No Re-Train, More Gain: Upgrading Backbones with Diffusion Model for Few-Shot Segmentation

0

Sign in to get full access
Overview
- This paper presents a novel approach for upgrading neural network backbones to improve few-shot segmentation performance without requiring re-training.
- The key idea is to leverage a pre-trained diffusion model to generate high-fidelity segmentation masks from a few input examples, which are then used to fine-tune the backbone network.
- The proposed method, called DiffBackbone, is evaluated on several few-shot segmentation benchmarks and shown to outperform existing approaches.
Plain English Explanation
In the field of machine learning, few-shot segmentation refers to the task of accurately segmenting objects in an image when only a small number of example segmentations are available for training. This is a challenging problem because neural networks typically require large amounts of labeled data to perform well.
The researchers behind this paper have developed a novel approach to address this challenge. Their key insight is to leverage a diffusion model, which is a type of generative model that can be used to generate high-quality segmentation masks from a few input examples.
The researchers first train the diffusion model on a large dataset of segmented images. Then, when faced with a new few-shot segmentation task, they use the diffusion model to generate additional, high-quality segmentation masks from the limited training examples. These generated masks are then used to fine-tune the backbone network (the core of the neural network) without requiring the network to be completely retrained.
This approach, called DiffBackbone, allows the backbone network to be "upgraded" for the new task, leading to improved segmentation performance without the need for extensive re-training. The researchers demonstrate the effectiveness of their approach on several few-shot segmentation benchmarks, where DiffBackbone outperforms existing methods.
Technical Explanation
The key components of the DiffBackbone approach are:
-
Diffusion Model: The researchers train a diffusion model on a large dataset of segmented images. This model can then be used to generate high-quality segmentation masks from a few input examples.
-
Backbone Upgrade: Given a few-shot segmentation task, the researchers use the pre-trained diffusion model to generate additional segmentation masks from the limited training examples. These generated masks are then used to fine-tune the backbone network, effectively "upgrading" it for the new task without requiring complete re-training.
-
Evaluation: The researchers evaluate the DiffBackbone approach on several few-shot segmentation benchmarks and compare it to existing methods. They show that DiffBackbone outperforms the state-of-the-art in both few-shot and zero-shot segmentation scenarios.
The key technical insights behind DiffBackbone are:
-
Leveraging Diffusion Models: Diffusion models are powerful generative models that can produce high-fidelity segmentation masks from limited input examples. By incorporating this capability, the researchers can effectively "augment" the training data for the backbone network without the need for extensive re-training.
-
Efficient Backbone Upgrade: Rather than re-training the entire backbone network, the researchers fine-tune only the relevant layers, which is computationally more efficient and allows for better performance on the few-shot task.
-
Multi-Granularity Adaptation: The researchers explore different strategies for adapting the backbone network, including feature-level and uncertainty-based adaptation, to further improve the few-shot segmentation performance.
Critical Analysis
The DiffBackbone approach presented in this paper is a promising solution for improving few-shot segmentation performance without the need for extensive re-training. The researchers have demonstrated the effectiveness of their method on several benchmarks, showcasing its ability to outperform existing approaches.
However, the paper does not address certain limitations and potential issues that could be explored in future research:
-
Generalization Capacity: While DiffBackbone performs well on the evaluated benchmarks, it would be interesting to see how the method generalizes to a wider range of few-shot segmentation tasks, especially those with more diverse datasets and object types.
-
Diffusion Model Limitations: The performance of DiffBackbone is heavily dependent on the quality and robustness of the pre-trained diffusion model. Further research could explore ways to improve the diffusion model's capabilities, particularly in handling noisy or challenging input data.
-
Computational Efficiency: The paper does not provide a detailed analysis of the computational costs associated with the DiffBackbone approach, especially the training of the diffusion model. Investigating ways to optimize the computational efficiency of the method could be a valuable area of future work.
