Fluent and Accurate Image Captioning with a Self-Trained Reward Model

0
Sign in to get full access
Overview
- Presents a method for improving image captioning using a self-trained reward model
- Key idea is to train a reward model to score captions based on their similarity to ground truth captions, and then use this reward model to guide the training of the captioning model
- Experiments show this approach leads to more fluent and accurate captions compared to baseline methods
Plain English Explanation
The paper describes a technique for improving image captioning models, which are used to generate textual descriptions of images. The core idea is to train a separate "reward model" that can evaluate how good a caption is by comparing it to ground truth captions written by humans. This reward model is then used to guide the training of the main captioning model, rewarding it for generating captions that are similar to the high-quality human-written ones.
The researchers found that this approach leads to captions that are more fluent and accurate compared to prior methods. By leveraging the CLIP model, the reward model is able to effectively assess the quality of generated captions. This in turn helps the captioning model learn to produce more natural-sounding and informative descriptions.
Technical Explanation
The key components of the proposed approach are:
-
Reward Model: A separate neural network model is trained to evaluate the quality of image captions. This is done by fine-tuning a CLIP model on a dataset of image-caption pairs, allowing it to learn what makes a good caption.
-
Self-Supervised Training: The captioning model is trained using reinforcement learning, with the reward model providing the rewards. During training, the captioning model generates candidate captions, which are then scored by the reward model. The captioning model is then updated to generate captions that receive higher rewards.
-
Data Augmentation: To further improve the captioning model, the researchers use a retrieval-enhanced data augmentation technique. This involves retrieving relevant captions from a large corpus and using them to fine-tune the captioning model.
Through extensive experiments, the authors demonstrate that this approach leads to significant improvements in both caption fluency and accuracy, as measured by standard evaluation metrics. The self-trained reward model is shown to be more effective than alternatives like using human-written captions directly as the reward.
Critical Analysis
The paper presents a compelling approach for improving image captioning models, and the experimental results are quite strong. However, a few potential limitations or areas for further investigation are worth noting:
