NeuraLUT: Hiding Neural Network Density in Boolean Synthesizable Functions

0
🧠
Sign in to get full access
Overview
- FPGA accelerators have proven successful in handling latency- and resource-critical deep neural network (DNN) inference tasks
- The dot product between feature and weight vectors is a computationally intensive operation in neural networks
- Previous FPGA acceleration works have mapped neurons with quantized inputs and outputs directly to lookup tables (LUTs)
- This paper proposes relaxing the boundaries between neurons and mapping entire sub-networks to a single LUT
Plain English Explanation
Field-Programmable Gate Arrays (FPGAs) are a type of hardware that can be programmed to perform specialized tasks. Researchers have found that FPGAs are particularly good at running certain types of machine learning models, called deep neural networks, quickly and efficiently.
One of the most computationally intensive parts of a neural network is the dot product calculation, where the input values are multiplied by the trained weights and then added up. Previous work has tried to simplify this calculation by mapping individual neurons (the building blocks of neural networks) directly to lookup tables (LUTs) on the FPGA.
This paper takes a different approach. Instead of mapping individual neurons, it maps entire sub-networks of the neural network to a single LUT. This means that the boundaries between neurons don't have to exactly match the boundaries of the LUTs. This allows the researchers to use more flexible, high-precision calculations within each sub-network, while still enforcing rigid sparsity and quantization between the sub-networks.
The benefit of this approach is that it can create very deep neural networks that run much faster on the FPGA hardware. To address potential issues with very deep networks, like vanishing gradients, the researchers also introduce skip connections within each sub-network.
Technical Explanation
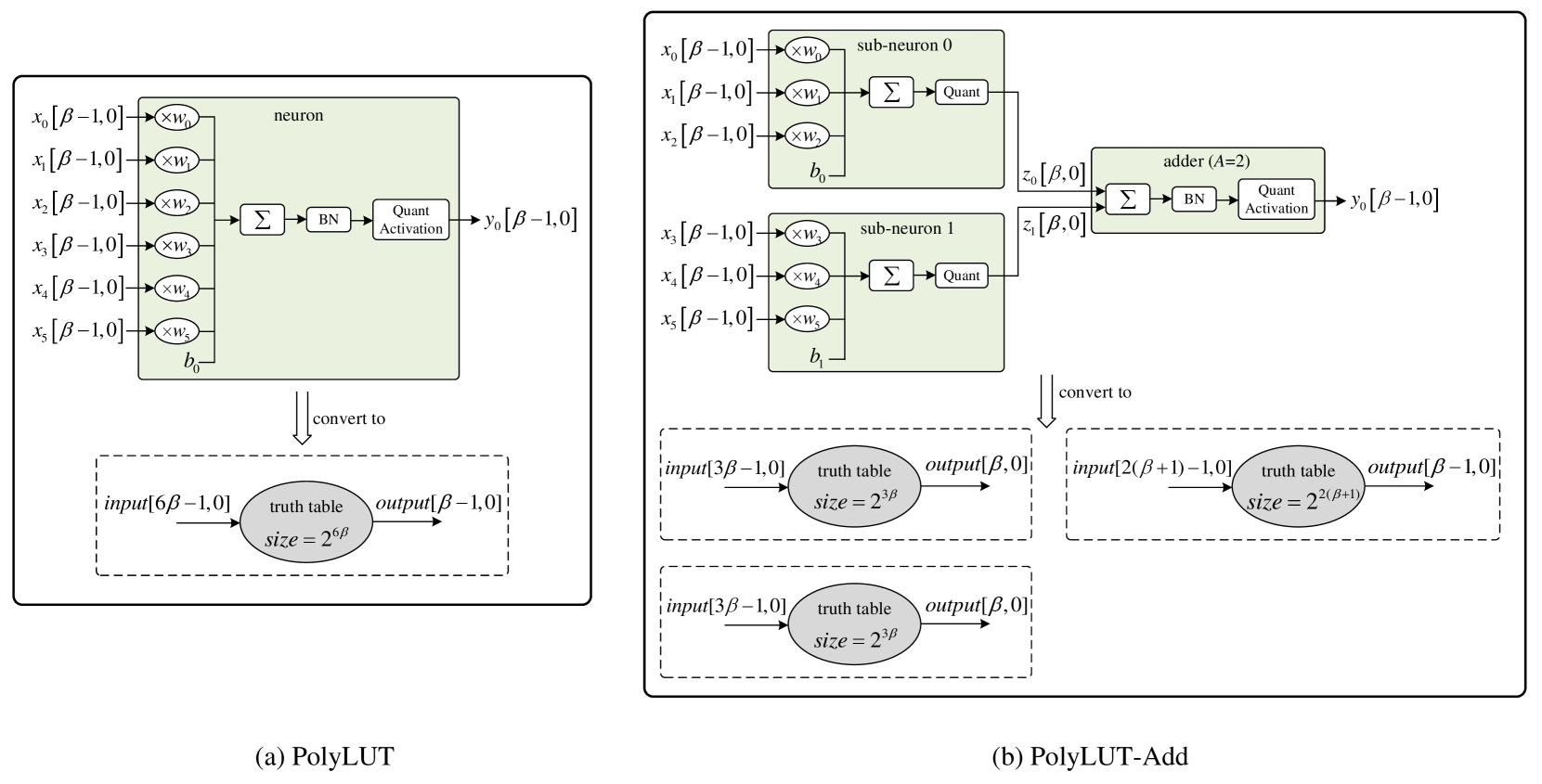
The authors propose a method called PolyLUT that relaxes the boundaries between neurons and maps entire sub-networks to a single lookup table (LUT) on an FPGA. This allows them to utilize fully connected layers with floating-point precision inside each partition, benefiting from the universal function approximation capabilities, while enforcing rigid sparsity and quantization between partitions, where the neural network (NN) topology becomes exposed to the circuit topology.
