Non-Prehensile Aerial Manipulation using Model-Based Deep Reinforcement Learning

0
Sign in to get full access
Overview
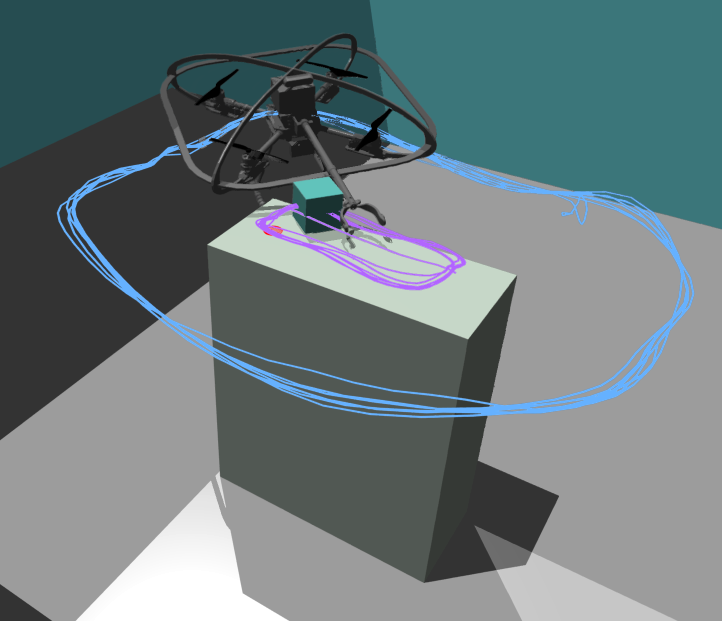
- This paper explores the use of model-based deep reinforcement learning to enable non-prehensile aerial manipulation, where a drone interacts with objects without grasping them.
- The researchers develop a simulation environment and train a deep reinforcement learning agent to control a quadcopter drone and perform tasks like pushing, sliding, and rolling objects.
- The model-based approach allows the agent to learn efficient manipulation strategies by leveraging a learned dynamics model, in contrast to traditional model-free reinforcement learning.
Plain English Explanation
Drones are becoming increasingly capable, but most can only interact with objects by grasping them. This paper describes a new approach that allows drones to manipulate objects without having to pick them up.
The researchers trained a drone using a novel deep reinforcement learning technique. Rather than just trying random actions and seeing what works, the drone learns an internal model of how its movements affect the objects around it. This allows the drone to plan efficient manipulation strategies, like pushing, sliding, or rolling objects, without having to physically grasp them.
The key innovation is the use of a "model-based" approach, where the drone learns a model of the world and uses that to plan its actions, rather than just trying random things. This is more efficient than traditional "model-free" reinforcement learning, where the drone has to learn everything from scratch.
The researchers tested this in a simulated environment, showing that the drone could learn complex non-prehensile manipulation skills. [This could be very useful for real-world applications like autonomous landing or interacting with objects in difficult environments.]
Technical Explanation
The paper presents a model-based deep reinforcement learning approach for enabling non-prehensile aerial manipulation tasks with a quadcopter drone. The researchers develop a simulation environment that models the dynamics of the drone and the objects it interacts with. They then train a deep neural network policy using model-based deep reinforcement learning, where the agent learns a dynamics model of the environment in addition to the manipulation policy.
The key technical elements include:
- Simulation Environment: The researchers create a realistic simulation environment using the MuJoCo physics engine, which models the drone's dynamics as well as the dynamics of various objects the drone can interact with.
- Model-based RL: Instead of traditional model-free reinforcement learning, the agent learns a dynamics model of the environment in parallel with the manipulation policy. This allows the agent to plan efficient manipulation strategies by reasoning about the predicted outcomes of its actions.
- Network Architecture: The agent's policy and dynamics model are represented by a deep neural network with separate components for perception, reasoning, and control. This architecture allows the agent to learn effective manipulation skills from raw sensory inputs.
- Training Procedure: The agent is trained using a combination of on-policy and off-policy data, allowing it to learn efficiently while maintaining stable performance.
The results demonstrate that the model-based deep reinforcement learning approach enables the quadcopter drone to learn complex non-prehensile manipulation skills, such as pushing, sliding, and rolling objects, significantly outperforming traditional model-free methods.
Critical Analysis
The paper presents a promising approach for enabling drones to perform non-prehensile manipulation tasks, which could be valuable for a variety of real-world applications. However, there are some potential limitations and areas for further research:
- Simulation-to-Reality Gap: While the simulation environment is designed to be realistic, there may still be a gap between the simulated dynamics and the actual behavior of a physical drone. Further work is needed to address this "sim-to-real" transfer problem and ensure the technique can be applied effectively in the real world.
- Object Complexity: The experiments in this paper focus on simple, geometric objects. Extending the approach to manipulate more complex, irregularly shaped objects may require additional architectural or algorithmic innovations.
- Scalability: The paper demonstrates the approach on a single drone manipulating a single object. Scaling this to scenarios with multiple drones and objects, as would be required for many practical applications, may present significant technical challenges.
- Safety and Robustness: When deploying drones in the real world, it is crucial to ensure the manipulation skills are safe and robust, even in the face of unexpected events or disturbances. Further research is needed to address these important practical concerns.
Overall, this paper represents an important step forward in enabling more versatile and capable aerial manipulation skills. However, significant additional research and development will be needed to bring this technology to real-world applications.
Conclusion
This paper presents a novel model-based deep reinforcement learning approach for enabling non-prehensile aerial manipulation with quadcopter drones. By learning a dynamics model of the environment in addition to the manipulation policy, the agents are able to plan efficient strategies for tasks like pushing, sliding, and rolling objects without having to physically grasp them.
The results demonstrate the effectiveness of this approach in a simulated environment, significantly outperforming traditional model-free reinforcement learning methods. While there are still some limitations and challenges to address, this work represents an important advance in the field of aerial robotics, paving the way for drones that can interact with their environment in more sophisticated and versatile ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Non-Prehensile Aerial Manipulation using Model-Based Deep Reinforcement Learning
Cora A. Dimmig, Marin Kobilarov
With the continual adoption of Uncrewed Aerial Vehicles (UAVs) across a wide-variety of application spaces, robust aerial manipulation remains a key research challenge. Aerial manipulation tasks require interacting with objects in the environment, often without knowing their dynamical properties like mass and friction a priori. Additionally, interacting with these objects can have a significant impact on the control and stability of the vehicle. We investigated an approach for robust control and non-prehensile aerial manipulation in unknown environments. In particular, we use model-based Deep Reinforcement Learning (DRL) to learn a world model of the environment while simultaneously learning a policy for interaction with the environment. We evaluated our approach on a series of push tasks by moving an object between goal locations and demonstrated repeatable behaviors across a range of friction values.
Read more7/2/2024

