NPLMV-PS: Neural Point-Light Multi-View Photometric Stereo

0
Sign in to get full access
Overview
- This paper introduces NPLMV-PS, a neural network-based approach to multi-view photometric stereo reconstruction.
- The key innovation is the use of neural point lights to model the lighting conditions, which allows for more accurate 3D reconstruction compared to traditional photometric stereo methods.
- The system takes as input multi-view images of an object under varying lighting conditions and outputs a 3D mesh representation of the object's surface.
Plain English Explanation
The NPLMV-PS paper presents a new way to create 3D models of objects using multiple camera views and different lighting conditions. Traditional photometric stereo methods struggle to accurately model the complex lighting in real-world scenes.
To address this, the researchers developed a neural network that can learn to represent the lighting using a set of virtual "point lights." By modeling the lighting this way, the system can better reconstruct the 3D shape of the object being imaged. The input to the system is a collection of photos taken from multiple viewpoints with varying lighting, and the output is a 3D mesh that captures the surface of the object.
This neural point light-based approach allows for more accurate 3D reconstruction compared to traditional photometric stereo techniques, which struggle to handle complex real-world lighting conditions. The NPLMV-PS method could enable improved 3D scanning and modeling in applications like digital content creation, robotics, and AR/VR.
Technical Explanation
The NPLMV-PS system takes as input a set of multi-view images of an object under varying lighting conditions. The key innovation is the use of a neural network to model the lighting as a set of virtual "point lights" rather than relying on traditional photometric stereo assumptions.
The network architecture consists of an image encoder, a point light encoder, and a surface reconstruction module. The image encoder processes the input images to extract visual features, while the point light encoder models the lighting conditions as a set of learnable point light parameters. These lighting and visual features are then combined in the surface reconstruction module to predict a 3D mesh representation of the object's surface.
By parameterizing the lighting using neural point lights, the system can better handle complex, real-world illumination compared to traditional photometric stereo methods. This neural point light-based approach allows for more accurate 3D reconstruction, as demonstrated through extensive experiments on benchmark datasets.
The researchers also introduce a novel fast, generalized Gaussian splatting technique for efficient 3D mesh reconstruction from the network outputs. This efficient approach enables real-time 3D reconstruction, making the system applicable in a variety of interactive applications.
Critical Analysis
The NPLMV-PS method represents an interesting and promising approach to multi-view photometric stereo reconstruction. The use of neural point lights to model lighting conditions is a clever idea that allows the system to handle more complex real-world scenes compared to traditional techniques.
However, the paper does not discuss the potential limitations of the method, such as its performance on highly specular or transparent objects, which can be challenging for photometric stereo approaches. Additionally, the scalability and flexibility of the system when dealing with larger or more complex scenes is not thoroughly explored.
Further research could investigate the robustness of the NPLMV-PS method to noisy or incomplete input data, as well as explore ways to extend the approach to handle dynamic scenes or incorporate additional cues beyond multi-view photometric information.
Conclusion
The NPLMV-PS paper presents a novel neural network-based approach to multi-view photometric stereo reconstruction that leverages the use of neural point lights to model lighting conditions. This innovative technique allows for more accurate 3D reconstruction compared to traditional methods, which struggle to handle complex real-world illumination.
