No learning rates needed: Introducing SALSA -- Stable Armijo Line Search Adaptation

0
Sign in to get full access
Overview
- Introduces a new optimization algorithm called SALSA (Stable Armijo Line Search Adaptation)
- SALSA automatically adapts the step size without requiring manual tuning of learning rates
- Demonstrates improved performance and stability compared to existing optimization methods
Plain English Explanation
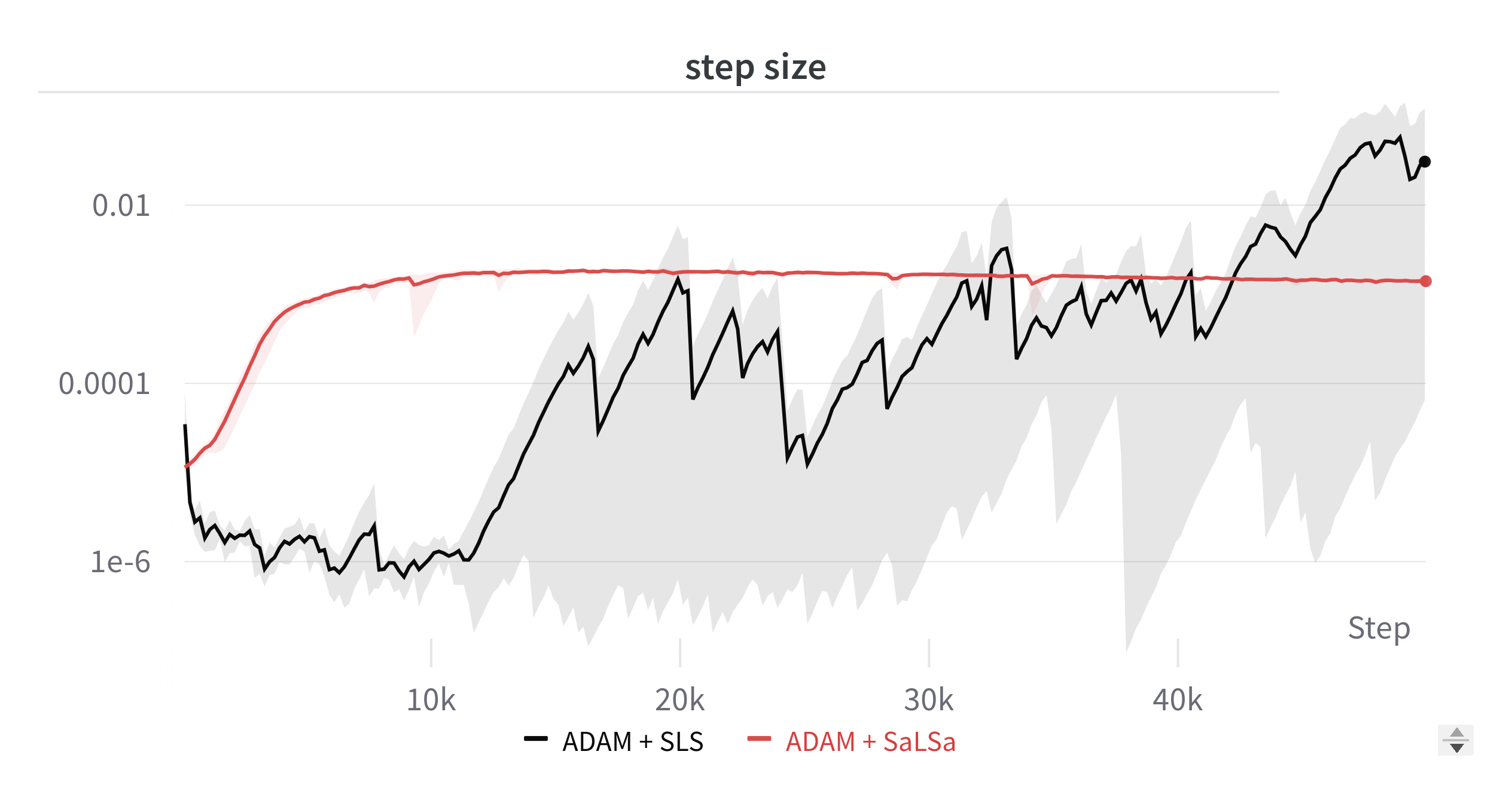
SALSA: Stable Armijo Line Search Adaptation is a new optimization algorithm that can automatically adjust the step size during training, eliminating the need for manual tuning of learning rates.
