A New Perspective on Speaker Verification: Joint Modeling with DFSMN and Transformer

0
Sign in to get full access
Overview
- The paper proposes a novel speaker verification model called VOT (Verification with memory and Attention) that leverages memory and attention mechanisms.
- VOT aims to improve speaker verification performance by capturing long-term speaker characteristics and dynamically focusing on relevant speech features.
- The model is evaluated on several speaker verification benchmarks and demonstrates state-of-the-art results.
Plain English Explanation
The paper introduces a new approach to speaker verification, which is the task of determining whether a voice sample belongs to a particular individual. The key innovation is the use of memory and attention mechanisms.
The memory component allows the model to store and recall long-term characteristics of a speaker's voice, rather than just analyzing each sample in isolation. The attention mechanism enables the model to focus on the most relevant parts of the speech signal when making its verification decision.
By combining these techniques, the VOT model is able to make more accurate speaker verification decisions compared to previous approaches. This could have important applications in areas like voice-based authentication, security, and personalization.
Technical Explanation
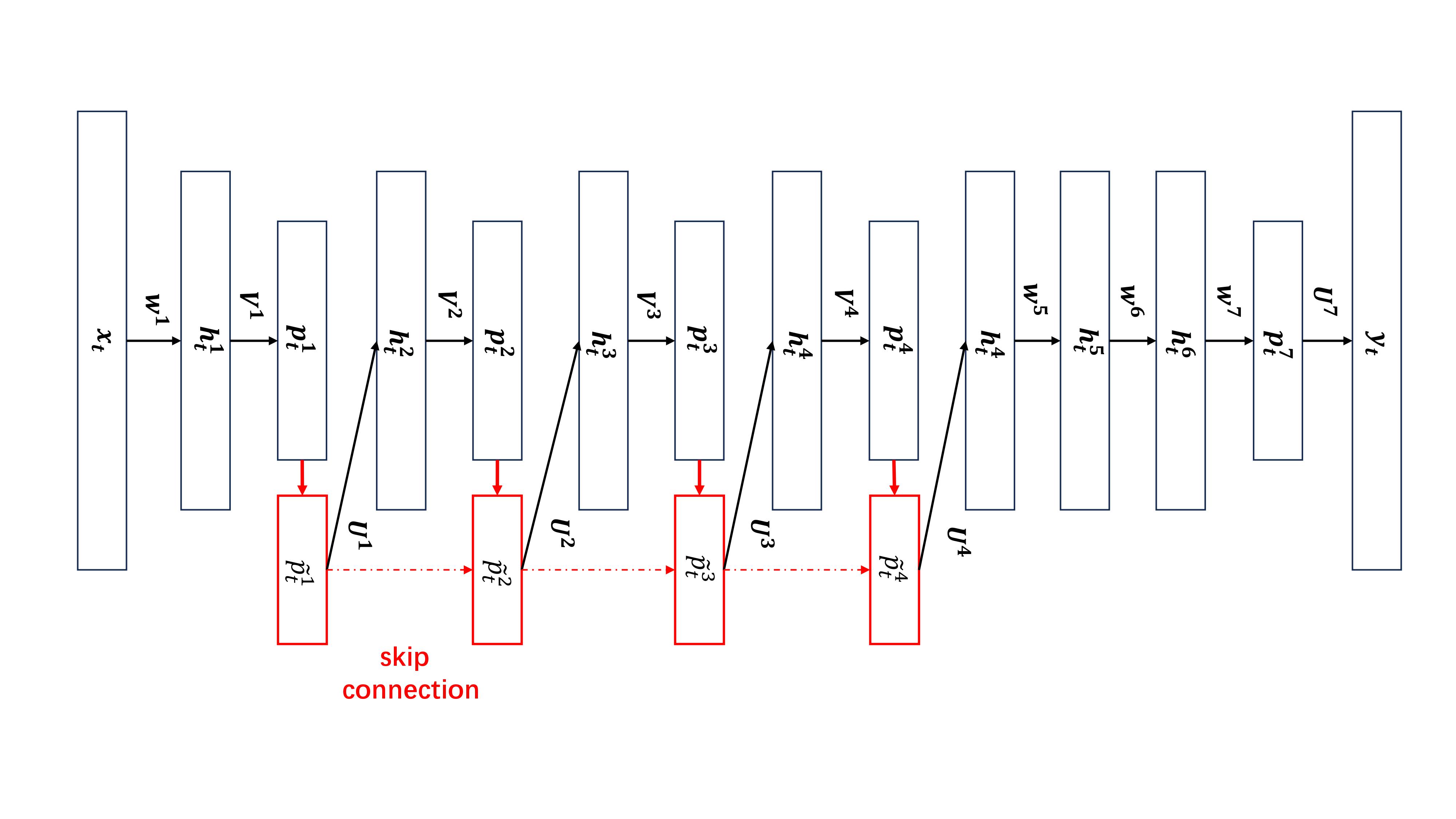
The core of the VOT model is a neural network architecture that includes both a memory module and an attention module. The memory module stores long-term representations of speakers, which helps the model capture persistent voice characteristics. The attention module dynamically focuses on the most relevant parts of the input speech signal when making the verification decision.
Specifically, the memory module is implemented as a differentiable memory bank that can be read from and written to by the model. The attention module uses a weighted combination of the memory contents to generate a context vector that is then used alongside the input features to produce the final speaker verification output.
The VOT model is trained end-to-end on speaker verification datasets using a combination of classification and contrastive loss functions. Extensive experiments show that VOT outperforms previous state-of-the-art speaker verification approaches on multiple benchmark datasets.
Critical Analysis
The paper provides a thorough evaluation of the VOT model and demonstrates its strong performance on speaker verification tasks. However, the authors acknowledge that the memory and attention mechanisms add additional complexity and computational cost compared to simpler models.
Additionally, the paper does not deeply explore the interpretability of the memory and attention components - it is not clear exactly what speaker characteristics the model is capturing and attending to. Further analysis in this area could help shed light on the inner workings of the model and potentially lead to additional performance improvements.
Finally, the experiments are limited to relatively clean speech data. It would be valuable to evaluate the robustness of VOT to more realistic scenarios with background noise, accents, and other real-world challenges.
Conclusion
Overall, the VOT model represents an important advance in speaker verification technology by leveraging memory and attention mechanisms. The strong empirical results suggest that this approach could have significant real-world impact, especially in security-critical applications that require reliable voice-based authentication. Further research to improve the model's interpretability and robustness could unlock even greater potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A New Perspective on Speaker Verification: Joint Modeling with DFSMN and Transformer
Hongyu Wang, Hui Li, Bo Li
Speaker verification is to judge the similarity between two unknown voices in an open set, where the ideal speaker embedding should be able to condense discriminant information into a compact utterance-level representation that has small intra-speaker distances and large inter-speaker distances. We propose Voice Transformer (VOT), a novel model for speaker verification, which integrates parallel transformers at multiple scales. A deep feedforward sequential memory network (DFSMN) is incorporated into the attention part of these transformers to increase feature granularity. The attentive statistics pooling layer is added to focus on important frames and form utterance-level features. We propose Additive Angular Margin Focal Loss (AAMF) to address the hard samples problem. We evaluate the proposed approach on the VoxCeleb1 and CN-Celeb2 datasets, demonstrating that VOT surpasses most mainstream models. The code is available on GitHubfootnote{url{https://github.com/luckyerr/Voice-Transformer_Speaker-Verification}}.
Read more9/10/2024

