NeLF-Pro: Neural Light Field Probes for Multi-Scale Novel View Synthesis

0

Sign in to get full access
Overview
• This paper introduces NeLF-Pro, a new approach for capturing and rendering dynamic light fields using neural networks. • The key idea is to represent the light field in a compact neural representation that can be efficiently queried and rendered. • This allows for high-quality view synthesis of complex real-world scenes, even with sparse input data.
Plain English Explanation
NeLF-Pro is a new technique that uses artificial intelligence to capture and display 3D light fields. A light field is the collection of light rays passing through a given space, which contains information about the color, intensity, and direction of the light. Traditionally, capturing and rendering high-quality light fields has been challenging and resource-intensive.
The researchers behind NeLF-Pro have developed a neural network-based approach that can efficiently represent the light field in a compact form. This allows the system to synthesize new views of a scene from sparse input data, like a few photographs or video frames. The neural representation can be queried to generate photorealistic images from any viewpoint, enabling advanced applications like virtual reality, augmented reality, and computational photography.
Compared to previous methods, NeLF-Pro offers several key advantages. It can handle complex real-world scenes with moving objects, it requires less input data to produce high-quality results, and it can be efficiently computed in real-time. This makes it a promising approach for a wide range of visual computing tasks that rely on understanding and rendering the 3D light field.
Technical Explanation
The core of NeLF-Pro is a neural network architecture that can compactly encode the 4D light field of a scene. This representation, called a "neural light field probe," allows the system to efficiently query and render novel views.
The key technical components are:
- MonoPatchNeRF: A patch-based neural radiance field that can handle moving objects and occlusions.
- NerfCodec: A neural feature compression module that reduces the memory footprint of the light field representation.
- LIDAR4D: A technique for incorporating sparse 4D sensor data, like LIDAR, to further improve the light field reconstruction.
The system is trained end-to-end on real-world light field datasets, allowing it to generalize to complex scenes. Experiments show that NeLF-Pro can outperform previous state-of-the-art methods in terms of rendering quality, view synthesis, and computational efficiency.
Critical Analysis
The NeLF-Pro paper presents a compelling approach for compact and efficient light field representation and rendering. The use of neural networks to encode the 4D light field is a promising direction, as it allows the system to handle complex real-world scenes and generate high-quality results from sparse input data.
One potential limitation is the reliance on specialized 4D sensor data, like LIDAR. While this can improve the light field reconstruction, it may limit the applicability of the method in scenarios where such specialized hardware is not available. The authors acknowledge this and suggest that future work could explore ways to leverage more widely available 2D or 3D data sources.
Additionally, the paper does not provide a detailed analysis of the computational and memory requirements of the NeLF-Pro system. As the target applications, such as virtual reality and augmented reality, often have strict performance constraints, a more thorough evaluation of the system's efficiency would be valuable.
Overall, the NeLF-Pro work represents a significant advancement in the field of light field rendering and suggests that neural network-based approaches can be highly effective in this domain. Further research and development in this area could lead to transformative applications in various visual computing fields.
Conclusion
The NeLF-Pro paper introduces a novel neural network-based approach for capturing and rendering dynamic light fields. By representing the light field in a compact neural format, the system can efficiently synthesize photorealistic views of complex real-world scenes from sparse input data.
The key technical innovations, such as the MonoPatchNeRF architecture and the NerfCodec compression module, allow for high-quality view synthesis and reduced memory footprint. The integration of LIDAR4D data further enhances the light field reconstruction.
The potential impact of NeLF-Pro is significant, as it can enable advanced applications in virtual reality, augmented reality, computational photography, and beyond. By providing a more efficient and scalable approach to light field capture and rendering, this work represents an important step forward in the field of visual computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NeLF-Pro: Neural Light Field Probes for Multi-Scale Novel View Synthesis
Zinuo You, Andreas Geiger, Anpei Chen
We present NeLF-Pro, a novel representation to model and reconstruct light fields in diverse natural scenes that vary in extent and spatial granularity. In contrast to previous fast reconstruction methods that represent the 3D scene globally, we model the light field of a scene as a set of local light field feature probes, parameterized with position and multi-channel 2D feature maps. Our central idea is to bake the scene's light field into spatially varying learnable representations and to query point features by weighted blending of probes close to the camera - allowing for mipmap representation and rendering. We introduce a novel vector-matrix-matrix (VMM) factorization technique that effectively represents the light field feature probes as products of core factors (i.e., VM) shared among local feature probes, and a basis factor (i.e., M) - efficiently encoding internal relationships and patterns within the scene. Experimentally, we demonstrate that NeLF-Pro significantly boosts the performance of feature grid-based representations, and achieves fast reconstruction with better rendering quality while maintaining compact modeling. Project webpage https://sinoyou.github.io/nelf-pro/.
