Network-based Neighborhood regression

0
Sign in to get full access
Overview
- Paper proposes a "network-based neighborhood regression" method for predicting target variables on network-structured data
- Approach uses information from a node's network neighbors to make predictions, rather than just the node's own features
- Demonstrated on two real-world datasets, showing improved performance over baseline methods
Plain English Explanation
The paper introduces a new way to make predictions on data that is organized in a network structure, such as social networks or transportation systems. Rather than just looking at the features of a single node (e.g. a person or location) to make a prediction, the method also takes into account the features of that node's neighboring nodes in the network.
The key idea is that the relationships between nodes in a network can provide useful information for making predictions. For example, if you're trying to predict a person's income, their immediate friends and contacts may give you additional clues beyond just looking at the person's individual characteristics.
The paper demonstrates this "network-based neighborhood regression" approach on two real-world datasets, and shows that it outperforms more standard prediction methods that don't leverage the network structure. This suggests the approach could be useful for a variety of network-based prediction and analysis tasks.
Technical Explanation
The paper proposes a "Network-based Neighborhood Regression" (NNR) method for predicting target variables on network-structured data. Traditional regression approaches only consider the features of a single node, but NNR also incorporates information from the node's network neighbors.
The key idea is to learn a regression function that takes as input both the features of a node and aggregated features of its neighbors. This allows the model to capture how a node's relationships and connections in the network can provide useful signal for the prediction task.
Mathematically, NNR learns a function f(x_i, N(i)) that maps a node's features x_i and the aggregated features of its neighbors N(i) to the target variable y_i. The paper explores different ways to aggregate the neighbor features, such as using the mean or a learnable weighted sum.
The authors evaluate NNR on two real-world datasets: one for predicting housing prices based on a road network, and another for predicting crime rates based on a social network. The results show that NNR outperforms baseline regression methods that don't utilize the network structure.
Critical Analysis
The paper provides a novel and intuitive approach to leveraging network structure for improved prediction tasks. Incorporating information from a node's neighbors is a natural way to capture relational and contextual effects that may be missed by purely node-level models.
That said, the paper does not explore the limitations or potential downsides of the NNR approach. For example, it's unclear how well the method would scale to very large networks, or how robust it would be to noise or missing network data. The paper also doesn't discuss the computational complexity or training time of the NNR model compared to simpler baselines.
Additionally, while the results demonstrate improved predictive performance, the paper does not provide much analysis or insight into why the network-based approach is beneficial for the specific tasks studied. Further investigation into the types of problems and network structures where NNR is most advantageous would strengthen the contribution.
Overall, the network-based neighborhood regression concept is a promising direction, but the paper would be strengthened by a more thorough exploration of the approach's strengths, weaknesses, and appropriate applications.
Conclusion
This paper introduces a novel "network-based neighborhood regression" method that leverages a node's network relationships to improve predictive performance on tasks with network-structured data. The approach shows promising results on two real-world datasets, suggesting it could be a useful technique for a variety of network-based prediction and analysis problems. While the paper provides a solid technical foundation, further research is needed to fully understand the approach's limitations and optimal applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Network-based Neighborhood regression
Yaoming Zhen, Jin-Hong Du
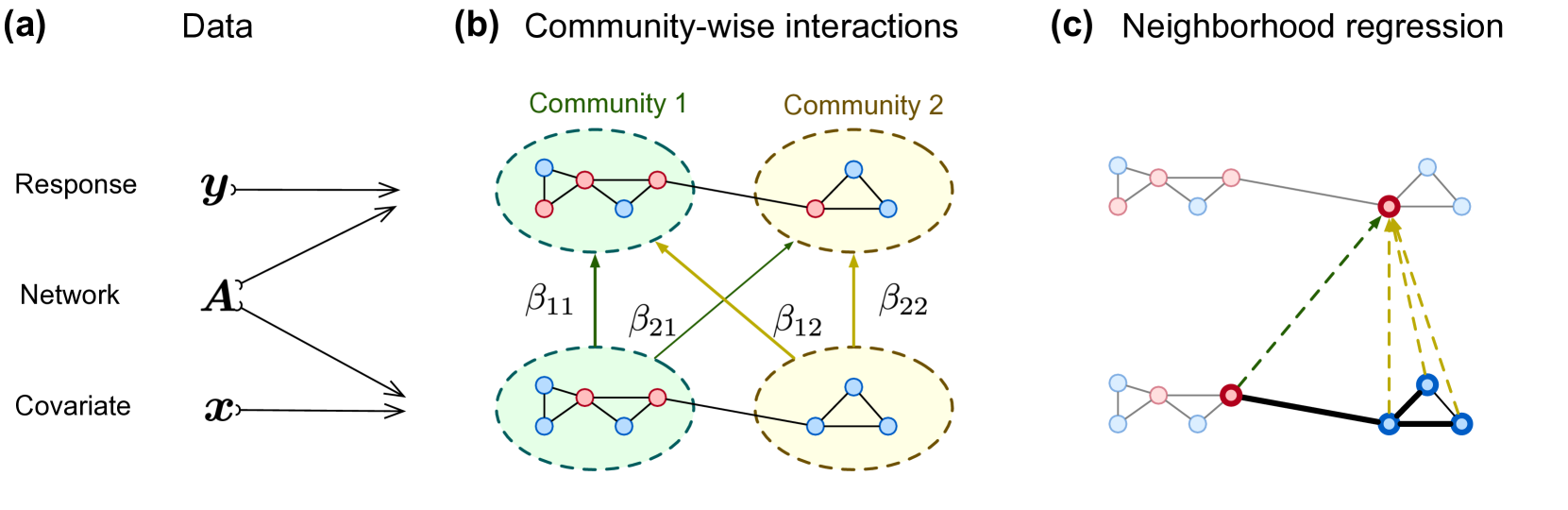
Given the ubiquity of modularity in biological systems, module-level regulation analysis is vital for understanding biological systems across various levels and their dynamics. Current statistical analysis on biological modules predominantly focuses on either detecting the functional modules in biological networks or sub-group regression on the biological features without using the network data. This paper proposes a novel network-based neighborhood regression framework whose regression functions depend on both the global community-level information and local connectivity structures among entities. An efficient community-wise least square optimization approach is developed to uncover the strength of regulation among the network modules while enabling asymptotic inference. With random graph theory, we derive non-asymptotic estimation error bounds for the proposed estimator, achieving exact minimax optimality. Unlike the root-n consistency typical in canonical linear regression, our model exhibits linear consistency in the number of nodes n, highlighting the advantage of incorporating neighborhood information. The effectiveness of the proposed framework is further supported by extensive numerical experiments. Application to whole-exome sequencing and RNA-sequencing Autism datasets demonstrates the usage of the proposed method in identifying the association between the gene modules of genetic variations and the gene modules of genomic differential expressions.
