NeRF-VO: Real-Time Sparse Visual Odometry with Neural Radiance Fields

0

Sign in to get full access
Overview
- This paper introduces NeRF-VO, a system that combines neural radiance fields (NeRFs) with sparse visual odometry (VO) to enable real-time 6DoF camera pose estimation.
- NeRF-VO uses a pre-trained NeRF model to guide the sparse feature matching and geometric verification required for VO, leading to more robust and accurate pose tracking compared to traditional methods.
- The system can run in real-time on a single GPU, making it suitable for mobile and robotics applications that require low-latency, high-precision localization.
Plain English Explanation
NeRF-VO is a new technique that helps a camera figure out its exact position and orientation in 3D space, which is really important for things like augmented reality, self-driving cars, and robots that need to know where they are.
Traditional methods for doing this, called visual odometry, often struggle with things like changing lighting conditions or when there aren't many clear visual features to track. NeRF-VO solves this by using a special kind of 3D model called a neural radiance field (NeRF), which can capture a lot of detailed information about the environment.
The NeRF model acts as a guide, helping the visual odometry system find and match key visual features more accurately. This makes the whole pose estimation process much more robust and reliable, even in challenging environments. And because NeRF-VO can run in real-time on a single GPU, it's well-suited for uses in mobile devices and robots that need to know their location very quickly and precisely.
Technical Explanation
NeRF-VO builds upon the recent advancements in neural radiance fields (NeRFs) to enable robust, real-time 6DoF camera pose estimation. Traditional sparse visual odometry (VO) methods struggle with challenges like feature matching, outlier rejection, and scale estimation, especially in featureless or dynamic environments.
NeRF-VO addresses these issues by leveraging a pre-trained NeRF model of the scene to guide the sparse feature tracking and geometric verification steps of VO. The NeRF model provides a dense 3D representation of the environment, which allows NeRF-VO to more accurately match and validate visual features across frames. This leads to more robust and accurate 6DoF pose estimates compared to standard VO approaches.
The system operates in two stages. First, it initializes the camera pose using a few keyframes and the pre-trained NeRF. Then, it tracks the camera pose in real-time by iteratively updating the pose using sparse feature matching and a NeRF-based geometric verification step. This NeRF-guided approach enables NeRF-VO to achieve high-precision localization, even in challenging conditions that would typically cause traditional VO to fail.
Critical Analysis
The authors of the NeRF-VO paper highlight several key advantages of their system, including its real-time performance, robustness to varying environments, and improved accuracy compared to existing VO methods. However, they also acknowledge some potential limitations and areas for further research.
One limitation is that NeRF-VO relies on a pre-trained NeRF model of the environment, which may not always be available or easy to obtain. The authors suggest that in the future, the system could potentially learn the NeRF model and camera pose simultaneously, similar to the approach used in VRS-NeRF.
Additionally, the current NeRF-VO implementation assumes a static environment, which may not hold true in all real-world scenarios. Extending the system to handle dynamic scenes, potentially by leveraging techniques from NVINS or Leveraging Neural Radiance Fields, could be an area of future research.
Finally, the authors note that the geometric accuracy of the NeRF reconstructions used in NeRF-VO has not been thoroughly evaluated, which could be an important consideration for applications that require precise 3D measurements. The Evaluating Geometric Accuracy paper provides a helpful framework for assessing the 3D reconstruction quality of NeRFs.
Conclusion
NeRF-VO represents a significant advancement in real-time 6DoF camera pose estimation, leveraging the power of neural radiance fields to overcome the limitations of traditional sparse visual odometry. By using the dense 3D representation provided by NeRFs, NeRF-VO achieves more robust and accurate localization, even in challenging environments. As NeRF and related techniques continue to evolve, integrating them with visual odometry systems like NeRF-VO could lead to transformative improvements in mobile robotics, augmented reality, and other applications that require precise, low-latency 3D localization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NeRF-VO: Real-Time Sparse Visual Odometry with Neural Radiance Fields
Jens Naumann, Binbin Xu, Stefan Leutenegger, Xingxing Zuo
We introduce a novel monocular visual odometry (VO) system, NeRF-VO, that integrates learning-based sparse visual odometry for low-latency camera tracking and a neural radiance scene representation for fine-detailed dense reconstruction and novel view synthesis. Our system initializes camera poses using sparse visual odometry and obtains view-dependent dense geometry priors from a monocular prediction network. We harmonize the scale of poses and dense geometry, treating them as supervisory cues to train a neural implicit scene representation. NeRF-VO demonstrates exceptional performance in both photometric and geometric fidelity of the scene representation by jointly optimizing a sliding window of keyframed poses and the underlying dense geometry, which is accomplished through training the radiance field with volume rendering. We surpass SOTA methods in pose estimation accuracy, novel view synthesis fidelity, and dense reconstruction quality across a variety of synthetic and real-world datasets while achieving a higher camera tracking frequency and consuming less GPU memory.
