Social Choice for AI Alignment: Dealing with Diverse Human Feedback
2404.10271
0
0
Abstract
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper explores the challenge of value alignment between AI systems and diverse human feedback in the context of social choice theory.
- It examines how to design AI systems that can effectively navigate and aggregate varied human preferences and values.
- The paper proposes novel approaches to address the complexities of value alignment, drawing insights from fields like social choice, mechanism design, and multi-agent systems.
Plain English Explanation
As AI systems become more advanced and integrated into our lives, it's crucial that they are aligned with human values and interests. This is a challenging task, as humans can have diverse and sometimes conflicting views on what is "good" or "right".
The researchers in this paper tackle this problem from the perspective of social choice theory - the study of how to aggregate individual preferences into a collective decision. They explore ways to design AI systems that can effectively learn and adapt to different human values and feedback, rather than simply optimizing for a single pre-defined objective.
This is important because as AI becomes more capable, it will play a larger role in making decisions that impact our lives. We want to ensure that these decisions are aligned with the diverse values and preferences of the human population, not just the preferences of a small group of developers or policymakers.
The researchers propose novel approaches that draw insights from fields like mechanism design and multi-agent systems. The goal is to develop AI systems that can effectively navigate the complexities of value alignment and make decisions that are truly representative of human interests.
Technical Explanation
The paper begins by outlining the challenge of value alignment between AI systems and diverse human feedback. It discusses how traditional approaches to AI alignment, which often focus on optimizing for a single pre-defined objective, may fail to capture the nuances and complexities of human values.
The researchers then draw on insights from social choice theory to propose novel approaches for designing AI systems that can effectively aggregate and respond to varied human preferences. This includes techniques from mechanism design to incentivize human users to provide honest and informative feedback, as well as multi-agent systems approaches to model the interactions between AI systems and humans.
Through a series of theoretical analyses and simulations, the researchers demonstrate how these approaches can outperform traditional AI alignment methods in scenarios with diverse human feedback. They also discuss the potential challenges and limitations of their proposed solutions, such as the need to balance individual privacy concerns with the collective goal of value alignment.
Critical Analysis
The researchers raise important points about the limitations of existing AI alignment approaches and the need to develop more sophisticated techniques to handle diverse human values. Their use of social choice theory and mechanism design provides a novel and promising framework for addressing these challenges.
However, the paper also acknowledges that there are significant hurdles to implementing these approaches in practice. Incentivizing honest and informative human feedback, for example, may be difficult to achieve in real-world settings where users may have their own agendas or biases.
Additionally, the researchers primarily focus on theoretical analyses and simulations, leaving open questions about the feasibility and scalability of their proposals in large-scale, real-world AI systems. Further empirical research and field testing would be necessary to fully evaluate the effectiveness of their approaches.
It's also worth considering the broader ethical implications of these techniques. While the researchers aim to align AI with diverse human values, there is a risk that the aggregation of preferences could overlook the needs of marginalized or underrepresented groups. Careful attention to issues of fairness and inclusivity will be crucial as this research area evolves.
Conclusion
This paper presents a compelling approach to the challenge of value alignment between AI systems and diverse human feedback. By drawing on insights from social choice theory and mechanism design, the researchers propose novel techniques for developing AI that can effectively navigate the complexities of human values and preferences.
The potential implications of this research are significant, as it could help to ensure that AI-assisted decision-making is truly representative of the interests and values of the broader population, rather than being skewed towards the preferences of a small group.
While there are still significant challenges to overcome, this work represents an important step forward in the quest to build AI systems that are aligned with the diverse and often conflicting values of human society.
