Non-linear Welfare-Aware Strategic Learning
2405.01810
0
0

Abstract
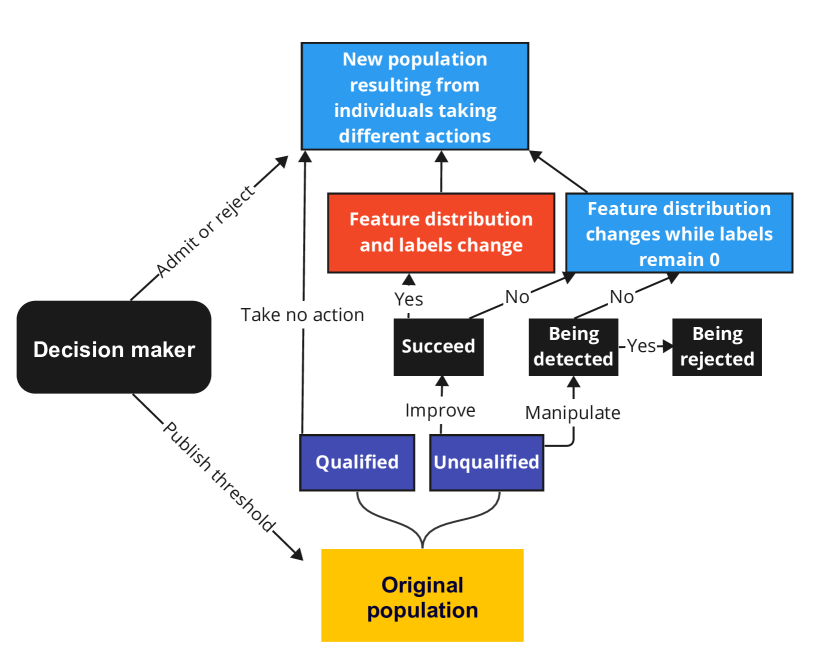
This paper studies algorithmic decision-making in the presence of strategic individual behaviors, where an ML model is used to make decisions about human agents and the latter can adapt their behavior strategically to improve their future data. Existing results on strategic learning have largely focused on the linear setting where agents with linear labeling functions best respond to a (noisy) linear decision policy. Instead, this work focuses on general non-linear settings where agents respond to the decision policy with only local information of the policy. Moreover, we simultaneously consider the objectives of maximizing decision-maker welfare (model prediction accuracy), social welfare (agent improvement caused by strategic behaviors), and agent welfare (the extent that ML underestimates the agents). We first generalize the agent best response model in previous works to the non-linear setting, then reveal the compatibility of welfare objectives. We show the three welfare can attain the optimum simultaneously only under restrictive conditions which are challenging to achieve in non-linear settings. The theoretical results imply that existing works solely maximizing the welfare of a subset of parties inevitably diminish the welfare of the others. We thus claim the necessity of balancing the welfare of each party in non-linear settings and propose an irreducible optimization algorithm suitable for general strategic learning. Experiments on synthetic and real data validate the proposed algorithm.
Create account to get full access
Overview
- This paper explores a novel approach to strategic learning that takes into account the non-linear and welfare-aware aspects of the problem.
- The proposed method aims to address the challenges of imitative strategic behavior, where agents persistently improve their strategies in response to the decisions of others.
- The research also explores the social choice implications of algorithmic decision-making, with a focus on dealing with diverse human preferences and privacy-aware agents.
Plain English Explanation
In this research, the authors tackle the complex issue of strategic learning, where agents (e.g., AI systems, people) adapt their strategies based on the actions of others. This can lead to unpredictable and undesirable outcomes, as agents may continuously try to outmaneuver each other.
The key idea is to develop a learning approach that takes into account the non-linear and welfare-aware nature of the problem. In other words, the method should be able to handle the fact that the impact of an agent's actions on the overall welfare (wellbeing) of the system may not be linear or straightforward.
The researchers also explore the social implications of algorithmic decision-making, particularly when dealing with diverse human preferences and privacy-conscious agents. For example, how can an AI system make decisions that balance the needs and values of different stakeholders, while also respecting individual privacy?
By addressing these challenges, the authors aim to create more robust and socially responsible strategic learning systems, which could have important applications in fields like multi-objective recommendation, group decision-making, and AI alignment.
Technical Explanation
The paper proposes a novel framework for strategic learning that takes into account the non-linear and welfare-aware aspects of the problem. The key components of the approach include:
-
Non-linear Welfare Modeling: The authors introduce a non-linear function to model the welfare (or utility) of the overall system, capturing the complex and often unpredictable relationships between agents' actions and the resulting outcomes.
-
Strategic Learning Algorithm: The researchers develop a learning algorithm that optimizes the agents' strategies while considering the non-linear welfare function. This helps the agents make decisions that balance their individual interests with the broader societal impact.
-
Social Choice Implications: The paper also explores the social choice implications of the proposed approach, investigating how it can be used to make decisions that account for diverse human preferences and respect individual privacy, as seen in related work and algorithmic decision-making under persistent improvement.
The authors conduct experiments to evaluate the performance of their method, comparing it to various baseline approaches. The results demonstrate the effectiveness of the non-linear, welfare-aware strategic learning framework in producing more socially responsible and desirable outcomes, even in the face of imitative strategic behavior.