Read more7/8/2024

1
Network reconstruction via the minimum description length principle
Tiago P. Peixoto
A fundamental problem associated with the task of network reconstruction from dynamical or behavioral data consists in determining the most appropriate model complexity in a manner that prevents overfitting, and produces an inferred network with a statistically justifiable number of edges. The status quo in this context is based on $L_{1}$ regularization combined with cross-validation. However, besides its high computational cost, this commonplace approach unnecessarily ties the promotion of sparsity with weight shrinkage. This combination forces a trade-off between the bias introduced by shrinkage and the network sparsity, which often results in substantial overfitting even after cross-validation. In this work, we propose an alternative nonparametric regularization scheme based on hierarchical Bayesian inference and weight quantization, which does not rely on weight shrinkage to promote sparsity. Our approach follows the minimum description length (MDL) principle, and uncovers the weight distribution that allows for the most compression of the data, thus avoiding overfitting without requiring cross-validation. The latter property renders our approach substantially faster to employ, as it requires a single fit to the complete data. As a result, we have a principled and efficient inference scheme that can be used with a large variety of generative models, without requiring the number of edges to be known in advance. We also demonstrate that our scheme yields systematically increased accuracy in the reconstruction of both artificial and empirical networks. We highlight the use of our method with the reconstruction of interaction networks between microbial communities from large-scale abundance samples involving in the order of $10^{4}$ to $10^{5}$ species, and demonstrate how the inferred model can be used to predict the outcome of interventions in the system.
Read more5/8/2024
🧠
0
Neural networks for geospatial data
Wentao Zhan, Abhirup Datta
Analysis of geospatial data has traditionally been model-based, with a mean model, customarily specified as a linear regression on the covariates, and a covariance model, encoding the spatial dependence. We relax the strong assumption of linearity and propose embedding neural networks directly within the traditional geostatistical models to accommodate non-linear mean functions while retaining all other advantages including use of Gaussian Processes to explicitly model the spatial covariance, enabling inference on the covariate effect through the mean and on the spatial dependence through the covariance, and offering predictions at new locations via kriging. We propose NN-GLS, a new neural network estimation algorithm for the non-linear mean in GP models that explicitly accounts for the spatial covariance through generalized least squares (GLS), the same loss used in the linear case. We show that NN-GLS admits a representation as a special type of graph neural network (GNN). This connection facilitates use of standard neural network computational techniques for irregular geospatial data, enabling novel and scalable mini-batching, backpropagation, and kriging schemes. Theoretically, we show that NN-GLS will be consistent for irregularly observed spatially correlated data processes. We also provide a finite sample concentration rate, which quantifies the need to accurately model the spatial covariance in neural networks for dependent data. To our knowledge, these are the first large-sample results for any neural network algorithm for irregular spatial data. We demonstrate the methodology through simulated and real datasets.
Read more5/28/2024
0
Leveraging advances in machine learning for the robust classification and interpretation of networks
Raima Carol Appaw, Nicholas Fountain-Jones, Michael A. Charleston
The ability to simulate realistic networks based on empirical data is an important task across scientific disciplines, from epidemiology to computer science. Often simulation approaches involve selecting a suitable network generative model such as Erdos-R'enyi or small-world. However, few tools are available to quantify if a particular generative model is suitable for capturing a given network structure or organization. We utilize advances in interpretable machine learning to classify simulated networks by our generative models based on various network attributes, using both primary features and their interactions. Our study underscores the significance of specific network features and their interactions in distinguishing generative models, comprehending complex network structures, and the formation of real-world networks.
Read more6/13/2024