NetMamba: Efficient Network Traffic Classification via Pre-training Unidirectional Mamba
2405.11449
0
0
Abstract
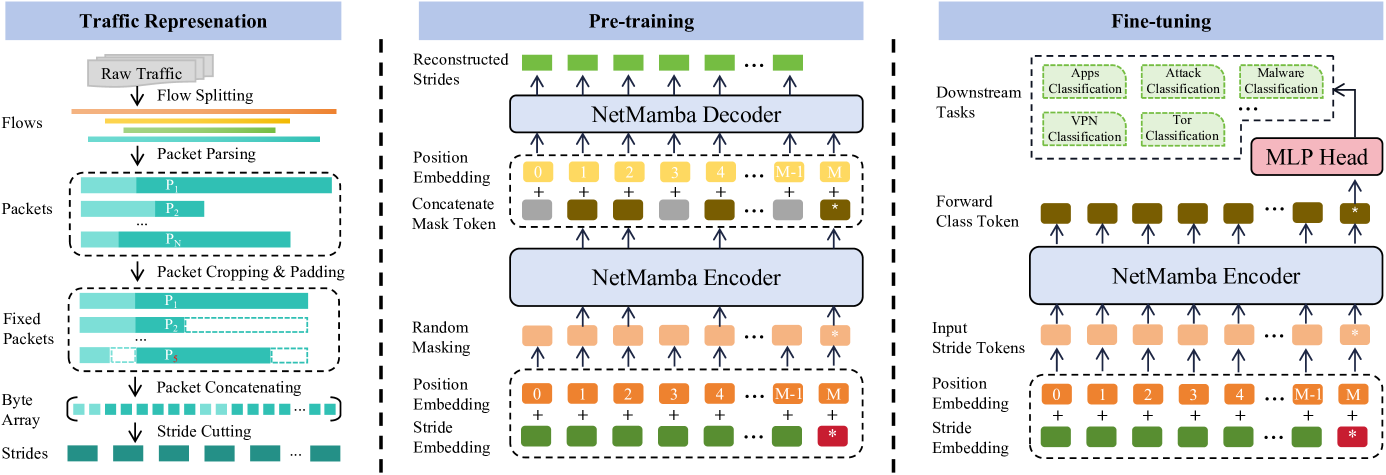
Network traffic classification is a crucial research area aiming to enhance service quality, streamline network management, and bolster cybersecurity. To address the growing complexity of transmission encryption techniques, various machine learning and deep learning methods have been proposed. However, existing approaches face two main challenges. Firstly, they struggle with model inefficiency due to the quadratic complexity of the widely used Transformer architecture. Secondly, they suffer from inadequate traffic representation because of discarding important byte information while retaining unwanted biases. To address these challenges, we propose NetMamba, an efficient linear-time state space model equipped with a comprehensive traffic representation scheme. We adopt a specially selected and improved unidirectional Mamba architecture for the networking field, instead of the Transformer, to address efficiency issues. In addition, we design a traffic representation scheme to extract valid information from massive traffic data while removing biased information. Evaluation experiments on six public datasets encompassing three main classification tasks showcase NetMamba's superior classification performance compared to state-of-the-art baselines. It achieves an accuracy rate of nearly 99% (some over 99%) in all tasks. Additionally, NetMamba demonstrates excellent efficiency, improving inference speed by up to 60 times while maintaining comparably low memory usage. Furthermore, NetMamba exhibits superior few-shot learning abilities, achieving better classification performance with fewer labeled data. To the best of our knowledge, NetMamba is the first model to tailor the Mamba architecture for networking.
Create account to get full access
Overview
- Presents a novel network traffic classification method called NetMamba that uses pre-training of a unidirectional Mamba model for efficient performance
- Mamba is a time series forecasting model that has shown strong results in various domains, including bi-Mamba for time series forecasting, Mamba3D for 3D point cloud analysis, and MedMamba for medical image classification
- NetMamba leverages the powerful representation learning capabilities of Mamba to effectively classify network traffic, outperforming state-of-the-art approaches
Plain English Explanation
NetMamba is a new method for classifying different types of network traffic, such as web browsing, video streaming, or file downloads. It works by using a machine learning model called Mamba, which has been shown to work well for forecasting time series data in a variety of applications, including visual state space modeling and complementing transformers for spatial-temporal data.