Read more7/17/2024
0
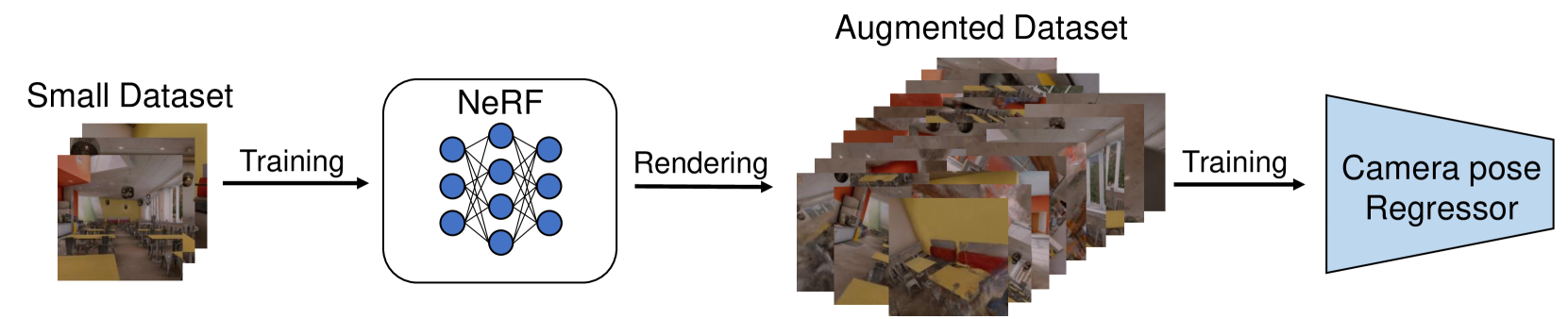
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Juyeop Han, Lukas Lao Beyer, Guilherme V. Cavalheiro, Sertac Karaman
In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry (VIO) to provide a robust solution for real-time robotic navigation. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in a photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
Read more8/20/2024
0
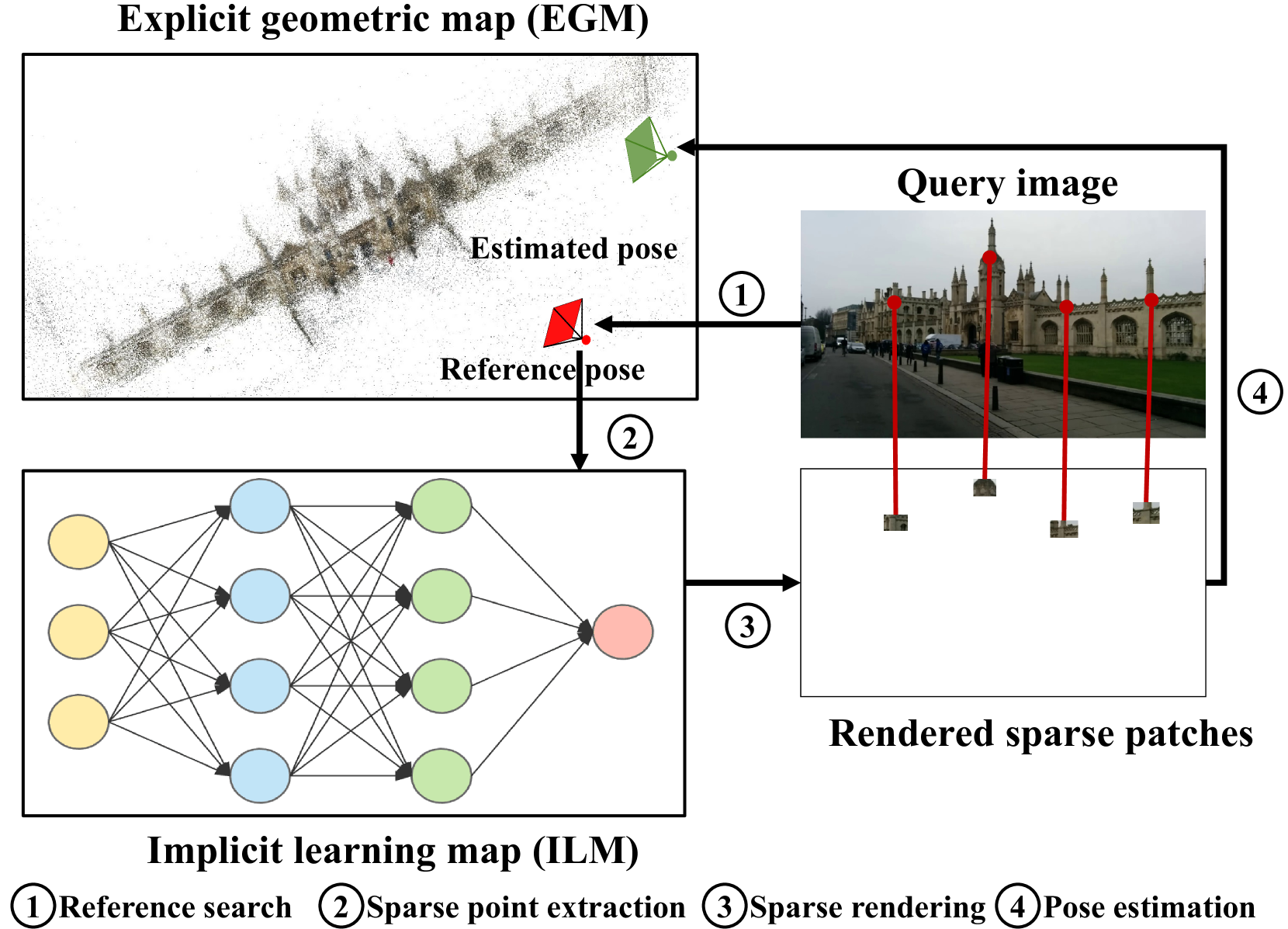
VRS-NeRF: Visual Relocalization with Sparse Neural Radiance Field
Fei Xue, Ignas Budvytis, Daniel Olmeda Reino, Roberto Cipolla
Visual relocalization is a key technique to autonomous driving, robotics, and virtual/augmented reality. After decades of explorations, absolute pose regression (APR), scene coordinate regression (SCR), and hierarchical methods (HMs) have become the most popular frameworks. However, in spite of high efficiency, APRs and SCRs have limited accuracy especially in large-scale outdoor scenes; HMs are accurate but need to store a large number of 2D descriptors for matching, resulting in poor efficiency. In this paper, we propose an efficient and accurate framework, called VRS-NeRF, for visual relocalization with sparse neural radiance field. Precisely, we introduce an explicit geometric map (EGM) for 3D map representation and an implicit learning map (ILM) for sparse patches rendering. In this localization process, EGP provides priors of spare 2D points and ILM utilizes these sparse points to render patches with sparse NeRFs for matching. This allows us to discard a large number of 2D descriptors so as to reduce the map size. Moreover, rendering patches only for useful points rather than all pixels in the whole image reduces the rendering time