PolyLUT-Add: FPGA-based LUT Inference with Wide Inputs

0
Sign in to get full access
Overview
- This paper introduces PolyLUT-Add, a novel FPGA-based approach for accelerating neural network inference using wide input lookup tables (LUTs).
- The key idea is to represent non-linear activation functions as piecewise polynomial functions, which can then be efficiently implemented using FPGA LUTs with wide inputs.
- The authors demonstrate significant performance and efficiency gains compared to existing FPGA-based inference approaches, especially for neural networks with large input sizes.
Plain English Explanation
The paper describes a new way to speed up the process of running neural networks on specialized hardware called FPGAs. Neural networks are a type of AI algorithm that can be very computationally intensive, especially when the input data is large.
The main innovation in this work is a technique called PolyLUT-Add, which uses a special type of FPGA component called a lookup table (LUT) to approximate the non-linear activation functions in neural networks. Instead of using a traditional LUT, the authors represent these functions as piecewise polynomial equations, which allows them to use wider LUT inputs and achieve much higher performance.
This is important because many real-world AI applications, like computer vision and natural language processing, require processing large inputs. The authors show that their PolyLUT-Add approach can provide significant speedups and energy savings compared to previous FPGA-based neural network acceleration methods, especially for these large-input scenarios.
In summary, this research provides a new way to run neural networks more efficiently on specialized hardware, which could enable faster and more power-efficient AI applications in the future.
Technical Explanation
The core idea behind PolyLUT-Add is to represent non-linear activation functions, like ReLU or sigmoid, using piecewise polynomial approximations. These polynomial functions can then be efficiently implemented using FPGA LUTs with wide input widths, leveraging the high parallelism and energy efficiency of FPGA hardware.
The authors first describe how to construct these piecewise polynomial approximations, using a genetic algorithm-based optimization approach to find the best coefficients. They then show how to integrate these polynomial LUTs (PolyLUTs) into a full neural network inference pipeline on an FPGA, including techniques for efficiently combining multiple PolyLUT computations.
Through a series of experiments, the authors demonstrate the benefits of PolyLUT-Add compared to prior FPGA-based techniques, such as Hundred-Kilobyte Lookup Tables for Efficient Single-Image Super-Resolution and Understanding the Potential of FPGA-Based Spatial Acceleration for Large Neural Networks. They show significant improvements in inference throughput and energy efficiency, especially for neural networks with large input sizes.
The authors also discuss some limitations of their approach, such as the potential for increased memory usage due to the wider PolyLUT inputs. They suggest directions for future work, including exploring Genetic Quantization-Aware Approximation of Non-Linear Operations and Grokking Modular Polynomials to further improve the polynomial approximations.
Critical Analysis
The PolyLUT-Add approach presented in this paper is a clever and well-executed optimization for FPGA-based neural network inference. The authors demonstrate impressive performance gains, especially for large-input scenarios, which is an important use case for many real-world AI applications.
However, the paper does not address some potential limitations or areas for further research. For example, the increased memory usage due to the wider PolyLUT inputs could be a concern, especially for resource-constrained FPGA platforms. The authors also do not discuss the impact of their approach on model accuracy, which is a critical consideration for deploying AI systems in real-world applications.
Additionally, it would be interesting to see a comparison to other emerging FPGA acceleration techniques, such as the Fourier Circuits for Neural Networks approach, which also aims to leverage the unique capabilities of FPGA hardware.
Overall, the PolyLUT-Add research represents a valuable contribution to the field of FPGA-based neural network acceleration. However, further investigation into the practical implications and trade-offs of this approach would be helpful for researchers and practitioners looking to deploy efficient AI systems on specialized hardware.
Conclusion
The PolyLUT-Add paper introduces a novel FPGA-based technique for accelerating neural network inference, particularly for large-input scenarios. By representing activation functions as piecewise polynomial approximations, the authors are able to leverage wide FPGA lookup tables to achieve significant performance and efficiency gains compared to prior approaches.
This research demonstrates the potential of specialized hardware, like FPGAs, to enable more efficient AI applications in the real world. While the paper does not address all potential limitations, it provides a compelling solution to the challenge of running large neural networks on resource-constrained platforms.