Read more4/23/2024

0
G-NeLF: Memory- and Data-Efficient Hybrid Neural Light Field for Novel View Synthesis
Lutao Jiang, Lin Wang
Following the burgeoning interest in implicit neural representation, Neural Light Field (NeLF) has been introduced to predict the color of a ray directly. Unlike Neural Radiance Field (NeRF), NeLF does not create a point-wise representation by predicting color and volume density for each point in space. However, the current NeLF methods face a challenge as they need to train a NeRF model first and then synthesize over 10K views to train NeLF for improved performance. Additionally, the rendering quality of NeLF methods is lower compared to NeRF methods. In this paper, we propose G-NeLF, a versatile grid-based NeLF approach that utilizes spatial-aware features to unleash the potential of the neural network's inference capability, and consequently overcome the difficulties of NeLF training. Specifically, we employ a spatial-aware feature sequence derived from a meticulously crafted grid as the ray's representation. Drawing from our empirical studies on the adaptability of multi-resolution hash tables, we introduce a novel grid-based ray representation for NeLF that can represent the entire space with a very limited number of parameters. To better utilize the sequence feature, we design a lightweight ray color decoder that simulates the ray propagation process, enabling a more efficient inference of the ray's color. G-NeLF can be trained without necessitating significant storage overhead and with the model size of only 0.95 MB to surpass previous state-of-the-art NeLF. Moreover, compared with grid-based NeRF methods, e.g., Instant-NGP, we only utilize one-tenth of its parameters to achieve higher performance. Our code will be released upon acceptance.
Read more9/10/2024
0
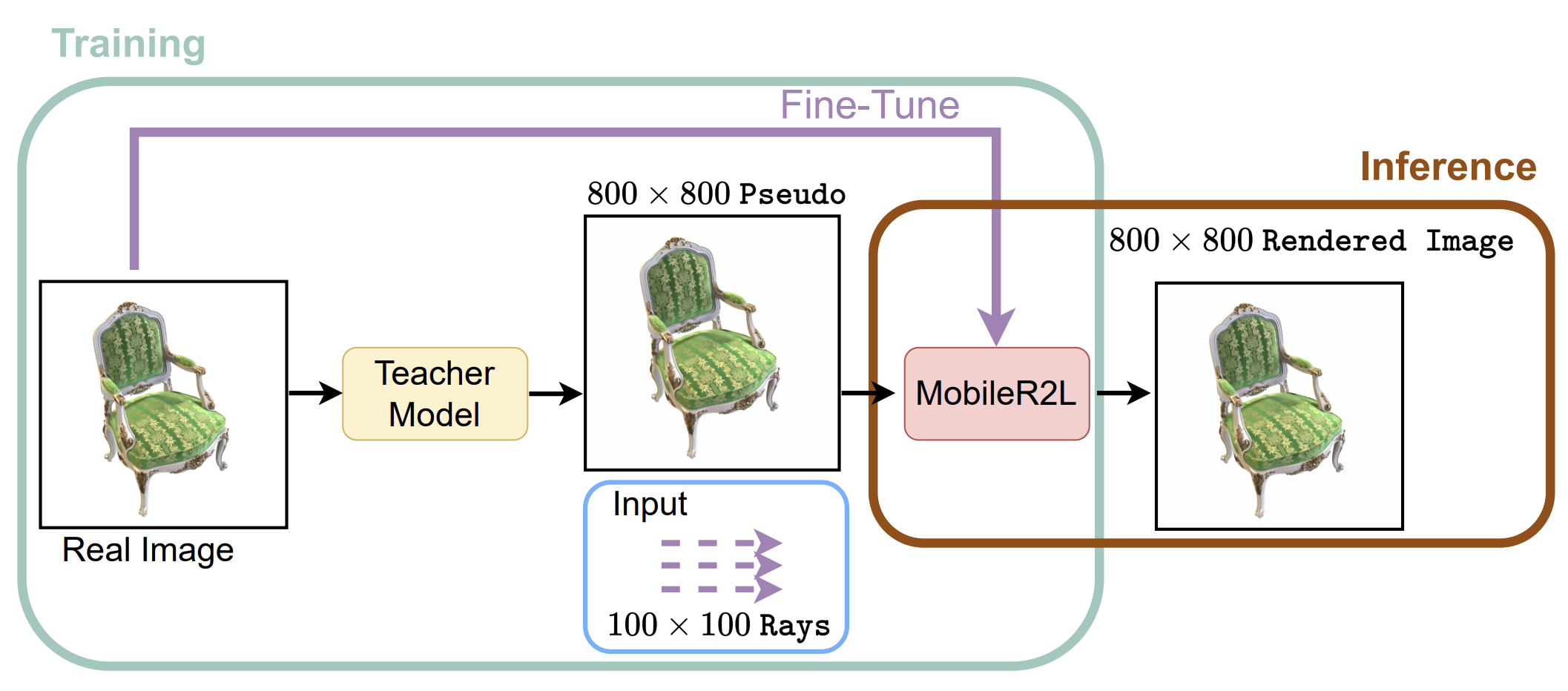
Efficient Neural Light Fields (ENeLF) for Mobile Devices
Austin Peng
Novel view synthesis (NVS) is a challenge in computer vision and graphics, focusing on generating realistic images of a scene from unobserved camera poses, given a limited set of authentic input images. Neural radiance fields (NeRF) achieved impressive results in rendering quality by utilizing volumetric rendering. However, NeRF and its variants are unsuitable for mobile devices due to the high computational cost of volumetric rendering. Emerging research in neural light fields (NeLF) eliminates the need for volumetric rendering by directly learning a mapping from ray representation to pixel color. NeLF has demonstrated its capability to achieve results similar to NeRF but requires a more extensive, computationally intensive network that is not mobile-friendly. Unlike existing works, this research builds upon the novel network architecture introduced by MobileR2L and aggressively applies a compression technique (channel-wise structure pruning) to produce a model that runs efficiently on mobile devices with lower latency and smaller sizes, with a slight decrease in performance.
