Negation Triplet Extraction with Syntactic Dependency and Semantic Consistency

0

Sign in to get full access
Overview
- This research paper discusses a method for extracting negation triplets from text, which involves identifying negation words, the entities they modify, and the relationships between them.
- The proposed approach leverages syntactic dependency and semantic consistency to improve the accuracy and completeness of negation triplet extraction.
- The authors evaluate their method on various datasets and compare its performance to existing information extraction techniques.
Plain English Explanation
The paper describes a way to automatically identify and extract negative statements from text. Negative statements are those that deny or contradict something, such as "The patient does not have a fever" or "She is not interested in the proposal."
The key idea is to look at the structure of the sentence (the syntactic dependency) and the meaning of the words (the semantic consistency) to better understand the negation. This allows the system to accurately identify the negation word (like "not"), the thing being negated (the "fever" or "interested"), and the relationship between them.
Being able to extract this "negation triplet" information from text could be useful for improving the recall of large language models or other information extraction tasks, as it provides a more complete understanding of the meaning conveyed in the text.
Technical Explanation
The authors formalize the negation triplet extraction task as identifying a triplet consisting of a negation word, the entity it modifies, and the relationship between them. For example, in the sentence "The patient does not have a fever," the negation triplet would be ("not", "have", "fever").
To address this task, the authors propose a model that first uses a syntactic dependency parser to identify the negation words and their associated entities in the sentence. It then applies a series of rules to ensure the semantic consistency of the extracted triplets, filtering out invalid combinations.
The model is evaluated on several datasets of negation-rich text, including biomedical literature and social media posts. The results show that the proposed approach outperforms existing information extraction techniques, particularly in terms of precision and F1 score.
Critical Analysis
The paper provides a thorough and well-designed study of negation triplet extraction. The authors acknowledge some limitations, such as the potential for their rule-based approach to miss certain complex negation constructions.
Additionally, the evaluation is limited to a few specific datasets, and it would be valuable to assess the model's performance on a broader range of text genres and domains. There may also be opportunities to further enhance the model's capabilities through the incorporation of advanced language modeling techniques or joint extraction of multiple related entities.
Overall, the research represents a valuable contribution to the field of information extraction, and the proposed approach could have promising applications in tasks such as sentiment analysis or knowledge base construction.
Conclusion
This paper presents a novel method for extracting negation triplets from text, which could have important applications in various natural language processing tasks. By leveraging syntactic dependency and semantic consistency, the proposed approach demonstrates improved accuracy and completeness compared to existing techniques.
While the research has some limitations, it represents a significant step forward in the field of information extraction and could inspire further advancements in the extraction of complex linguistic structures from unstructured text.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Negation Triplet Extraction with Syntactic Dependency and Semantic Consistency
Yuchen Shi, Deqing Yang, Jingping Liu, Yanghua Xiao, Zongyu Wang, Huimin Xu
