No Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image Captioning

0

Sign in to get full access
Overview
- The paper introduces a new approach for fine-grained image captioning that leverages self-retrieval.
- It addresses challenges with the training data for image captioning models, such as lack of diversity and details.
- The proposed method aims to generate more accurate and detailed captions by retrieving relevant visual details from the image itself.
Plain English Explanation
The paper presents a new way to generate more descriptive captions for images. Current image captioning models often struggle to capture all the important details in an image, because the training data they use doesn't have enough variety and specificity.
The key idea is to have the model retrieve relevant visual information from the image itself and use that to produce more accurate and detailed captions. This helps address the limitations of the training data by allowing the model to "look back" at the image and focus on important visual elements that might otherwise be missed.
By revisiting the image during caption generation, the model can identify and describe fine-grained details that are essential for a full understanding of the scene. This makes the captions more informative and better aligned with the visual content.
Technical Explanation
The paper introduces a novel self-retrieval mechanism for fine-grained image captioning. The key idea is to have the captioning model dynamically retrieve relevant visual details from the input image during the caption generation process.
The proposed approach consists of two main components:
- Visual Retriever: This module learns to identify and extract important visual elements from the image that are relevant to the caption being generated.
- Caption Generator: This module takes the retrieved visual features and generates the final caption, leveraging the additional information to produce more accurate and detailed descriptions.
The visual retriever is trained to learn feature representations that can effectively capture fine-grained visual details. It uses a contrastive learning objective to align the retrieved features with the ground-truth captions.
During inference, the caption generator iteratively attends to the retrieved visual features, allowing it to focus on the most relevant aspects of the image when generating each word in the output caption.
The authors evaluate their method on standard image captioning benchmarks and show that it outperforms previous state-of-the-art approaches, particularly in terms of generating captions that are more faithful to the visual content of the image.
Critical Analysis
The paper presents a compelling approach to address the limitations of training data for image captioning models. By incorporating a self-retrieval mechanism, the model can dynamically access relevant visual details during caption generation, which helps it produce more accurate and informative descriptions.
However, the paper does not discuss potential limitations or caveats of the proposed method. For example, it would be interesting to understand how the self-retrieval mechanism performs in cases where the relevant visual details are not easily identifiable or salient within the image.
Additionally, the authors could have explored the trade-offs between the computational overhead of the retrieval process and the potential gains in caption quality. It's possible that the self-retrieval approach may not be scalable or efficient for real-world applications with large-scale image datasets.
Further research could also investigate the generalization capabilities of the self-retrieval mechanism, such as its performance on diverse image types or its ability to handle out-of-distribution samples. Exploring these aspects would help provide a more comprehensive understanding of the method's strengths and limitations.
Conclusion
This paper presents a novel approach to fine-grained image captioning that leverages a self-retrieval mechanism to dynamically access relevant visual details and generate more accurate and informative descriptions. By addressing the limitations of training data, the proposed method represents a significant advancement in the field of image captioning.