Read more6/4/2024
0
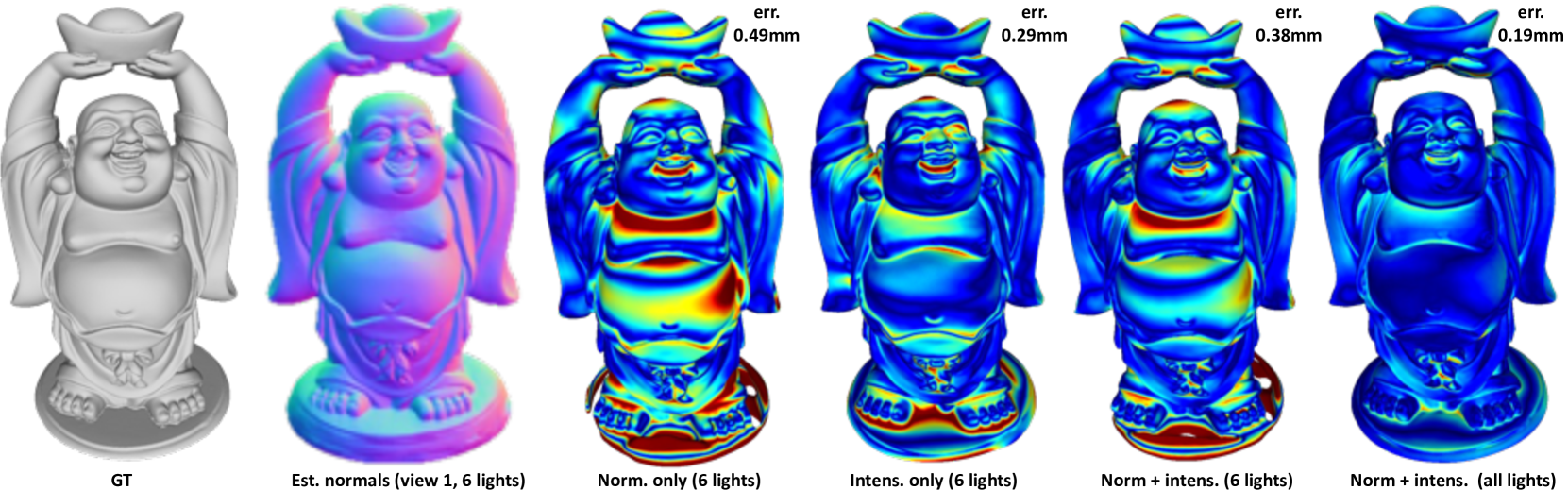
NPLMV-PS: Neural Point-Light Multi-View Photometric Stereo
Fotios Logothetis, Ignas Budvytis, Roberto Cipolla
In this work we present a novel multi-view photometric stereo (MVPS) method. Like many works in 3D reconstruction we are leveraging neural shape representations and learnt renderers. However, our work differs from the state-of-the-art multi-view PS methods such as PS-NeRF or Supernormal in that we explicitly leverage per-pixel intensity renderings rather than relying mainly on estimated normals. We model point light attenuation and explicitly raytrace cast shadows in order to best approximate the incoming radiance for each point. The estimated incoming radiance is used as input to a fully neural material renderer that uses minimal prior assumptions and it is jointly optimised with the surface. Estimated normals and segmentation maps are also incorporated in order to maximise the surface accuracy. Our method is among the first (along with Supernormal) to outperform the classical MVPS approach proposed by the DiLiGenT-MV benchmark and achieves average 0.2mm Chamfer distance for objects imaged at approx 1.5m distance away with approximate 400x400 resolution. Moreover, our method shows high robustness to the sparse MVPS setup (6 views, 6 lights) greatly outperforming the SOTA competitor (0.38mm vs 0.61mm), illustrating the importance of neural rendering in multi-view photometric stereo.
Read more7/23/2024