0
Spoofing-Robust Speaker Verification Using Parallel Embedding Fusion: BTU Speech Group's Approach for ASVspoof5 Challenge
Ou{g}uzhan Kurnaz, Selim Can Demirtac{s}, Aykut Buker, Jagabandhu Mishra, Cemal Hanilc{c}i
This paper introduces the parallel network-based spoofing-aware speaker verification (SASV) system developed by BTU Speech Group for the ASVspoof5 Challenge. The SASV system integrates ASV and CM systems to enhance security against spoofing attacks. Our approach employs score and embedding fusion from ASV models (ECAPA-TDNN, WavLM) and CM models (AASIST). The fused embeddings are processed using a simple DNN structure, optimizing model performance with a combination of recently proposed a-DCF and BCE losses. We introduce a novel parallel network structure where two identical DNNs, fed with different inputs, independently process embeddings and produce SASV scores. The final SASV probability is derived by averaging these scores, enhancing robustness and accuracy. Experimental results demonstrate that the proposed parallel DNN structure outperforms traditional single DNN methods, offering a more reliable and secure speaker verification system against spoofing attacks.
Read more8/29/2024

0
A Joint Noise Disentanglement and Adversarial Training Framework for Robust Speaker Verification
Xujiang Xing, Mingxing Xu, Thomas Fang Zheng
Automatic Speaker Verification (ASV) suffers from performance degradation in noisy conditions. To address this issue, we propose a novel adversarial learning framework that incorporates noise-disentanglement to establish a noise-independent speaker invariant embedding space. Specifically, the disentanglement module includes two encoders for separating speaker related and irrelevant information, respectively. The reconstruction module serves as a regularization term to constrain the noise. A feature-robust loss is also used to supervise the speaker encoder to learn noise-independent speaker embeddings without losing speaker information. In addition, adversarial training is introduced to discourage the speaker encoder from encoding acoustic condition information for achieving a speaker-invariant embedding space. Experiments on VoxCeleb1 indicate that the proposed method improves the performance of the speaker verification system under both clean and noisy conditions.
Read more8/23/2024
📈
0
Experimenting with Additive Margins for Contrastive Self-Supervised Speaker Verification
Theo Lepage, Reda Dehak
Most state-of-the-art self-supervised speaker verification systems rely on a contrastive-based objective function to learn speaker representations from unlabeled speech data. We explore different ways to improve the performance of these methods by: (1) revisiting how positive and negative pairs are sampled through a symmetric formulation of the contrastive loss; (2) introducing margins similar to AM-Softmax and AAM-Softmax that have been widely adopted in the supervised setting. We demonstrate the effectiveness of the symmetric contrastive loss which provides more supervision for the self-supervised task. Moreover, we show that Additive Margin and Additive Angular Margin allow reducing the overall number of false negatives and false positives by improving speaker separability. Finally, by combining both techniques and training a larger model we achieve 7.50% EER and 0.5804 minDCF on the VoxCeleb1 test set, which outperforms other contrastive self supervised methods on speaker verification.
Read more4/26/2024