Critical Analysis
One potential limitation of the research is the complexity of the non-linear welfare function, which may make it challenging to optimize in real-world scenarios. The authors acknowledge this and suggest further work to develop more efficient optimization techniques.
Additionally, the paper does not delve deeply into the specific mechanisms for dealing with diverse human preferences and privacy-aware agents. More detailed exploration of these social choice aspects could strengthen the practical relevance of the proposed approach.
Lastly, while the experiments demonstrate the benefits of the non-linear, welfare-aware strategic learning framework, the authors could consider expanding the range of scenarios and benchmarks to further validate the generalizability of their findings.
Conclusion
This research presents a novel approach to strategic learning that takes into account the non-linear and welfare-aware nature of the problem. By developing a learning algorithm that optimizes agents' strategies while considering the broader societal impact, the authors aim to create more responsible and socially aligned decision-making systems.
The work has important implications for fields like multi-objective recommendation, group decision-making, and AI alignment, where balancing individual interests and societal welfare is crucial. As AI systems become increasingly integrated into our decision-making processes, research like this can help ensure they are designed with the well-being of all stakeholders in mind.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Learning under Imitative Strategic Behavior with Unforeseeable Outcomes
Tian Xie, Zhiqun Zuo, Mohammad Mahdi Khalili, Xueru Zhang
0
0
Machine learning systems have been widely used to make decisions about individuals who may best respond and behave strategically to receive favorable outcomes, e.g., they may genuinely improve the true labels or manipulate observable features directly to game the system without changing labels. Although both behaviors have been studied (often as two separate problems) in the literature, most works assume individuals can (i) perfectly foresee the outcomes of their behaviors when they best respond; (ii) change their features arbitrarily as long as it is affordable, and the costs they need to pay are deterministic functions of feature changes. In this paper, we consider a different setting and focus on imitative strategic behaviors with unforeseeable outcomes, i.e., individuals manipulate/improve by imitating the features of those with positive labels, but the induced feature changes are unforeseeable. We first propose a Stackelberg game to model the interplay between individuals and the decision-maker, under which we examine how the decision-maker's ability to anticipate individual behavior affects its objective function and the individual's best response. We show that the objective difference between the two can be decomposed into three interpretable terms, with each representing the decision-maker's preference for a certain behavior. By exploring the roles of each term, we further illustrate how a decision-maker with adjusted preferences can simultaneously disincentivize manipulation, incentivize improvement, and promote fairness.
5/6/2024
Learning Social Welfare Functions
Kanad Shrikar Pardeshi, Itai Shapira, Ariel D. Procaccia, Aarti Singh
0
0
Is it possible to understand or imitate a policy maker's rationale by looking at past decisions they made? We formalize this question as the problem of learning social welfare functions belonging to the well-studied family of power mean functions. We focus on two learning tasks; in the first, the input is vectors of utilities of an action (decision or policy) for individuals in a group and their associated social welfare as judged by a policy maker, whereas in the second, the input is pairwise comparisons between the welfares associated with a given pair of utility vectors. We show that power mean functions are learnable with polynomial sample complexity in both cases, even if the comparisons are social welfare information is noisy. Finally, we design practical algorithms for these tasks and evaluate their performance.
5/29/2024
🌀
Algorithmic Decision-Making under Agents with Persistent Improvement
Tian Xie, Xuwei Tan, Xueru Zhang
0
0
This paper studies algorithmic decision-making under human's strategic behavior, where a decision maker uses an algorithm to make decisions about human agents, and the latter with information about the algorithm may exert effort strategically and improve to receive favorable decisions. Unlike prior works that assume agents benefit from their efforts immediately, we consider realistic scenarios where the impacts of these efforts are persistent and agents benefit from efforts by making improvements gradually. We first develop a dynamic model to characterize persistent improvements and based on this construct a Stackelberg game to model the interplay between agents and the decision-maker. We analytically characterize the equilibrium strategies and identify conditions under which agents have incentives to improve. With the dynamics, we then study how the decision-maker can design an optimal policy to incentivize the largest improvements inside the agent population. We also extend the model to settings where 1) agents may be dishonest and game the algorithm into making favorable but erroneous decisions; 2) honest efforts are forgettable and not sufficient to guarantee persistent improvements. With the extended models, we further examine conditions under which agents prefer honest efforts over dishonest behavior and the impacts of forgettable efforts.
5/6/2024
🤔
Understanding Model Selection For Learning In Strategic Environments
Tinashe Handina, Eric Mazumdar
0
0
The deployment of ever-larger machine learning models reflects a growing consensus that the more expressive the model class one optimizes over$unicode{x2013}$and the more data one has access to$unicode{x2013}$the more one can improve performance. As models get deployed in a variety of real-world scenarios, they inevitably face strategic environments. In this work, we consider the natural question of how the interplay of models and strategic interactions affects the relationship between performance at equilibrium and the expressivity of model classes. We find that strategic interactions can break the conventional view$unicode{x2013}$meaning that performance does not necessarily monotonically improve as model classes get larger or more expressive (even with infinite data). We show the implications of this result in several contexts including strategic regression, strategic classification, and multi-agent reinforcement learning. In particular, we show that each of these settings admits a Braess' paradox-like phenomenon in which optimizing over less expressive model classes allows one to achieve strictly better equilibrium outcomes. Motivated by these examples, we then propose a new paradigm for model selection in games wherein an agent seeks to choose amongst different model classes to use as their action set in a game.
6/4/2024