Traditionally, optimization algorithms like gradient descent require the user to carefully select an appropriate learning rate, which can be challenging and time-consuming. SALSA overcomes this by using an Armijo line search technique to dynamically adapt the step size during the optimization process.
This adaptive step size helps the algorithm converge more stably and efficiently compared to methods that use a fixed learning rate. SALSA also has theoretical guarantees for convergence, making it a robust and reliable optimization technique.
Technical Explanation
The core idea behind SALSA is to use an Armijo line search procedure to automatically determine the step size at each iteration of the optimization process. This eliminates the need for manual tuning of learning rates, which can be challenging and time-consuming.
The Armijo line search technique works by evaluating the function value at different step sizes along the descent direction and selecting the step size that satisfies the Armijo condition. This ensures that the step size is large enough to make significant progress, but not so large that it overshoots the minimum.
SALSA combines this Armijo line search with a stabilization technique to ensure that the step size remains within a reasonable range throughout the optimization. This helps to prevent the algorithm from getting stuck in regions where the step size is either too large or too small, leading to more stable and efficient convergence.
The authors provide theoretical analysis to show that SALSA has guaranteed convergence properties, making it a robust and reliable optimization algorithm. They also demonstrate the empirical performance of SALSA on a range of machine learning tasks, showing that it outperforms existing optimization methods in terms of both efficiency and stability.
Critical Analysis
The paper provides a solid theoretical and empirical analysis of the SALSA algorithm, and the authors make a convincing case for its advantages over existing optimization methods. However, there are a few potential areas for further research:
-
Computational Efficiency: While SALSA eliminates the need for manual tuning of learning rates, the Armijo line search procedure may introduce additional computational overhead compared to simpler optimization methods. The authors should investigate the computational cost of SALSA and explore ways to improve its efficiency.
-
Practical Considerations: The paper focuses on the theoretical properties and empirical performance of SALSA, but it would be helpful to have more discussion on the practical aspects of using the algorithm, such as how to initialize the step size, how to handle different problem types or varying levels of noise in the data, and how to integrate SALSA with other techniques like momentum or adaptive gradient methods.
-
Generalization to Constrained Optimization: The current formulation of SALSA is limited to unconstrained optimization problems. It would be interesting to explore how the algorithm can be extended to handle constrained optimization problems, which are common in many real-world applications.
Overall, the SALSA algorithm appears to be a promising contribution to the field of optimization, and the authors have done a commendable job in presenting the technical details and empirical results. Further research and practical applications of SALSA could lead to valuable insights and advancements in optimization techniques.
Conclusion
The SALSA algorithm introduced in this paper is a significant advancement in optimization techniques, as it eliminates the need for manual tuning of learning rates while maintaining strong theoretical guarantees and empirical performance. By leveraging an Armijo line search with a stabilization mechanism, SALSA can automatically adapt the step size during the optimization process, leading to more stable and efficient convergence compared to existing methods.
The potential impact of SALSA is wide-reaching, as optimization is a fundamental component of many machine learning and scientific computing tasks. By reducing the burden of hyperparameter tuning and improving the overall reliability of optimization, SALSA could enable more efficient and robust model development across a variety of domains, from natural language processing to reinforcement learning to computational biology.