The efficient Gaussian splatting-based reconstruction further enables real-time 3D scanning, opening up possibilities for applications in digital content creation, robotics, and augmented/virtual reality. While the method shows promise, further research is needed to explore its limitations and potential extensions to more challenging scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NPLMV-PS: Neural Point-Light Multi-View Photometric Stereo
Fotios Logothetis, Ignas Budvytis, Roberto Cipolla
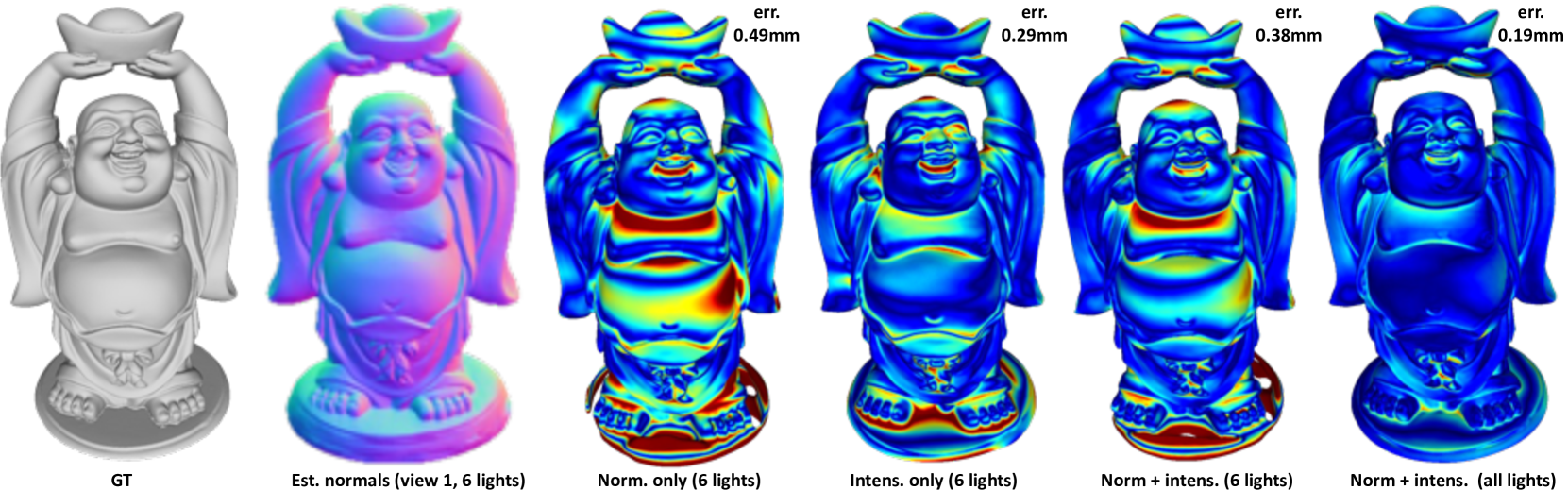
In this work we present a novel multi-view photometric stereo (MVPS) method. Like many works in 3D reconstruction we are leveraging neural shape representations and learnt renderers. However, our work differs from the state-of-the-art multi-view PS methods such as PS-NeRF or Supernormal in that we explicitly leverage per-pixel intensity renderings rather than relying mainly on estimated normals. We model point light attenuation and explicitly raytrace cast shadows in order to best approximate the incoming radiance for each point. The estimated incoming radiance is used as input to a fully neural material renderer that uses minimal prior assumptions and it is jointly optimised with the surface. Estimated normals and segmentation maps are also incorporated in order to maximise the surface accuracy. Our method is among the first (along with Supernormal) to outperform the classical MVPS approach proposed by the DiLiGenT-MV benchmark and achieves average 0.2mm Chamfer distance for objects imaged at approx 1.5m distance away with approximate 400x400 resolution. Moreover, our method shows high robustness to the sparse MVPS setup (6 views, 6 lights) greatly outperforming the SOTA competitor (0.38mm vs 0.61mm), illustrating the importance of neural rendering in multi-view photometric stereo.