In NetMamba, the Mamba model is first pre-trained on network traffic data, which means it learns general patterns and features about different types of network traffic. This pre-training step allows the model to develop a strong understanding of the underlying characteristics of network traffic before being fine-tuned for the specific task of classifying different traffic types.
The key advantage of this approach is that it allows NetMamba to achieve high accuracy in classifying network traffic without needing as much labeled training data as other methods. This is important because collecting and labeling large amounts of network traffic data can be time-consuming and expensive. By leveraging the pre-training step, NetMamba can learn effective representations of network traffic using fewer labeled examples.
Technical Explanation
The NetMamba model consists of a pre-trained unidirectional Mamba component, which is then fine-tuned for the network traffic classification task. The Mamba model is a powerful time series forecasting architecture that has demonstrated strong performance in a variety of domains, including visual state space modeling and complementing transformers for spatial-temporal data.
The pre-training stage involves training the Mamba model on a large dataset of network traffic data, without any labels. This allows the model to learn general representations and patterns in the data, which can then be leveraged for the downstream classification task. The pre-trained Mamba model is then fine-tuned by adding a classification head and training it on a smaller, labeled dataset of network traffic data.
The authors evaluate NetMamba on several benchmark network traffic classification datasets and compare its performance to state-of-the-art methods. The results show that NetMamba achieves higher accuracy and F1-scores than other approaches, while also requiring less labeled training data to achieve good performance.
Critical Analysis
The paper presents a well-designed study and a compelling approach for network traffic classification. The use of pre-training to leverage the representation learning capabilities of Mamba is a novel and effective strategy, and the experimental results demonstrate the advantages of this approach.
One potential limitation of the study is that it only evaluates NetMamba on a limited set of benchmark datasets. It would be interesting to see how the method performs on a broader range of network traffic data, including real-world enterprise or ISP traffic, which may have different characteristics and challenges.
Additionally, the paper does not provide much insight into the specific features or patterns that the pre-trained Mamba model learns from the network traffic data. A deeper analysis of the model's internal representations and their relationship to the classification task could further strengthen the technical understanding of the approach.
Overall, NetMamba represents a promising advancement in network traffic classification, leveraging the strengths of the Mamba model to achieve efficient and accurate performance. The work suggests interesting avenues for future research in applying advanced time series modeling techniques to network analytics and security applications.
Conclusion
The NetMamba paper presents a novel approach to network traffic classification that leverages the powerful representation learning capabilities of the Mamba time series forecasting model. By pre-training the Mamba model on unlabeled network traffic data, NetMamba can achieve high accuracy in classifying different traffic types while requiring less labeled training data than other state-of-the-art methods.
The technical details and experimental results demonstrate the effectiveness of this approach, and the work suggests exciting opportunities for applying advanced time series modeling techniques to a range of network analytics and security challenges. As networks continue to grow in complexity, innovative methods like NetMamba will be crucial for enabling efficient and accurate traffic monitoring and management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Venturing into Uncharted Waters: The Navigation Compass from Transformer to Mamba
Yuchen Zou, Yineng Chen, Zuchao Li, Lefei Zhang, Hai Zhao
0
0
Transformer, a deep neural network architecture, has long dominated the field of natural language processing and beyond. Nevertheless, the recent introduction of Mamba challenges its supremacy, sparks considerable interest among researchers, and gives rise to a series of Mamba-based models that have exhibited notable potential. This survey paper orchestrates a comprehensive discussion, diving into essential research dimensions, covering: (i) the functioning of the Mamba mechanism and its foundation on the principles of structured state space models; (ii) the proposed improvements and the integration of Mamba with various networks, exploring its potential as a substitute for Transformers; (iii) the combination of Transformers and Mamba to compensate for each other's shortcomings. We have also made efforts to interpret Mamba and Transformer in the framework of kernel functions, allowing for a comparison of their mathematical nature within a unified context. Our paper encompasses the vast majority of improvements related to Mamba to date.