As the field of AI continues to advance, techniques like PolyLUT-Add will likely play an important role in bringing powerful machine learning models to a wide range of applications, from computer vision to natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PolyLUT-Add: FPGA-based LUT Inference with Wide Inputs
Binglei Lou, Richard Rademacher, David Boland, Philip H. W. Leong
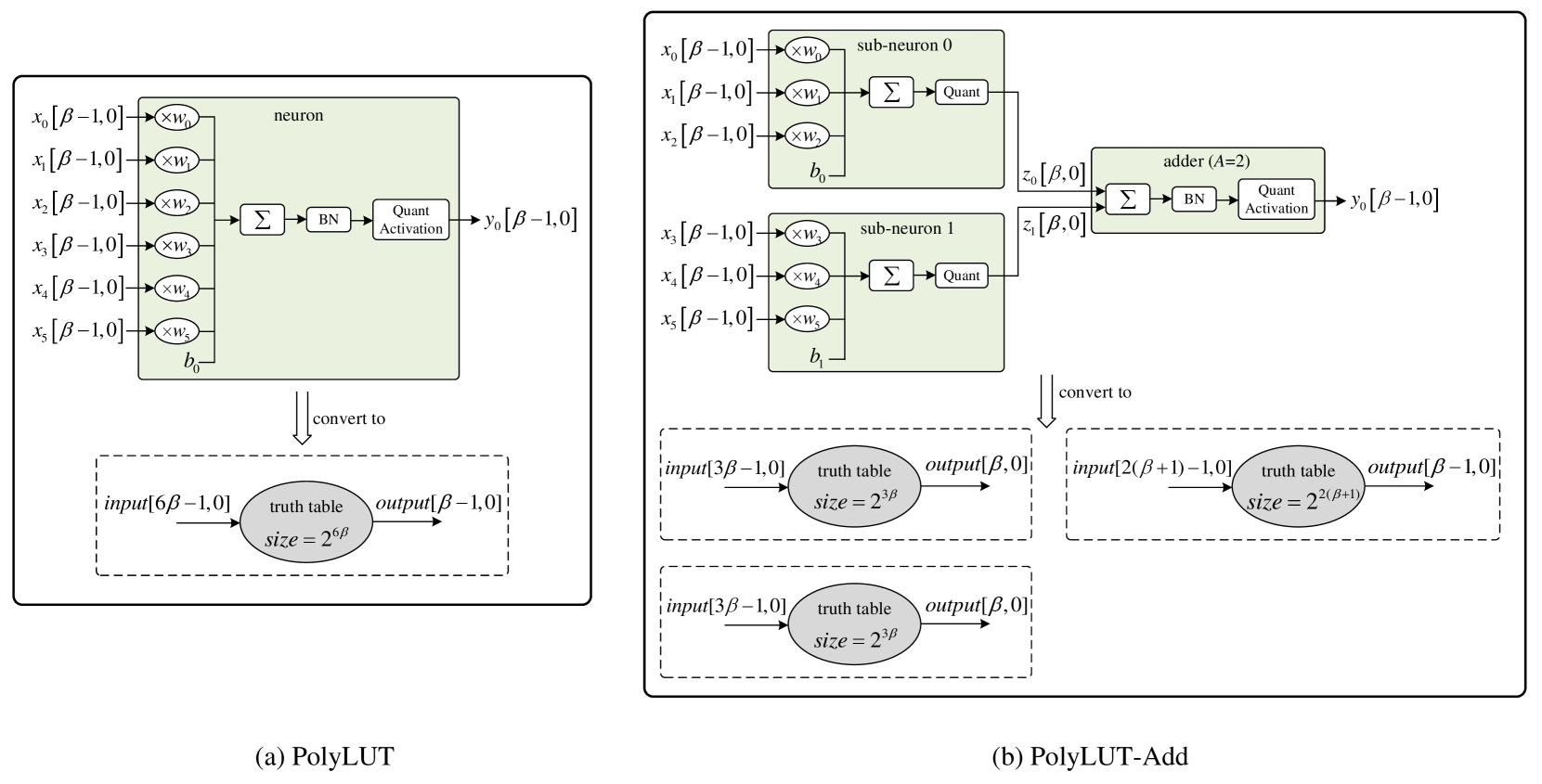
FPGAs have distinct advantages as a technology for deploying deep neural networks (DNNs) at the edge. Lookup Table (LUT) based networks, where neurons are directly modeled using LUTs, help maximize this promise of offering ultra-low latency and high area efficiency on FPGAs. Unfortunately, LUT resource usage scales exponentially with the number of inputs to the LUT, restricting PolyLUT to small LUT sizes. This work introduces PolyLUT-Add, a technique that enhances neuron connectivity by combining $A$ PolyLUT sub-neurons via addition to improve accuracy. Moreover, we describe a novel architecture to improve its scalability. We evaluated our implementation over the MNIST, Jet Substructure classification, and Network Intrusion Detection benchmark and found that for similar accuracy, PolyLUT-Add achieves a LUT reduction of $2.0-13.9times$ with a $1.2-1.6times$ decrease in latency.
