explores the need for implementing "guardrails" or safety measures to mitigate the risks associated with using LLMs in medical pharmacovigilance applications
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. They have been adopted in many industries, including healthcare. However, using LLMs in sensitive medical settings, such as pharmacovigilance, can be risky. Pharmacovigilance involves monitoring and reporting adverse drug reactions to ensure patient safety.
The paper argues that we need to put "guardrails" in place when using LLMs in medical safety-critical applications. Guardrails are safeguards that help prevent mistakes or unintended consequences. Without these guardrails, LLMs could make dangerous errors that could harm patients.
The paper explores how LLMs can be used in the pharmacovigilance ecosystem to automate tasks like identifying and summarizing adverse drug reactions from medical reports. However, the authors caution that LLMs must be carefully monitored and constrained to avoid issues like generating inaccurate or biased information that could lead to patient harm.
Technical Explanation
The paper discusses the application of large language models (LLMs) in the context of medical safety-critical settings, specifically the pharmacovigilance ecosystem. Pharmacovigilance involves the monitoring and reporting of adverse drug reactions to ensure patient safety.
The authors highlight the potential for LLMs to be leveraged in automating various tasks within the pharmacovigilance process, such as identifying and summarizing adverse drug reactions from medical reports. However, they emphasize the critical need for implementing "guardrails" or safety measures to mitigate the risks associated with using LLMs in these sensitive domains.
The paper outlines several key concerns regarding the deployment of LLMs in medical safety-critical settings, including the potential for generating inaccurate or biased information, the difficulty in ensuring the reliability and verifiability of LLM outputs, and the challenges in maintaining human oversight and accountability. The authors argue that without the proper safeguards in place, the use of LLMs in medical applications could lead to patient harm.
The paper proposes a framework for deploying LLMs in the pharmacovigilance ecosystem, which involves the integration of various safety measures and monitoring mechanisms. These include technical approaches, such as prompting strategies, output filtering, and human-in-the-loop processes, as well as organizational and governance measures to ensure the responsible and ethical use of these technologies.
Critical Analysis
The paper raises important concerns about the potential risks of using large language models (LLMs) in medical safety-critical settings, such as pharmacovigilance. The authors' emphasis on the need for "guardrails" or safety measures is well-justified, as the consequences of errors or biases in LLM outputs could be severe and potentially life-threatening for patients.
One limitation of the paper is that it does not provide a detailed technical implementation of the proposed safeguards. While the authors discuss the general principles and approaches, more specific details on the design and evaluation of these guardrails would be helpful for researchers and practitioners looking to implement such systems.
Additionally, the paper could have delved deeper into the potential challenges and trade-offs involved in balancing the benefits of LLM-powered automation with the need for robust safety measures. For instance, the authors could have explored the potential impact of these guardrails on the performance and efficiency of the pharmacovigilance process, or the challenges in maintaining the appropriate balance between human oversight and machine automation.
Overall, the paper makes a strong case for the importance of developing and deploying safeguards when using LLMs in medical safety-critical settings. The authors' call for a comprehensive approach to mitigating risks is a valuable contribution to the ongoing discussions around the responsible and ethical use of these powerful AI technologies.
Conclusion
This paper highlights the critical need for implementing "guardrails" or safety measures when using large language models (LLMs) in medical safety-critical settings, such as pharmacovigilance. While LLMs offer the potential to automate various tasks and improve efficiency, the authors argue that the risks of using these models in sensitive domains, where errors could lead to patient harm, must be carefully addressed.
The paper outlines the key concerns surrounding the deployment of LLMs in medical applications, including the potential for generating inaccurate or biased information, and the challenges in ensuring the reliability and verifiability of LLM outputs. The authors propose a framework for integrating safety measures and monitoring mechanisms to mitigate these risks, emphasizing the importance of a comprehensive approach that combines technical, organizational, and governance-based safeguards.
The critical analysis highlights the need for more detailed technical implementation details and a deeper exploration of the trade-offs involved in balancing the benefits of LLM-powered automation with the imperative for robust safety measures. Nevertheless, the paper's central argument for the necessity of "guardrails" when using LLMs in medical safety-critical settings is a valuable contribution to the ongoing discussions around the responsible development and deployment of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Need for Guardrails with Large Language Models in Medical Safety-Critical Settings: An Artificial Intelligence Application in the Pharmacovigilance Ecosystem
Joe B Hakim, Jeffery L Painter, Darmendra Ramcharran, Vijay Kara, Greg Powell, Paulina Sobczak, Chiho Sato, Andrew Bate, Andrew Beam
Large language models (LLMs) are useful tools with the capacity for performing specific types of knowledge work at an effective scale. However, LLM deployments in high-risk and safety-critical domains pose unique challenges, notably the issue of ``hallucination,'' where LLMs can generate fabricated information. This is particularly concerning in settings such as drug safety, where inaccuracies could lead to patient harm. To mitigate these risks, we have developed and demonstrated a proof of concept suite of guardrails specifically designed to mitigate certain types of hallucinations and errors for drug safety, and potentially applicable to other medical safety-critical contexts. These guardrails include mechanisms to detect anomalous documents to prevent the ingestion of inappropriate data, identify incorrect drug names or adverse event terms, and convey uncertainty in generated content. We integrated these guardrails with an LLM fine-tuned for a text-to-text task, which involves converting both structured and unstructured data within adverse event reports into natural language. This method was applied to translate individual case safety reports, demonstrating effective application in a pharmacovigilance processing task. Our guardrail framework offers a set of tools with broad applicability across various domains, ensuring LLMs can be safely used in high-risk situations by eliminating the occurrence of key errors, including the generation of incorrect pharmacovigilance-related terms, thus adhering to stringent regulatory and quality standards in medical safety-critical environments.