While the paper identifies some areas for further research, the SALSA algorithm represents a significant step forward in the field of optimization and is likely to inspire ongoing advancements and applications in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
No learning rates needed: Introducing SALSA -- Stable Armijo Line Search Adaptation
Philip Kenneweg, Tristan Kenneweg, Fabian Fumagalli, Barbara Hammer
In recent studies, line search methods have been demonstrated to significantly enhance the performance of conventional stochastic gradient descent techniques across various datasets and architectures, while making an otherwise critical choice of learning rate schedule superfluous. In this paper, we identify problems of current state-of-the-art of line search methods, propose enhancements, and rigorously assess their effectiveness. Furthermore, we evaluate these methods on orders of magnitude larger datasets and more complex data domains than previously done. More specifically, we enhance the Armijo line search method by speeding up its computation and incorporating a momentum term into the Armijo criterion, making it better suited for stochastic mini-batching. Our optimization approach outperforms both the previous Armijo implementation and a tuned learning rate schedule for the Adam and SGD optimizers. Our evaluation covers a diverse range of architectures, such as Transformers, CNNs, and MLPs, as well as data domains, including NLP and image data. Our work is publicly available as a Python package, which provides a simple Pytorch optimizer.
Read more7/31/2024

0
Adaptive Backtracking For Faster Optimization
Joao V. Cavalcanti, Laurent Lessard, Ashia C. Wilson
Backtracking line search is foundational in numerical optimization. The basic idea is to adjust the step size of an algorithm by a constant factor until some chosen criterion (e.g. Armijo, Goldstein, Descent Lemma) is satisfied. We propose a new way for adjusting step sizes, replacing the constant factor used in regular backtracking with one that takes into account the degree to which the chosen criterion is violated, without additional computational burden. For convex problems, we prove adaptive backtracking requires fewer adjustments to produce a feasible step size than regular backtracking does for two popular line search criteria: the Armijo condition and the descent lemma. For nonconvex smooth problems, we additionally prove adaptive backtracking enjoys the same guarantees of regular backtracking. Finally, we perform a variety of experiments on over fifteen real world datasets, all of which confirm that adaptive backtracking often leads to significantly faster optimization.
Read more8/26/2024
🛠️
0
SALSA: Simulated Annealing based Loop-Ordering Scheduler for DNN Accelerators
Victor J. B. Jung, Arne Symons, Linyan Mei, Marian Verhelst, Luca Benini
To meet the growing need for computational power for DNNs, multiple specialized hardware architectures have been proposed. Each DNN layer should be mapped onto the hardware with the most efficient schedule, however, SotA schedulers struggle to consistently provide optimum schedules in a reasonable time across all DNN-HW combinations. This paper proposes SALSA, a fast dual-engine scheduler to generate optimal execution schedules for both even and uneven mapping. We introduce a new strategy, combining exhaustive search with simulated annealing to address the dynamic nature of the loop ordering design space size across layers. SALSA is extensively benchmarked against two SotA schedulers, LOMA and Timeloop on 5 different DNNs, on average SALSA finds schedules with 11.9% and 7.6% lower energy while speeding up the search by 1.7x and 24x compared to LOMA and Timeloop, respectively.
Read more6/17/2024

0
Why Line Search when you can Plane Search? SO-Friendly Neural Networks allow Per-Iteration Optimization of Learning and Momentum Rates for Every Layer
Betty Shea, Mark Schmidt
We introduce the class of SO-friendly neural networks, which include several models used in practice including networks with 2 layers of hidden weights where the number of inputs is larger than the number of outputs. SO-friendly networks have the property that performing a precise line search to set the step size on each iteration has the same asymptotic cost during full-batch training as using a fixed learning. Further, for the same cost a planesearch can be used to set both the learning and momentum rate on each step. Even further, SO-friendly networks also allow us to use subspace optimization to set a learning rate and momentum rate for each layer on each iteration. We explore augmenting gradient descent as well as quasi-Newton methods and Adam with line optimization and subspace optimization, and our experiments indicate that this gives fast and reliable ways to train these networks that are insensitive to hyper-parameters.
Read more6/27/2024