Read more9/17/2024
🧠
0
NeuraLUT: Hiding Neural Network Density in Boolean Synthesizable Functions
Marta Andronic, George A. Constantinides
Field-Programmable Gate Array (FPGA) accelerators have proven successful in handling latency- and resource-critical deep neural network (DNN) inference tasks. Among the most computationally intensive operations in a neural network (NN) is the dot product between the feature and weight vectors. Thus, some previous FPGA acceleration works have proposed mapping neurons with quantized inputs and outputs directly to lookup tables (LUTs) for hardware implementation. In these works, the boundaries of the neurons coincide with the boundaries of the LUTs. We propose relaxing these boundaries and mapping entire sub-networks to a single LUT. As the sub-networks are absorbed within the LUT, the NN topology and precision within a partition do not affect the size of the lookup tables generated. Therefore, we utilize fully connected layers with floating-point precision inside each partition, which benefit from being universal function approximators, but with rigid sparsity and quantization enforced between partitions, where the NN topology becomes exposed to the circuit topology. Although cheap to implement, this approach can lead to very deep NNs, and so to tackle challenges like vanishing gradients, we also introduce skip connections inside the partitions. The resulting methodology can be seen as training DNNs with a specific FPGA hardware-inspired sparsity pattern that allows them to be mapped to much shallower circuit-level networks, thereby significantly improving latency. We validate our proposed method on a known latency-critical task, jet substructure tagging, and on the classical computer vision task, digit classification using MNIST. Our approach allows for greater function expressivity within the LUTs compared to existing work, leading to up to $4.3times$ lower latency NNs for the same accuracy.
Read more7/4/2024
0
Taming Lookup Tables for Efficient Image Retouching
Sidi Yang, Binxiao Huang, Mingdeng Cao, Yatai Ji, Hanzhong Guo, Ngai Wong, Yujiu Yang
The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.
Read more7/16/2024

0
Fast, Scalable, Energy-Efficient Non-element-wise Matrix Multiplication on FPGA
Xuqi Zhu, Huaizhi Zhang, JunKyu Lee, Jiacheng Zhu, Chandrajit Pal, Sangeet Saha, Klaus D. McDonald-Maier, Xiaojun Zhai
Modern Neural Network (NN) architectures heavily rely on vast numbers of multiply-accumulate arithmetic operations, constituting the predominant computational cost. Therefore, this paper proposes a high-throughput, scalable and energy efficient non-element-wise matrix multiplication unit on FPGAs as a basic component of the NNs. We firstly streamline inter-layer and intra-layer redundancies of MADDNESS algorithm, a LUT-based approximate matrix multiplication, to design a fast, efficient scalable approximate matrix multiplication module termed Approximate Multiplication Unit (AMU). The AMU optimizes LUT-based matrix multiplications further through dedicated memory management and access design, decoupling computational overhead from input resolution and boosting FPGA-based NN accelerator efficiency significantly. The experimental results show that using our AMU achieves up to 9x higher throughput and 112x higher energy efficiency over the state-of-the-art solutions for the FPGA-based Quantised Neural Network (QNN) accelerators.
Read more7/9/2024