significantly. This framework inherits the accuracy of HMs and discards their low efficiency. Experiments on 7Scenes, CambridgeLandmarks, and Aachen datasets show that our method gives much better accuracy than APRs and SCRs, and close performance to HMs but is much more efficient.
Read more4/16/2024
🧠
0
Leveraging Neural Radiance Fields for Pose Estimation of an Unknown Space Object during Proximity Operations
Antoine Legrand, Renaud Detry, Christophe De Vleeschouwer
We address the estimation of the 6D pose of an unknown target spacecraft relative to a monocular camera, a key step towards the autonomous rendezvous and proximity operations required by future Active Debris Removal missions. We present a novel method that enables an off-the-shelf spacecraft pose estimator, which is supposed to known the target CAD model, to be applied on an unknown target. Our method relies on an in-the wild NeRF, i.e., a Neural Radiance Field that employs learnable appearance embeddings to represent varying illumination conditions found in natural scenes. We train the NeRF model using a sparse collection of images that depict the target, and in turn generate a large dataset that is diverse both in terms of viewpoint and illumination. This dataset is then used to train the pose estimation network. We validate our method on the Hardware-In-the-Loop images of SPEED+ that emulate lighting conditions close to those encountered on orbit. We demonstrate that our method successfully enables the training of an off-the-shelf spacecraft pose estimation network from a sparse set of images. Furthermore, we show that a network trained using our method performs similarly to a model trained on synthetic images generated using the CAD model of the target.
Read more6/12/2024