The self-retrieval technique could have broader implications for other vision-language tasks, such as multimodal understanding or retrieval-augmented generation. Further research and evaluation of the method's performance and scalability would help solidify its potential impact on the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
No Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image Captioning
Manu Gaur, Darshan Singh S, Makarand Tapaswi
Image captioning systems are unable to generate fine-grained captions as they are trained on data that is either noisy (alt-text) or generic (human annotations). This is further exacerbated by maximum likelihood training that encourages generation of frequently occurring phrases. Previous works have tried to address this limitation by fine-tuning captioners with a self-retrieval (SR) reward. However, we find that SR fine-tuning has a tendency to reduce caption faithfulness and even hallucinate. In this work, we circumvent this bottleneck by improving the MLE initialization of the captioning system and designing a curriculum for the SR fine-tuning process. To this extent, we present (1) Visual Caption Boosting, a novel framework to instill fine-grainedness in generic image captioning datasets while remaining anchored in human annotations; and (2) BagCurri, a carefully designed training curriculum that more optimally leverages the contrastive nature of the self-retrieval reward. Jointly, they enable the captioner to describe fine-grained aspects in the image while preserving faithfulness to ground-truth captions. Our approach outperforms previous work by +8.9% on SR against 99 random distractors (RD100) (Dessi et al., 2023); and +7.6% on ImageCoDe. Additionally, existing metrics to evaluate captioning systems fail to reward diversity or evaluate a model's fine-grained understanding ability. Our third contribution addresses this by proposing self-retrieval from the lens of evaluation. We introduce TrueMatch, a benchmark comprising bags of highly similar images that uses SR to assess the captioner's ability to capture subtle visual distinctions. We evaluate and compare several state-of-the-art open-source MLLMs on TrueMatch, and find that our SR approach outperforms them all by a significant margin (e.g. +4.8% - 7.1% over Cambrian) while having 1-2 orders of magnitude fewer parameters.
Read more9/6/2024
0
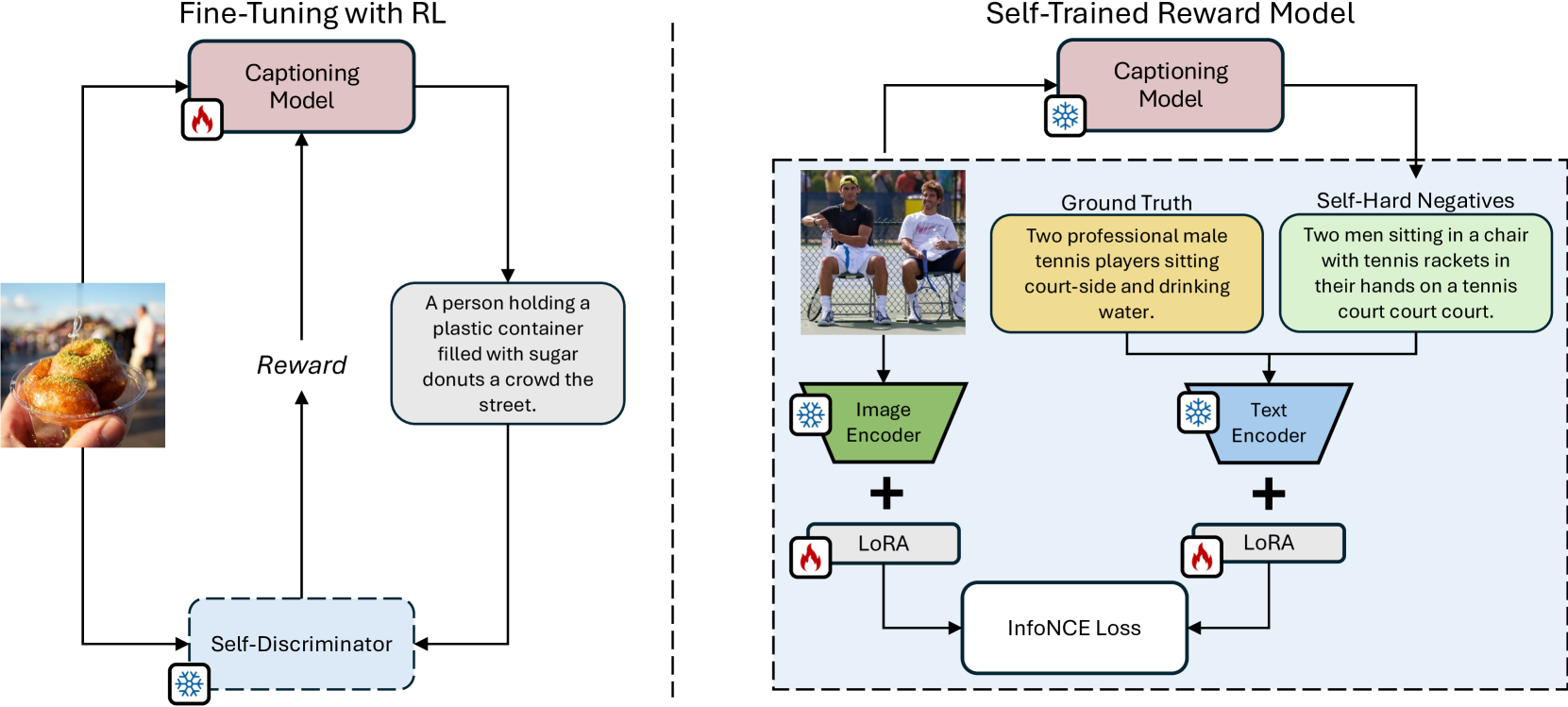
Fluent and Accurate Image Captioning with a Self-Trained Reward Model
Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
Fine-tuning image captioning models with hand-crafted rewards like the CIDEr metric has been a classical strategy for promoting caption quality at the sequence level. This approach, however, is known to limit descriptiveness and semantic richness and tends to drive the model towards the style of ground-truth sentences, thus losing detail and specificity. On the contrary, recent attempts to employ image-text models like CLIP as reward have led to grammatically incorrect and repetitive captions. In this paper, we propose Self-Cap, a captioning approach that relies on a learnable reward model based on self-generated negatives that can discriminate captions based on