Previous works of negation understanding mainly focus on negation cue detection and scope resolution, without identifying negation subject which is also significant to the downstream tasks. In this paper, we propose a new negation triplet extraction (NTE) task which aims to extract negation subject along with negation cue and scope. To achieve NTE, we devise a novel Syntax&Semantic-Enhanced Negation Extraction model, namely SSENE, which is built based on a generative pretrained language model (PLM) {of Encoder-Decoder architecture} with a multi-task learning framework. Specifically, the given sentence's syntactic dependency tree is incorporated into the PLM's encoder to discover the correlations between the negation subject, cue and scope. Moreover, the semantic consistency between the sentence and the extracted triplet is ensured by an auxiliary task learning. Furthermore, we have constructed a high-quality Chinese dataset NegComment based on the users' reviews from the real-world platform of Meituan, upon which our evaluations show that SSENE achieves the best NTE performance compared to the baselines. Our ablation and case studies also demonstrate that incorporating the syntactic information helps the PLM's recognize the distant dependency between the subject and cue, and the auxiliary task learning is helpful to extract the negation triplets with more semantic consistency.
Read more4/16/2024
0
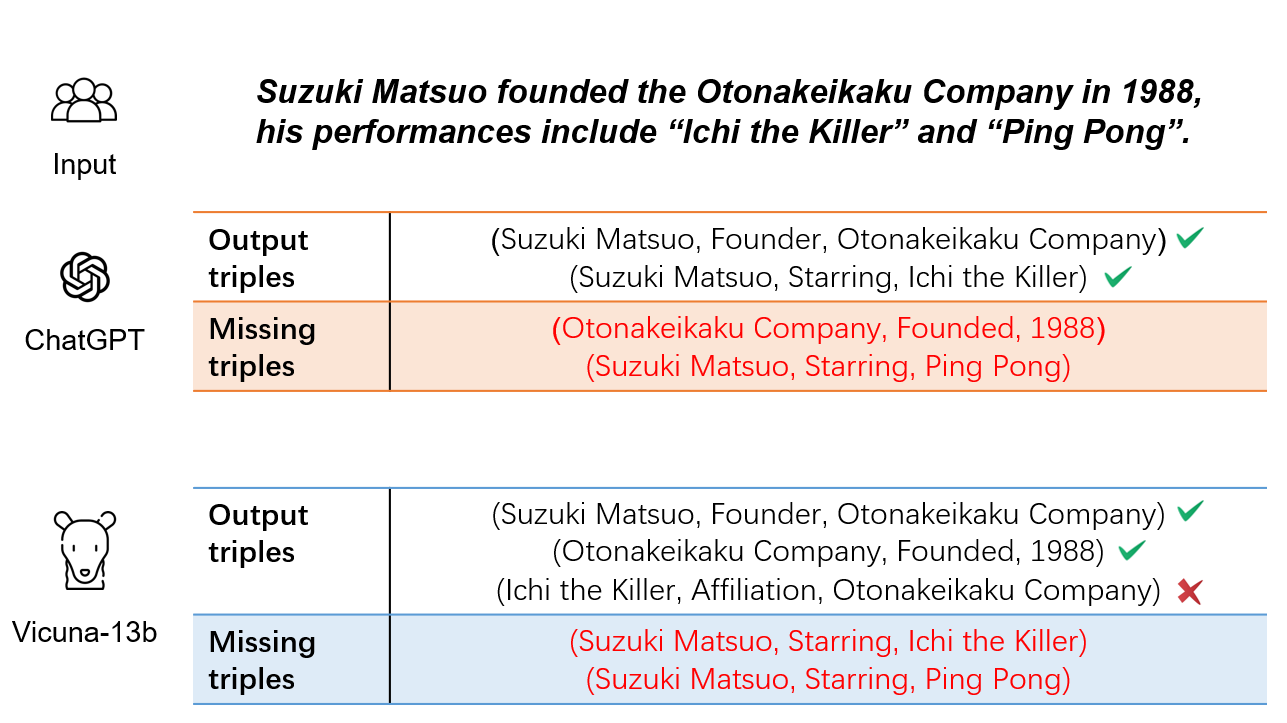
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
Read more4/16/2024
🖼️
0
Evaluation of Machine Translation Based on Semantic Dependencies and Keywords
Kewei Yuan, Qiurong Zhao, Yang Xu, Xiao Zhang, Huansheng Ning
In view of the fact that most of the existing machine translation evaluation algorithms only consider the lexical and syntactic information, but ignore the deep semantic information contained in the sentence, this paper proposes a computational method for evaluating the semantic correctness of machine translations based on reference translations and incorporating semantic dependencies and sentence keyword information. Use the language technology platform developed by the Social Computing and Information Retrieval Research Center of Harbin Institute of Technology to conduct semantic dependency analysis and keyword analysis on sentences, and obtain semantic dependency graphs, keywords, and weight information corresponding to keywords. It includes all word information with semantic dependencies in the sentence and keyword information that affects semantic information. Construct semantic association pairs including word and dependency multi-features. The key semantics of the sentence cannot be highlighted in the semantic information extracted through semantic dependence, resulting in vague semantics analysis. Therefore, the sentence keyword information is also included in the scope of machine translation semantic evaluation. To achieve a comprehensive and in-depth evaluation of the semantic correctness of sentences, the experimental results show that the accuracy of the evaluation algorithm has been improved compared with similar methods, and it can more accurately measure the semantic correctness of machine translation.
Read more4/24/2024

0
Multimodal Relational Triple Extraction with Query-based Entity Object Transformer
Lei Hei, Ning An, Tingjing Liao, Qi Ma, Jiaqi Wang, Feiliang Ren
Multimodal Relation Extraction is crucial for constructing flexible and realistic knowledge graphs. Recent studies focus on extracting the relation type with entity pairs present in different modalities, such as one entity in the text and another in the image. However, existing approaches require entities and objects given beforehand, which is costly and impractical. To address the limitation, we propose a novel task, Multimodal Entity-Object Relational Triple Extraction, which aims to extract all triples (entity span, relation, object region) from image-text pairs. To facilitate this study, we modified a multimodal relation extraction dataset MORE, which includes 21 relation types, to create a new dataset containing 20,264 triples, averaging 5.75 triples per image-text pair. Moreover, we propose QEOT, a query-based model with a selective attention mechanism, to dynamically explore the interaction and fusion of textual and visual information. In particular, the proposed method can simultaneously accomplish entity extraction, relation classification, and object detection with a set of queries. Our method is suitable for downstream applications and reduces error accumulation due to the pipeline-style approaches. Extensive experimental results demonstrate that our proposed method outperforms the existing baselines by 8.06% and achieves state-of-the-art performance.
Read more8/19/2024