Read more7/23/2024
0
MonoPatchNeRF: Improving Neural Radiance Fields with Patch-based Monocular Guidance
Yuqun Wu, Jae Yong Lee, Chuhang Zou, Shenlong Wang, Derek Hoiem
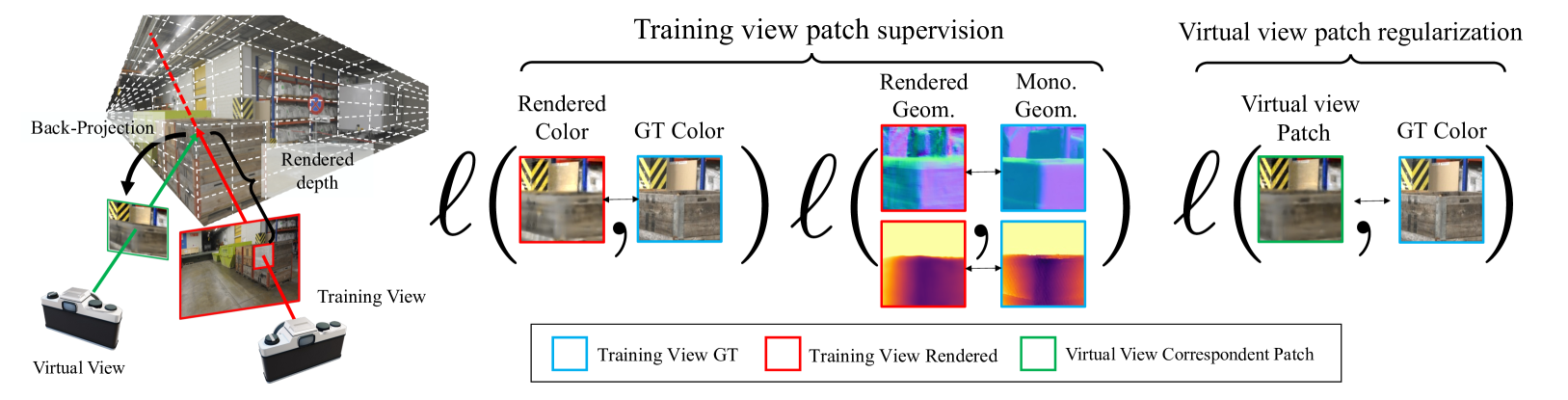
The latest regularized Neural Radiance Field (NeRF) approaches produce poor geometry and view extrapolation for large scale sparse view scenes, such as ETH3D. Density-based approaches tend to be under-constrained, while surface-based approaches tend to miss details. In this paper, we take a density-based approach, sampling patches instead of individual rays to better incorporate monocular depth and normal estimates and patch-based photometric consistency constraints between training views and sampled virtual views. Loosely constraining densities based on estimated depth aligned to sparse points further improves geometric accuracy. While maintaining similar view synthesis quality, our approach significantly improves geometric accuracy on the ETH3D benchmark, e.g. increasing the F1@2cm score by 4x-8x compared to other regularized density-based approaches, with much lower training and inference time than other approaches.
Read more8/23/2024

0
SparseCraft: Few-Shot Neural Reconstruction through Stereopsis Guided Geometric Linearization
Mae Younes, Amine Ouasfi, Adnane Boukhayma
We present a novel approach for recovering 3D shape and view dependent appearance from a few colored images, enabling efficient 3D reconstruction and novel view synthesis. Our method learns an implicit neural representation in the form of a Signed Distance Function (SDF) and a radiance field. The model is trained progressively through ray marching enabled volumetric rendering, and regularized with learning-free multi-view stereo (MVS) cues. Key to our contribution is a novel implicit neural shape function learning strategy that encourages our SDF field to be as linear as possible near the level-set, hence robustifying the training against noise emanating from the supervision and regularization signals. Without using any pretrained priors, our method, called SparseCraft, achieves state-of-the-art performances both in novel-view synthesis and reconstruction from sparse views in standard benchmarks, while requiring less than 10 minutes for training.
Read more7/22/2024

0
GS-Phong: Meta-Learned 3D Gaussians for Relightable Novel View Synthesis
Yumeng He, Yunbo Wang, Xiaokang Yang
Decoupling the illumination in 3D scenes is crucial for novel view synthesis and relighting. In this paper, we propose a novel method for representing a scene illuminated by a point light using a set of relightable 3D Gaussian points. Inspired by the Blinn-Phong model, our approach decomposes the scene into ambient, diffuse, and specular components, enabling the synthesis of realistic lighting effects. To facilitate the decomposition of geometric information independent of lighting conditions, we introduce a novel bilevel optimization-based meta-learning framework. The fundamental idea is to view the rendering tasks under various lighting positions as a multi-task learning problem, which our meta-learning approach effectively addresses by generalizing the learned Gaussian geometries not only across different viewpoints but also across diverse light positions. Experimental results demonstrate the effectiveness of our approach in terms of training efficiency and rendering quality compared to existing methods for free-viewpoint relighting.
Read more6/3/2024