their consistency with the image. Specifically, our discriminator is a fine-tuned contrastive image-text model trained to promote caption correctness while avoiding the aberrations that typically happen when training with a CLIP-based reward. To this end, our discriminator directly incorporates negative samples from a frozen captioner, which significantly improves the quality and richness of the generated captions but also reduces the fine-tuning time in comparison to using the CIDEr score as the sole metric for optimization. Experimental results demonstrate the effectiveness of our training strategy on both standard and zero-shot image captioning datasets.
Read more9/2/2024

0
Understanding Retrieval Robustness for Retrieval-Augmented Image Captioning
Wenyan Li, Jiaang Li, Rita Ramos, Raphael Tang, Desmond Elliott
Recent advances in retrieval-augmented models for image captioning highlight the benefit of retrieving related captions for efficient, lightweight models with strong domain-transfer capabilities. While these models demonstrate the success of retrieval augmentation, retrieval models are still far from perfect in practice: the retrieved information can sometimes mislead the model, resulting in incorrect generation and worse performance. In this paper, we analyze the robustness of a retrieval-augmented captioning model SmallCap. Our analysis shows that the model is sensitive to tokens that appear in the majority of the retrieved captions, and the input attribution shows that those tokens are likely copied into the generated output. Given these findings, we propose to train the model by sampling retrieved captions from more diverse sets. This decreases the chance that the model learns to copy majority tokens, and improves both in-domain and cross-domain performance.
Read more8/7/2024
🖼️
0
Towards Retrieval-Augmented Architectures for Image Captioning
Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Alessandro Nicolosi, Rita Cucchiara
The objective of image captioning models is to bridge the gap between the visual and linguistic modalities by generating natural language descriptions that accurately reflect the content of input images. In recent years, researchers have leveraged deep learning-based models and made advances in the extraction of visual features and the design of multimodal connections to tackle this task. This work presents a novel approach towards developing image captioning models that utilize an external kNN memory to improve the generation process. Specifically, we propose two model variants that incorporate a knowledge retriever component that is based on visual similarities, a differentiable encoder to represent input images, and a kNN-augmented language model to predict tokens based on contextual cues and text retrieved from the external memory. We experimentally validate our approach on COCO and nocaps datasets and demonstrate that incorporating an explicit external memory can significantly enhance the quality of captions, especially with a larger retrieval corpus. This work provides valuable insights into retrieval-augmented captioning models and opens up new avenues for improving image captioning at a larger scale.
Read more5/24/2024