Related Papers
🔎
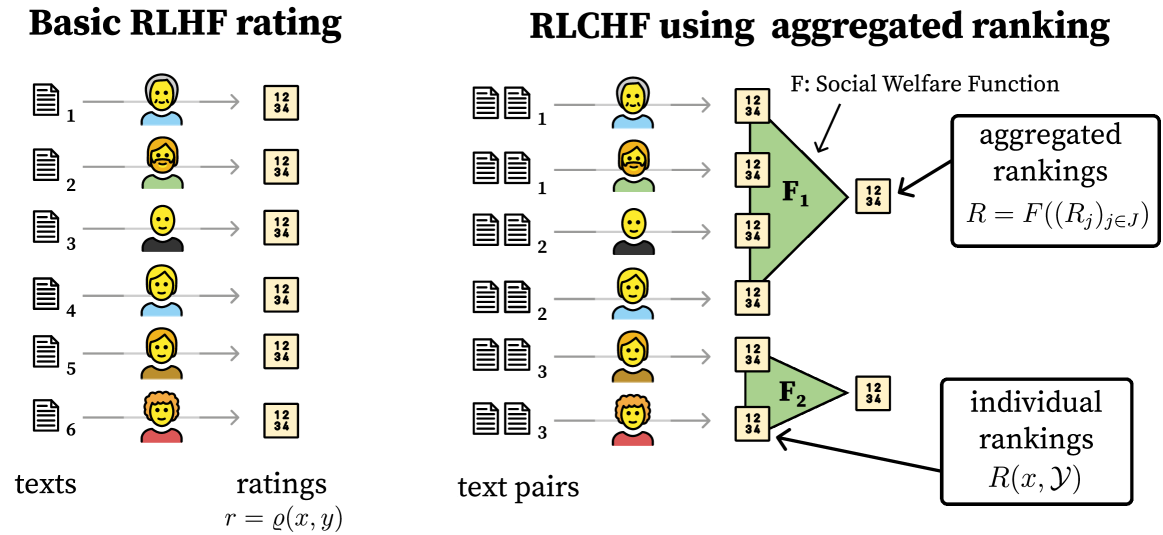
Mapping Social Choice Theory to RLHF
Jessica Dai, Eve Fleisig
0
0
Recent work on the limitations of using reinforcement learning from human feedback (RLHF) to incorporate human preferences into model behavior often raises social choice theory as a reference point. Social choice theory's analysis of settings such as voting mechanisms provides technical infrastructure that can inform how to aggregate human preferences amid disagreement. We analyze the problem settings of social choice and RLHF, identify key differences between them, and discuss how these differences may affect the RLHF interpretation of well-known technical results in social choice.
4/22/2024
🏅
Bias Mitigation via Compensation: A Reinforcement Learning Perspective
Nandhini Swaminathan, David Danks
0
0
As AI increasingly integrates with human decision-making, we must carefully consider interactions between the two. In particular, current approaches focus on optimizing individual agent actions but often overlook the nuances of collective intelligence. Group dynamics might require that one agent (e.g., the AI system) compensate for biases and errors in another agent (e.g., the human), but this compensation should be carefully developed. We provide a theoretical framework for algorithmic compensation that synthesizes game theory and reinforcement learning principles to demonstrate the natural emergence of deceptive outcomes from the continuous learning dynamics of agents. We provide simulation results involving Markov Decision Processes (MDP) learning to interact. This work then underpins our ethical analysis of the conditions in which AI agents should adapt to biases and behaviors of other agents in dynamic and complex decision-making environments. Overall, our approach addresses the nuanced role of strategic deception of humans, challenging previous assumptions about its detrimental effects. We assert that compensation for others' biases can enhance coordination and ethical alignment: strategic deception, when ethically managed, can positively shape human-AI interactions.
5/1/2024
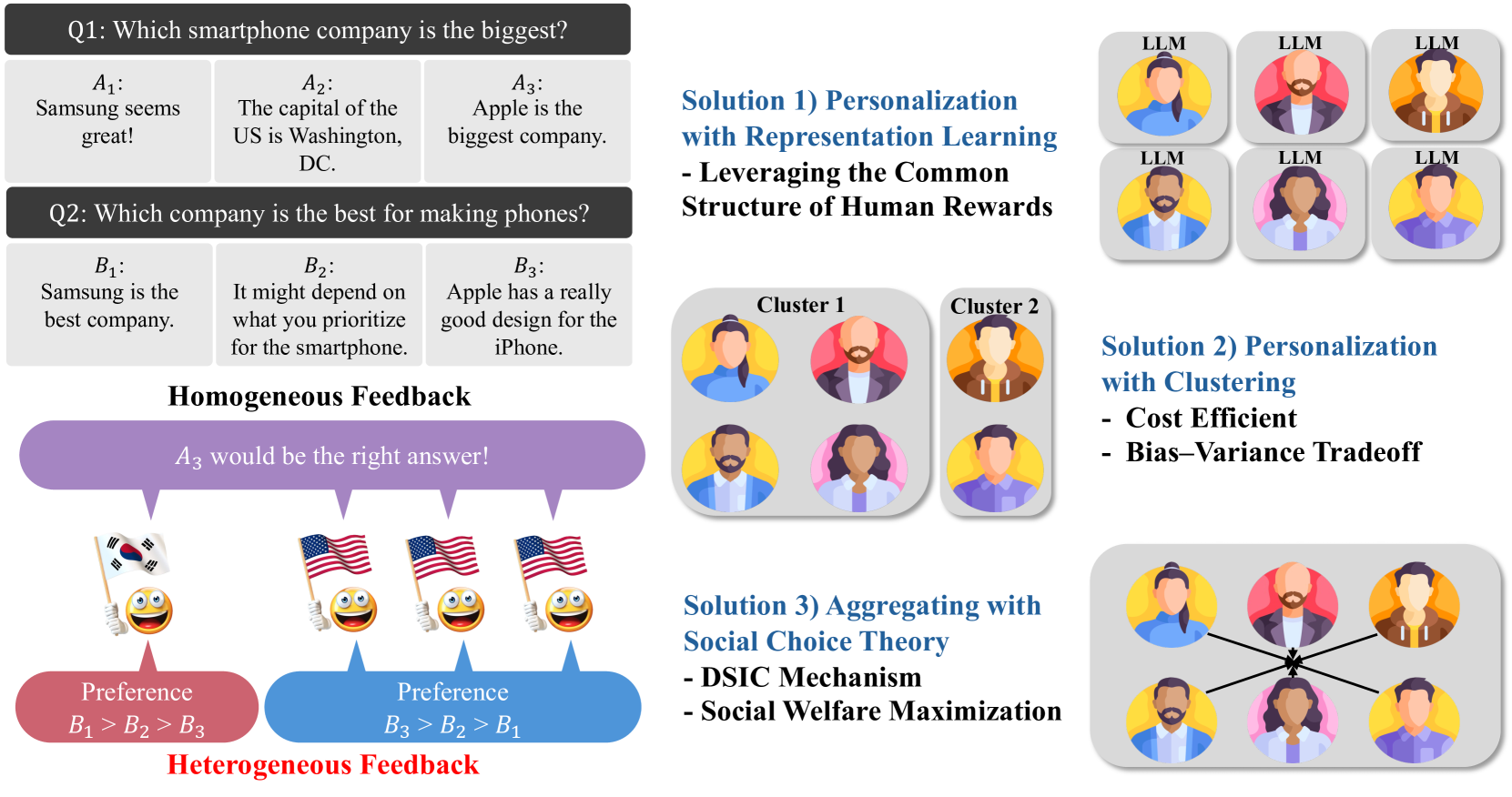
Principled RLHF from Heterogeneous Feedback via Personalization and Preference Aggregation
Chanwoo Park, Mingyang Liu, Kaiqing Zhang, Asuman Ozdaglar
0
0
Reinforcement learning from human feedback (RLHF) has been an effective technique for aligning AI systems with human values, with remarkable successes in fine-tuning large-language models recently. Most existing RLHF paradigms make the underlying assumption that human preferences are relatively homogeneous, and can be encoded by a single reward model. In this paper, we focus on addressing the issues due to the inherent heterogeneity in human preferences, as well as their potential strategic behavior in providing feedback. Specifically, we propose two frameworks to address heterogeneous