Unlike previous work that mapped neurons with quantized inputs and outputs directly to LUTs, such as Exploring Quantization-Mapping Synergy for Hardware-Aware Deep Learning, the PolyLUT approach does not constrain the NN topology and precision within a partition. This leads to very deep NNs, so the authors introduce skip connections inside the partitions to tackle challenges like vanishing gradients, similar to techniques used in Fast Algorithms for Spiking Neural Network Simulation on FPGAs.
The authors validate their proposed method on a latency-critical task, jet substructure tagging, and on the classical computer vision task of digit classification using MNIST. Their approach allows for greater function expressivity within the LUTs compared to existing work, leading to up to 4.3x lower latency NNs for the same accuracy.
Critical Analysis
The paper presents a novel approach to mapping neural networks to FPGA hardware, which offers significant performance improvements over previous methods. However, there are a few potential limitations and areas for further research worth considering:
-
The paper does not provide detailed comparisons to other state-of-the-art FPGA acceleration techniques, such as Measurement-Driven Neural Network Training for Integrated Magnetic Sensor Diagnostics. Comparing the PolyLUT approach to a wider range of existing methods could help better contextualize the contributions.
-
The experiments are limited to relatively simple tasks like jet substructure tagging and MNIST. Evaluating the PolyLUT approach on more complex, real-world deep learning tasks would help demonstrate its broader applicability and advantages.
-
The paper does not discuss the potential trade-offs between the improved latency and other important metrics, such as power consumption or resource utilization on the FPGA. Understanding these trade-offs would be helpful for assessing the practicality of the PolyLUT method in different deployment scenarios.
-
The authors mention that the NN topology and precision within a partition do not affect the size of the lookup tables generated. However, it's unclear how the actual size and complexity of the LUTs scale as the sub-network size and depth increase. Further analysis of the LUT resource requirements would provide valuable insights.
Overall, the PolyLUT approach presented in this paper represents an interesting and promising direction for accelerating deep neural networks on FPGA hardware. The authors have demonstrated significant latency improvements, but more comprehensive evaluations and comparisons could further strengthen the contributions of this work.
Conclusion
This paper introduces a novel technique called PolyLUT that relaxes the boundaries between neurons in a deep neural network and maps entire sub-networks to a single lookup table (LUT) on a Field-Programmable Gate Array (FPGA). This approach allows for greater function expressivity within the LUTs compared to previous methods that directly mapped individual neurons.
By utilizing fully connected layers with floating-point precision inside each partition, the PolyLUT method can create very deep neural networks that run much faster on FPGA hardware. To address potential issues with deep networks, the authors also incorporate skip connections within each sub-network.