6/26/2024
Bi-Mamba+: Bidirectional Mamba for Time Series Forecasting
Aobo Liang, Xingguo Jiang, Yan Sun, Xiaohou Shi, Ke Li
0
0
Long-term time series forecasting (LTSF) provides longer insights into future trends and patterns. Over the past few years, deep learning models especially Transformers have achieved advanced performance in LTSF tasks. However, LTSF faces inherent challenges such as long-term dependencies capturing and sparse semantic characteristics. Recently, a new state space model (SSM) named Mamba is proposed. With the selective capability on input data and the hardware-aware parallel computing algorithm, Mamba has shown great potential in balancing predicting performance and computational efficiency compared to Transformers. To enhance Mamba's ability to preserve historical information in a longer range, we design a novel Mamba+ block by adding a forget gate inside Mamba to selectively combine the new features with the historical features in a complementary manner. Furthermore, we apply Mamba+ both forward and backward and propose Bi-Mamba+, aiming to promote the model's ability to capture interactions among time series elements. Additionally, multivariate time series data in different scenarios may exhibit varying emphasis on intra- or inter-series dependencies. Therefore, we propose a series-relation-aware decider that controls the utilization of channel-independent or channel-mixing tokenization strategy for specific datasets. Extensive experiments on 8 real-world datasets show that our model achieves more accurate predictions compared with state-of-the-art methods.
6/28/2024

PoinTramba: A Hybrid Transformer-Mamba Framework for Point Cloud Analysis
Zicheng Wang, Zhenghao Chen, Yiming Wu, Zhen Zhao, Luping Zhou, Dong Xu
0
0
Point cloud analysis has seen substantial advancements due to deep learning, although previous Transformer-based methods excel at modeling long-range dependencies on this task, their computational demands are substantial. Conversely, the Mamba offers greater efficiency but shows limited potential compared with Transformer-based methods. In this study, we introduce PoinTramba, a pioneering hybrid framework that synergies the analytical power of Transformer with the remarkable computational efficiency of Mamba for enhanced point cloud analysis. Specifically, our approach first segments point clouds into groups, where the Transformer meticulously captures intricate intra-group dependencies and produces group embeddings, whose inter-group relationships will be simultaneously and adeptly captured by efficient Mamba architecture, ensuring comprehensive analysis. Unlike previous Mamba approaches, we introduce a bi-directional importance-aware ordering (BIO) strategy to tackle the challenges of random ordering effects. This innovative strategy intelligently reorders group embeddings based on their calculated importance scores, significantly enhancing Mamba's performance and optimizing the overall analytical process. Our framework achieves a superior balance between computational efficiency and analytical performance by seamlessly integrating these advanced techniques, marking a substantial leap forward in point cloud analysis. Extensive experiments on datasets such as ScanObjectNN, ModelNet40, and ShapeNetPart demonstrate the effectiveness of our approach, establishing a new state-of-the-art analysis benchmark on point cloud recognition. For the first time, this paradigm leverages the combined strengths of both Transformer and Mamba architectures, facilitating a new standard in the field. The code is available at https://github.com/xiaoyao3302/PoinTramba.
6/18/2024
📈
Mamba3D: Enhancing Local Features for 3D Point Cloud Analysis via State Space Model
Xu Han, Yuan Tang, Zhaoxuan Wang, Xianzhi Li
0
0
Existing Transformer-based models for point cloud analysis suffer from quadratic complexity, leading to compromised point cloud resolution and information loss. In contrast, the newly proposed Mamba model, based on state space models (SSM), outperforms Transformer in multiple areas with only linear complexity. However, the straightforward adoption of Mamba does not achieve satisfactory performance on point cloud tasks. In this work, we present Mamba3D, a state space model tailored for point cloud learning to enhance local feature extraction, achieving superior performance, high efficiency, and scalability potential. Specifically, we propose a simple yet effective Local Norm Pooling (LNP) block to extract local geometric features. Additionally, to obtain better global features, we introduce a bidirectional SSM (bi-SSM) with both a token forward SSM and a novel backward SSM that operates on the feature channel. Extensive experimental results show that Mamba3D surpasses Transformer-based counterparts and concurrent works in multiple tasks, with or without pre-training. Notably, Mamba3D achieves multiple SoTA, including an overall accuracy of 92.6% (train from scratch) on the ScanObjectNN and 95.1% (with single-modal pre-training) on the ModelNet40 classification task, with only linear complexity.
4/24/2024