-
Real-World Applicability: While the paper demonstrates the effectiveness of DiffBackbone on established few-shot segmentation benchmarks, it would be beneficial to evaluate the method's performance on real-world applications, such as medical image segmentation or autonomous driving, to assess its practical relevance.
Overall, the DiffBackbone approach presented in this paper is a significant contribution to the field of few-shot segmentation, and the researchers have demonstrated the potential of leveraging diffusion models to improve the performance of neural network backbones. Addressing the identified limitations and exploring further avenues of research could help to solidify the method's applicability and impact in the wider machine learning community.
Conclusion
In this paper, the researchers have introduced a novel approach called DiffBackbone, which aims to improve the performance of few-shot segmentation tasks by leveraging a pre-trained diffusion model to generate high-quality segmentation masks from limited training examples. The key idea is to use these generated masks to fine-tune the backbone network, effectively "upgrading" it for the new task without the need for extensive re-training.
The researchers have shown that DiffBackbone outperforms existing few-shot segmentation methods on several benchmarks, demonstrating the effectiveness of their approach. By incorporating the powerful generative capabilities of diffusion models, DiffBackbone represents a significant advancement in the field of few-shot segmentation, with the potential to have a broader impact on various applications that rely on accurate image segmentation.
While the paper highlights the strengths of the DiffBackbone method, it also identifies areas for further research, such as exploring the generalization capacity, improving the diffusion model's capabilities, and assessing the method's computational efficiency and real-world applicability. Addressing these aspects could further enhance the DiffBackbone approach and contribute to the ongoing efforts to develop robust and efficient few-shot segmentation solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
No Re-Train, More Gain: Upgrading Backbones with Diffusion Model for Few-Shot Segmentation
Shuai Chen, Fanman Meng, Chenhao Wu, Haoran Wei, Runtong Zhang, Qingbo Wu, Linfeng Xu, Hongliang Li
Few-Shot Segmentation (FSS) aims to segment novel classes using only a few annotated images. Despite considerable process under pixel-wise support annotation, current FSS methods still face three issues: the inflexibility of backbone upgrade without re-training, the inability to uniformly handle various types of annotations (e.g., scribble, bounding box, mask and text), and the difficulty in accommodating different annotation quantity. To address these issues simultaneously, we propose DiffUp, a novel FSS method that conceptualizes the FSS task as a conditional generative problem using a diffusion process. For the first issue, we introduce a backbone-agnostic feature transformation module that converts different segmentation cues into unified coarse priors, facilitating seamless backbone upgrade without re-training. For the second issue, due to the varying granularity of transformed priors from diverse annotation types, we conceptualize these multi-granular transformed priors as analogous to noisy intermediates at different steps of a diffusion model. This is implemented via a self-conditioned modulation block coupled with a dual-level quality modulation branch. For the third issue, we incorporates an uncertainty-aware information fusion module that harmonizing the variability across zero-shot, one-shot and many-shot scenarios. Evaluated through rigorous benchmarks, DiffUp significantly outperforms existing FSS models in terms of flexibility and accuracy.
Read more7/24/2024

0
Few-Shot Medical Image Segmentation with High-Fidelity Prototypes
Song Tang, Shaxu Yan, Xiaozhi Qi, Jianxin Gao, Mao Ye, Jianwei Zhang, Xiatian Zhu
Few-shot Semantic Segmentation (FSS) aims to adapt a pretrained model to new classes with as few as a single labelled training sample per class. Despite the prototype based approaches have achieved substantial success, existing models are limited to the imaging scenarios with considerably distinct objects and not highly complex background, e.g., natural images. This makes such models suboptimal for medical imaging with both conditions invalid. To address this problem, we propose a novel Detail Self-refined Prototype Network (DSPNet) to constructing high-fidelity prototypes representing the object foreground and the background more comprehensively. Specifically, to construct global semantics while maintaining the captured detail semantics, we learn the foreground prototypes by modelling the multi-modal structures with clustering and then fusing each in a channel-wise manner. Considering that the background often has no apparent semantic relation in the spatial dimensions, we integrate channel-specific structural information under sparse channel-aware regulation. Extensive experiments on three challenging medical image benchmarks show the superiority of DSPNet over previous state-of-the-art methods.