- The reliance on CLIP as the foundation for the reward model means the approach may be limited by CLIP's own biases and limitations. Exploring alternative ways to construct the reward model could be valuable.
- The data augmentation technique, while effective, raises questions about the model's ability to generalize to truly novel images and captions beyond the training distribution.
- The paper does not deeply explore the tradeoffs between fluency and accuracy, or discuss how the approach might perform on specific types of images or captions.
Overall, this is a well-executed piece of research that makes a meaningful contribution to the field of image captioning. Further investigation into the model's robustness and broader applicability could help strengthen the findings.
Conclusion
The authors present a novel approach for improving image captioning models by training a self-supervised reward model to guide the captioning model's training. This leads to captions that are more fluent and accurate than those produced by baseline methods. While the approach has some limitations, it represents an important step forward in developing high-quality image captioning systems with real-world applications in areas like visual assistance, content moderation, and multimedia indexing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fluent and Accurate Image Captioning with a Self-Trained Reward Model
Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
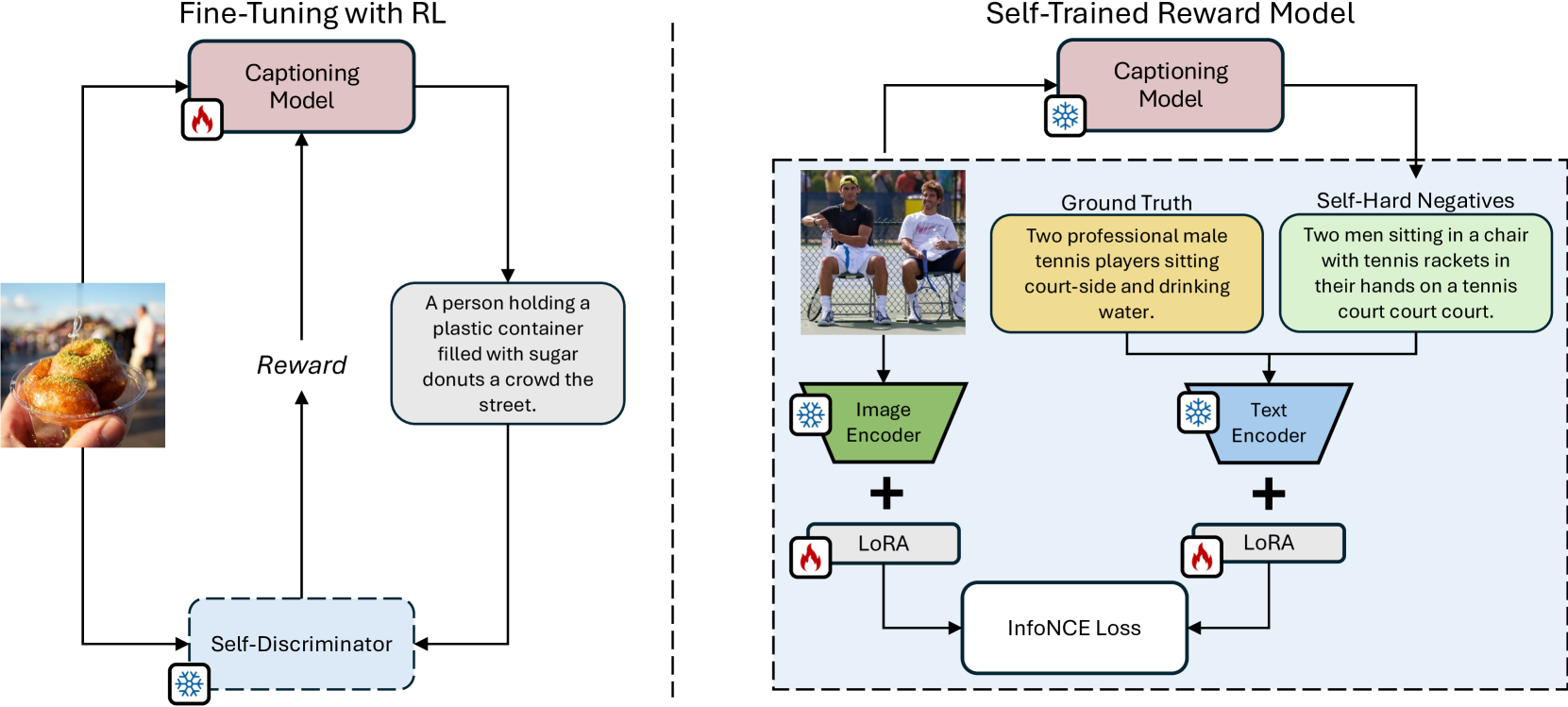
Fine-tuning image captioning models with hand-crafted rewards like the CIDEr metric has been a classical strategy for promoting caption quality at the sequence level. This approach, however, is known to limit descriptiveness and semantic richness and tends to drive the model towards the style of ground-truth sentences, thus losing detail and specificity. On the contrary, recent attempts to employ image-text models like CLIP as reward have led to grammatically incorrect and repetitive captions. In this paper, we propose Self-Cap, a captioning approach that relies on a learnable reward model based on self-generated negatives that can discriminate captions based on their consistency with the image. Specifically, our discriminator is a fine-tuned contrastive image-text model trained to promote caption correctness while avoiding the aberrations that typically happen when training with a CLIP-based reward. To this end, our discriminator directly incorporates negative samples from a frozen captioner, which significantly improves the quality and richness of the generated captions but also reduces the fine-tuning time in comparison to using the CIDEr score as the sole metric for optimization. Experimental results demonstrate the effectiveness of our training strategy on both standard and zero-shot image captioning datasets.