Read more9/5/2024
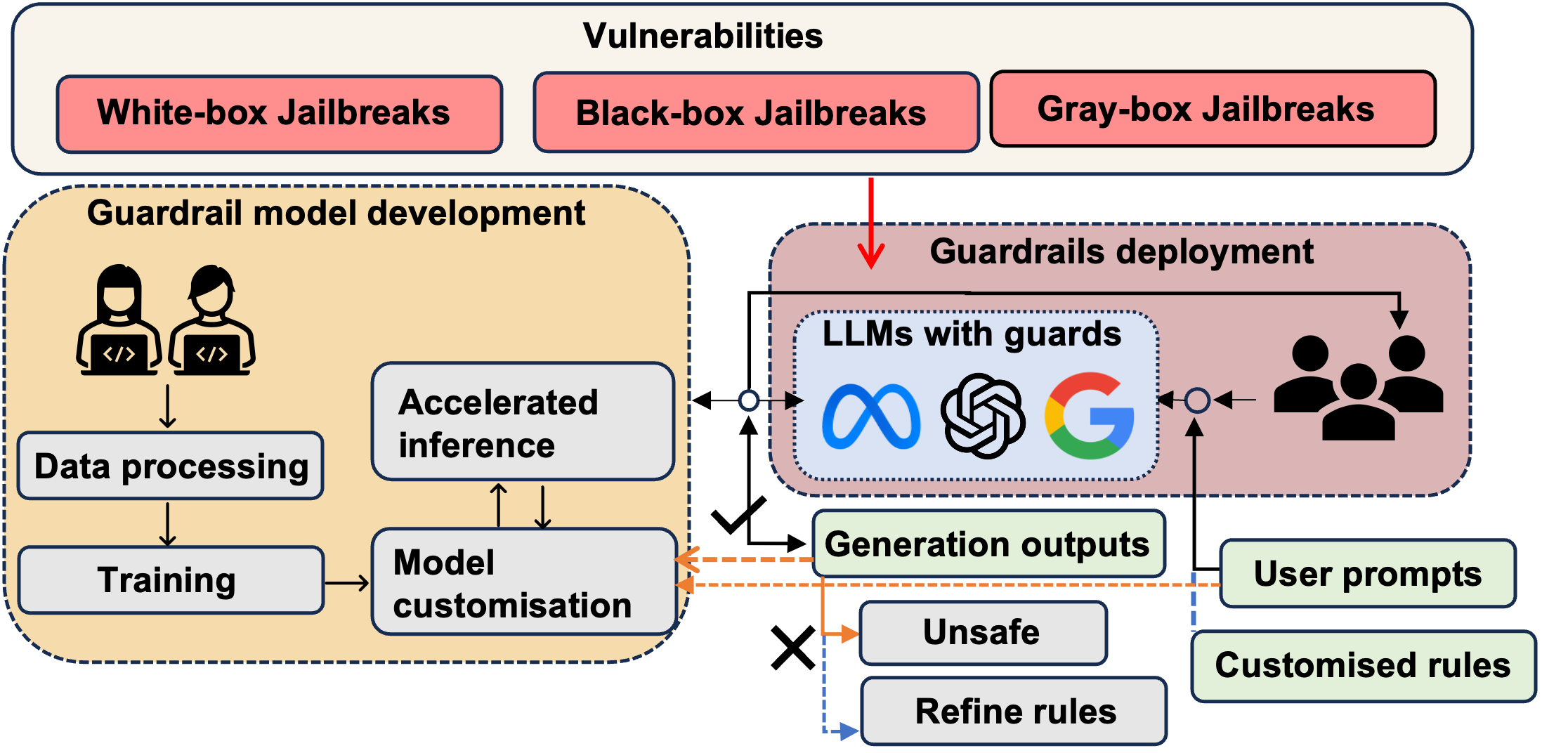
0
Safeguarding Large Language Models: A Survey
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, Saddek Bensalem, Xiaowei Huang
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as safeguards or guardrails, has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
Read more6/6/2024
🤖
0
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
Read more6/21/2024

0
Building Guardrails for Large Language Models
Yi Dong, Ronghui Mu, Gaojie Jin, Yi Qi, Jinwei Hu, Xingyu Zhao, Jie Meng, Wenjie Ruan, Xiaowei Huang
As Large Language Models (LLMs) become more integrated into our daily lives, it is crucial to identify and mitigate their risks, especially when the risks can have profound impacts on human users and societies. Guardrails, which filter the inputs or outputs of LLMs, have emerged as a core safeguarding technology. This position paper takes a deep look at current open-source solutions (Llama Guard, Nvidia NeMo, Guardrails AI), and discusses the challenges and the road towards building more complete solutions. Drawing on robust evidence from previous research, we advocate for a systematic approach to construct guardrails for LLMs, based on comprehensive consideration of diverse contexts across various LLMs applications. We propose employing socio-technical methods through collaboration with a multi-disciplinary team to pinpoint precise technical requirements, exploring advanced neural-symbolic implementations to embrace the complexity of the requirements, and developing verification and testing to ensure the utmost quality of the final product.
Read more5/30/2024