0
Intercepting Unauthorized Aerial Robots in Controlled Airspace Using Reinforcement Learning
Francisco Giral, Ignacio G'omez, Soledad Le Clainche
The proliferation of unmanned aerial vehicles (UAVs) in controlled airspace presents significant risks, including potential collisions, disruptions to air traffic, and security threats. Ensuring the safe and efficient operation of airspace, particularly in urban environments and near critical infrastructure, necessitates effective methods to intercept unauthorized or non-cooperative UAVs. This work addresses the critical need for robust, adaptive systems capable of managing such threats through the use of Reinforcement Learning (RL). We present a novel approach utilizing RL to train fixed-wing UAV pursuer agents for intercepting dynamic evader targets. Our methodology explores both model-based and model-free RL algorithms, specifically DreamerV3, Truncated Quantile Critics (TQC), and Soft Actor-Critic (SAC). The training and evaluation of these algorithms were conducted under diverse scenarios, including unseen evasion strategies and environmental perturbations. Our approach leverages high-fidelity flight dynamics simulations to create realistic training environments. This research underscores the importance of developing intelligent, adaptive control systems for UAV interception, significantly contributing to the advancement of secure and efficient airspace management. It demonstrates the potential of RL to train systems capable of autonomously achieving these critical tasks.
Read more7/10/2024

0
DeepAir: A Multi-Agent Deep Reinforcement Learning Based Scheme for an Unknown User Location Problem
Baris Yamansavascilar, Atay Ozgovde, Cem Ersoy
The deployment of unmanned aerial vehicles (UAVs) in many different settings has provided various solutions and strategies for networking paradigms. Therefore, it reduces the complexity of the developments for the existing problems, which otherwise require more sophisticated approaches. One of those existing problems is the unknown user locations in an infrastructure-less environment in which users cannot connect to any communication device or computation-providing server, which is essential to task offloading in order to achieve the required quality of service (QoS). Therefore, in this study, we investigate this problem thoroughly and propose a novel deep reinforcement learning (DRL) based scheme, DeepAir. DeepAir considers all of the necessary steps including sensing, localization, resource allocation, and multi-access edge computing (MEC) to achieve QoS requirements for the offloaded tasks without violating the maximum tolerable delay. To this end, we use two types of UAVs including detector UAVs, and serving UAVs. We utilize detector UAVs as DRL agents which ensure sensing, localization, and resource allocation. On the other hand, we utilize serving UAVs to provide MEC features. Our experiments show that DeepAir provides a high task success rate by deploying fewer detector UAVs in the environment, which includes different numbers of users and user attraction points, compared to benchmark methods.
Read more8/13/2024

0
Trajectory Planning for Teleoperated Space Manipulators Using Deep Reinforcement Learning
Bo Xia, Xianru Tian, Bo Yuan, Zhiheng Li, Bin Liang, Xueqian Wang
Trajectory planning for teleoperated space manipulators involves challenges such as accurately modeling system dynamics, particularly in free-floating modes with non-holonomic constraints, and managing time delays that increase model uncertainty and affect control precision. Traditional teleoperation methods rely on precise dynamic models requiring complex parameter identification and calibration, while data-driven methods do not require prior knowledge but struggle with time delays. A novel framework utilizing deep reinforcement learning (DRL) is introduced to address these challenges. The framework incorporates three methods: Mapping, Prediction, and State Augmentation, to handle delays when delayed state information is received at the master end. The Soft Actor Critic (SAC) algorithm processes the state information to compute the next action, which is then sent to the remote manipulator for environmental interaction. Four environments are constructed using the MuJoCo simulation platform to account for variations in base and target fixation: fixed base and target, fixed base with rotated target, free-floating base with fixed target, and free-floating base with rotated target. Extensive experiments with both constant and random delays are conducted to evaluate the proposed methods. Results demonstrate that all three methods effectively address trajectory planning challenges, with State Augmentation showing superior efficiency and robustness.
Read more8/13/2024