human feedback in principled ways: personalization-based one and aggregation-based one. For the former, we propose two approaches based on representation learning and clustering, respectively, for learning multiple reward models that trades off the bias (due to preference heterogeneity) and variance (due to the use of fewer data for learning each model by personalization). We then establish sample complexity guarantees for both approaches. For the latter, we aim to adhere to the single-model framework, as already deployed in the current RLHF paradigm, by carefully aggregating diverse and truthful preferences from humans. We propose two approaches based on reward and preference aggregation, respectively: the former utilizes both utilitarianism and Leximin approaches to aggregate individual reward models, with sample complexity guarantees; the latter directly aggregates the human feedback in the form of probabilistic opinions. Under the probabilistic-opinion-feedback model, we also develop an approach to handle strategic human labelers who may bias and manipulate the aggregated preferences with untruthful feedback. Based on the ideas in mechanism design, our approach ensures truthful preference reporting, with the induced aggregation rule maximizing social welfare functions.
5/2/2024
📊
Warmth and competence in human-agent cooperation
Kevin R. McKee, Xuechunzi Bai, Susan T. Fiske
0
0
Interaction and cooperation with humans are overarching aspirations of artificial intelligence (AI) research. Recent studies demonstrate that AI agents trained with deep reinforcement learning are capable of collaborating with humans. These studies primarily evaluate human compatibility through objective metrics such as task performance, obscuring potential variation in the levels of trust and subjective preference that different agents garner. To better understand the factors shaping subjective preferences in human-agent cooperation, we train deep reinforcement learning agents in Coins, a two-player social dilemma. We recruit $N = 501$ participants for a human-agent cooperation study and measure their impressions of the agents they encounter. Participants' perceptions of warmth and competence predict their stated preferences for different agents, above and beyond objective performance metrics. Drawing inspiration from social science and biology research, we subsequently implement a new ``partner choice'' framework to elicit revealed preferences: after playing an episode with an agent, participants are asked whether they would like to play the next episode with the same agent or to play alone. As with stated preferences, social perception better predicts participants' revealed preferences than does objective performance. Given these results, we recommend human-agent interaction researchers routinely incorporate the measurement of social perception and subjective preferences into their studies.
4/30/2024