The researchers validate their approach on two tasks: jet substructure tagging and MNIST digit classification. Their results demonstrate up to 4.3x lower latency for the same accuracy compared to existing FPGA acceleration techniques. This work represents an important advancement in the field of FPGA-based deep learning acceleration and could have significant implications for latency-critical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
NeuraLUT: Hiding Neural Network Density in Boolean Synthesizable Functions
Marta Andronic, George A. Constantinides
Field-Programmable Gate Array (FPGA) accelerators have proven successful in handling latency- and resource-critical deep neural network (DNN) inference tasks. Among the most computationally intensive operations in a neural network (NN) is the dot product between the feature and weight vectors. Thus, some previous FPGA acceleration works have proposed mapping neurons with quantized inputs and outputs directly to lookup tables (LUTs) for hardware implementation. In these works, the boundaries of the neurons coincide with the boundaries of the LUTs. We propose relaxing these boundaries and mapping entire sub-networks to a single LUT. As the sub-networks are absorbed within the LUT, the NN topology and precision within a partition do not affect the size of the lookup tables generated. Therefore, we utilize fully connected layers with floating-point precision inside each partition, which benefit from being universal function approximators, but with rigid sparsity and quantization enforced between partitions, where the NN topology becomes exposed to the circuit topology. Although cheap to implement, this approach can lead to very deep NNs, and so to tackle challenges like vanishing gradients, we also introduce skip connections inside the partitions. The resulting methodology can be seen as training DNNs with a specific FPGA hardware-inspired sparsity pattern that allows them to be mapped to much shallower circuit-level networks, thereby significantly improving latency. We validate our proposed method on a known latency-critical task, jet substructure tagging, and on the classical computer vision task, digit classification using MNIST. Our approach allows for greater function expressivity within the LUTs compared to existing work, leading to up to $4.3times$ lower latency NNs for the same accuracy.
Read more7/4/2024
0
PolyLUT-Add: FPGA-based LUT Inference with Wide Inputs
Binglei Lou, Richard Rademacher, David Boland, Philip H. W. Leong
FPGAs have distinct advantages as a technology for deploying deep neural networks (DNNs) at the edge. Lookup Table (LUT) based networks, where neurons are directly modeled using LUTs, help maximize this promise of offering ultra-low latency and high area efficiency on FPGAs. Unfortunately, LUT resource usage scales exponentially with the number of inputs to the LUT, restricting PolyLUT to small LUT sizes. This work introduces PolyLUT-Add, a technique that enhances neuron connectivity by combining $A$ PolyLUT sub-neurons via addition to improve accuracy. Moreover, we describe a novel architecture to improve its scalability. We evaluated our implementation over the MNIST, Jet Substructure classification, and Network Intrusion Detection benchmark and found that for similar accuracy, PolyLUT-Add achieves a LUT reduction of $2.0-13.9times$ with a $1.2-1.6times$ decrease in latency.
Read more9/17/2024

0
Low-latency machine learning FPGA accelerator for multi-qubit state discrimination
Pradeep Kumar Gautam, Shantharam Kalipatnapu, Shankaranarayanan H, Ujjawal Singhal, Benjamin Lienhard, Vibhor Singh, Chetan Singh Thakur
Measuring a qubit state is a fundamental yet error-prone operation in quantum computing. These errors can arise from various sources, such as crosstalk, spontaneous state transitions, and excitations caused by the readout pulse. Here, we utilize an integrated approach to deploy neural networks onto field-programmable gate arrays (FPGA). We demonstrate that implementing a fully connected neural network accelerator for multi-qubit readout is advantageous, balancing computational complexity with low latency requirements without significant loss in accuracy. The neural network is implemented by quantizing weights, activation functions, and inputs. The hardware accelerator performs frequency-multiplexed readout of five superconducting qubits in less than 50 ns on a radio frequency system on chip (RFSoC) ZCU111 FPGA, marking the advent of RFSoC-based low-latency multi-qubit readout using neural networks. These modules can be implemented and integrated into existing quantum control and readout platforms, making the RFSoC ZCU111 ready for experimental deployment.
Read more8/16/2024
0
Exploring Quantization and Mapping Synergy in Hardware-Aware Deep Neural Network Accelerators
Jan Klhufek, Miroslav Safar, Vojtech Mrazek, Zdenek Vasicek, Lukas Sekanina
Energy efficiency and memory footprint of a convolutional neural network (CNN) implemented on a CNN inference accelerator depend on many factors, including a weight quantization strategy (i.e., data types and bit-widths) and mapping (i.e., placement and scheduling of DNN elementary operations on hardware units of the accelerator). We show that enabling rich mixed quantization schemes during the implementation can open a previously hidden space of mappings that utilize the hardware resources more effectively. CNNs utilizing quantized weights and activations and suitable mappings can significantly improve trade-offs among the accuracy, energy, and memory requirements compared to less carefully optimized CNN implementations. To find, analyze, and exploit these mappings, we: (i) extend a general-purpose state-of-the-art mapping tool (Timeloop) to support mixed quantization, which is not currently available; (ii) propose an efficient multi-objective optimization algorithm to find the most suitable bit-widths and mapping for each DNN layer executed on the accelerator; and (iii) conduct a detailed experimental evaluation to validate the proposed method. On two CNNs (MobileNetV1 and MobileNetV2) and two accelerators (Eyeriss and Simba) we show that for a given quality metric (such as the accuracy on ImageNet), energy savings are up to 37% without any accuracy drop.
Read more4/9/2024