Read more6/27/2024

0
Adapt Before Comparison: A New Perspective on Cross-Domain Few-Shot Segmentation
Jonas Herzog
Few-shot segmentation performance declines substantially when facing images from a domain different than the training domain, effectively limiting real-world use cases. To alleviate this, recently cross-domain few-shot segmentation (CD-FSS) has emerged. Works that address this task mainly attempted to learn segmentation on a source domain in a manner that generalizes across domains. Surprisingly, we can outperform these approaches while eliminating the training stage and removing their main segmentation network. We show test-time task-adaption is the key for successful CD-FSS instead. Task-adaption is achieved by appending small networks to the feature pyramid of a conventionally classification-pretrained backbone. To avoid overfitting to the few labeled samples in supervised fine-tuning, consistency across augmented views of input images serves as guidance while learning the parameters of the attached layers. Despite our self-restriction not to use any images other than the few labeled samples at test time, we achieve new state-of-the-art performance in CD-FSS, evidencing the need to rethink approaches for the task.
Read more5/20/2024
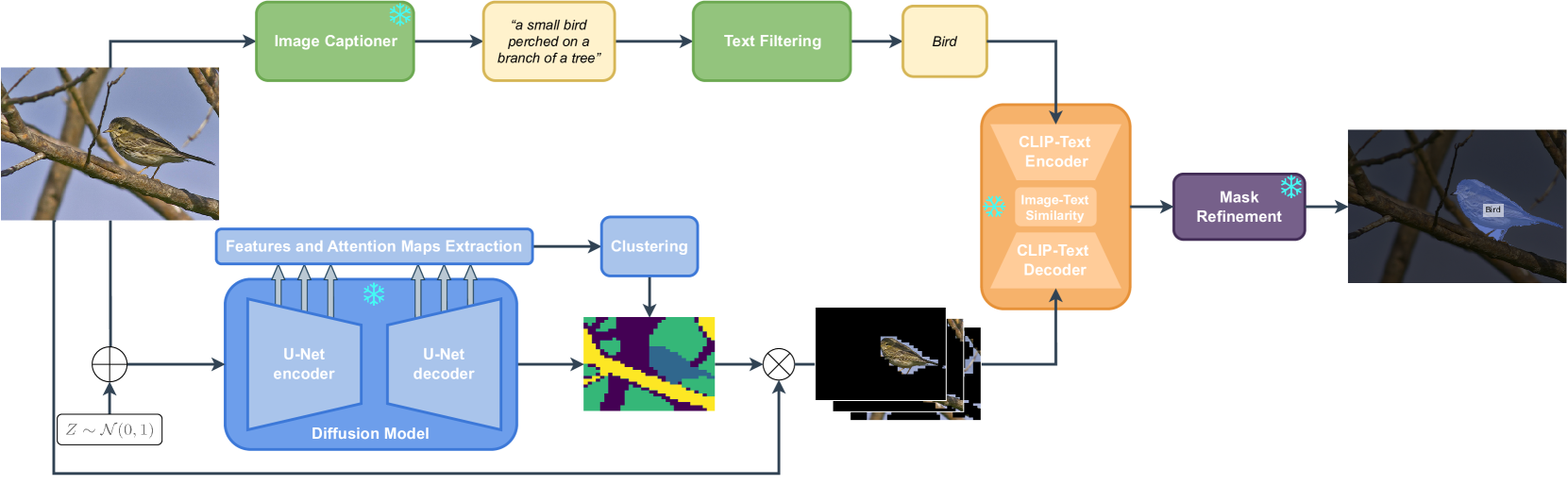
0
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
Read more4/1/2024