Read more9/2/2024

0
Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization
Nicholas Moratelli, Davide Caffagni, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
The conventional training approach for image captioning involves pre-training a network using teacher forcing and subsequent fine-tuning with Self-Critical Sequence Training to maximize hand-crafted captioning metrics. However, when attempting to optimize modern and higher-quality metrics like CLIP-Score and PAC-Score, this training method often encounters instability and fails to acquire the genuine descriptive capabilities needed to produce fluent and informative captions. In this paper, we propose a new training paradigm termed Direct CLIP-Based Optimization (DiCO). Our approach jointly learns and optimizes a reward model that is distilled from a learnable captioning evaluator with high human correlation. This is done by solving a weighted classification problem directly inside the captioner. At the same time, DiCO prevents divergence from the original model, ensuring that fluency is maintained. DiCO not only exhibits improved stability and enhanced quality in the generated captions but also aligns more closely with human preferences compared to existing methods, especially in modern metrics. Additionally, it maintains competitive performance in traditional metrics. Our source code and trained models are publicly available at https://github.com/aimagelab/DiCO.
Read more8/28/2024
🔄
0
Class-Conditional self-reward mechanism for improved Text-to-Image models
Safouane El Ghazouali, Arnaud Gucciardi, Umberto Michelucci
Self-rewarding have emerged recently as a powerful tool in the field of Natural Language Processing (NLP), allowing language models to generate high-quality relevant responses by providing their own rewards during training. This innovative technique addresses the limitations of other methods that rely on human preferences. In this paper, we build upon the concept of self-rewarding models and introduce its vision equivalent for Text-to-Image generative AI models. This approach works by fine-tuning diffusion model on a self-generated self-judged dataset, making the fine-tuning more automated and with better data quality. The proposed mechanism makes use of other pre-trained models such as vocabulary based-object detection, image captioning and is conditioned by the a set of object for which the user might need to improve generated data quality. The approach has been implemented, fine-tuned and evaluated on stable diffusion and has led to a performance that has been evaluated to be at least 60% better than existing commercial and research Text-to-image models. Additionally, the built self-rewarding mechanism allowed a fully automated generation of images, while increasing the visual quality of the generated images and also more efficient following of prompt instructions. The code used in this work is freely available on https://github.com/safouaneelg/SRT2I.
Read more5/28/2024

0
No Detail Left Behind: Revisiting Self-Retrieval for Fine-Grained Image Captioning
Manu Gaur, Darshan Singh S, Makarand Tapaswi
Image captioning systems are unable to generate fine-grained captions as they are trained on data that is either noisy (alt-text) or generic (human annotations). This is further exacerbated by maximum likelihood training that encourages generation of frequently occurring phrases. Previous works have tried to address this limitation by fine-tuning captioners with a self-retrieval (SR) reward. However, we find that SR fine-tuning has a tendency to reduce caption faithfulness and even hallucinate. In this work, we circumvent this bottleneck by improving the MLE initialization of the captioning system and designing a curriculum for the SR fine-tuning process. To this extent, we present (1) Visual Caption Boosting, a novel framework to instill fine-grainedness in generic image captioning datasets while remaining anchored in human annotations; and (2) BagCurri, a carefully designed training curriculum that more optimally leverages the contrastive nature of the self-retrieval reward. Jointly, they enable the captioner to describe fine-grained aspects in the image while preserving faithfulness to ground-truth captions. Our approach outperforms previous work by +8.9% on SR against 99 random distractors (RD100) (Dessi et al., 2023); and +7.6% on ImageCoDe. Additionally, existing metrics to evaluate captioning systems fail to reward diversity or evaluate a model's fine-grained understanding ability. Our third contribution addresses this by proposing self-retrieval from the lens of evaluation. We introduce TrueMatch, a benchmark comprising bags of highly similar images that uses SR to assess the captioner's ability to capture subtle visual distinctions. We evaluate and compare several state-of-the-art open-source MLLMs on TrueMatch, and find that our SR approach outperforms them all by a significant margin (e.g. +4.8% - 7.1% over Cambrian) while having 1-2 orders of magnitude fewer parameters.
Read more9/6/2024