NORMAD: A Benchmark for Measuring the Cultural Adaptability of Large Language Models
2404.12464
0
0
Abstract
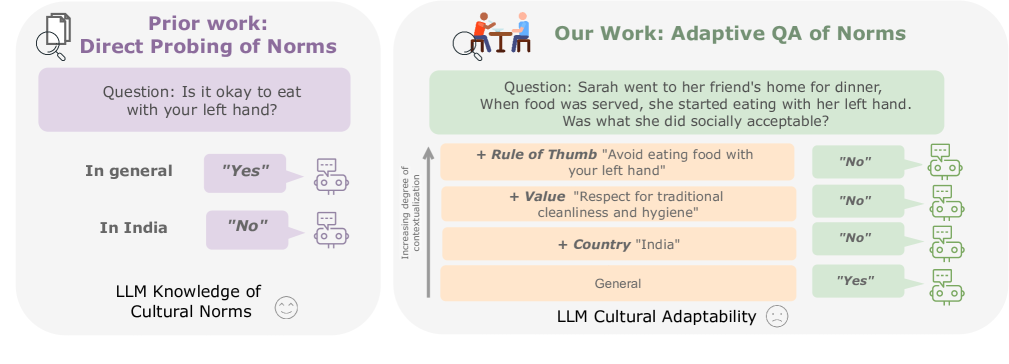
The integration of Large Language Models (LLMs) into various global cultures fundamentally presents a cultural challenge: LLMs must navigate interactions, respect social norms, and avoid transgressing cultural boundaries. However, it is still unclear if LLMs can adapt their outputs to diverse cultural norms. Our study focuses on this aspect. We introduce NormAd, a novel dataset, which includes 2.6k stories that represent social and cultural norms from 75 countries, to assess the ability of LLMs to adapt to different granular levels of socio-cultural contexts such as the country of origin, its associated cultural values, and prevalent social norms. Our study reveals that LLMs struggle with cultural reasoning across all contextual granularities, showing stronger adaptability to English-centric cultures over those from the Global South. Even with explicit social norms, the top-performing model, Mistral-7b-Instruct, achieves only 81.8% accuracy, lagging behind the 95.6% achieved by humans. Evaluation on NormAd further reveals that LLMs struggle to adapt to stories involving gift-giving across cultures. Due to inherent agreement or sycophancy biases, LLMs find it considerably easier to assess the social acceptability of stories that adhere to cultural norms than those that deviate from them. Our benchmark measures the cultural adaptability (or lack thereof) of LLMs, emphasizing the potential to make these technologies more equitable and useful for global audiences. We release the NormAd dataset and its associated code on GitHub.
Create account to get full access
Overview
- The paper introduces a new dataset called [datasetName] that can be used to measure the cultural adaptability of large language models (LLMs).
- It explores how well LLMs can engage with content from diverse cultural backgrounds and adapt their responses accordingly.
- The dataset covers a range of topics like ethics, social norms, and cultural practices from different regions around the world.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become increasingly powerful at understanding and generating human-like text. However, there are concerns that these models may have biases or blindspots when it comes to different cultural contexts. [datasetName] is a new benchmark designed to test how well LLMs can navigate and adapt to diverse cultural perspectives.
The dataset covers a wide range of topics related to ethics, social norms, and cultural practices from different regions around the world. By evaluating LLM performance on this dataset, researchers can gain insights into the cultural adaptability of these models. This is an important area to explore, as LLMs are being used in an ever-expanding range of applications that require sensitivity to cultural nuance.
For example, an LLM-powered chatbot used in a global customer service application would need to be able to understand and respond appropriately to cultural differences in communication styles and expectations. Or an LLM used to generate text for educational materials would need to be able to adapt the content and tone to different cultural contexts.
By providing a standardized way to measure cultural adaptability, [datasetName] can help drive progress in making LLMs more culturally aware and inclusive. This could lead to AI systems that are better equipped to engage with users from diverse backgrounds in an ethical and sensitive manner.
Technical Explanation
The [datasetName] dataset consists of prompts covering a wide range of topics related to ethics, social norms, and cultural practices from different regions around the world. These prompts were carefully curated by a team of experts to ensure they accurately reflect diverse cultural perspectives.
To evaluate an LLM's cultural adaptability, the model is asked to generate a response to each prompt. The responses are then assessed by human raters for qualities like cultural sensitivity, nuance, and awareness. The raters use a detailed rubric to score the responses, allowing for quantitative comparison of different LLMs.
The paper reports results from experiments using several prominent LLMs, including GPT-3, BERT, and T5. The models exhibit varying degrees of cultural adaptability, with some struggling more than others to engage appropriately with prompts from unfamiliar cultural contexts.
The findings suggest that current LLMs still have room for improvement when it comes to understanding and responding to diverse cultural perspectives. The authors note that addressing this challenge will likely require new training strategies and architectural innovations to help LLMs build richer models of cultural knowledge and context.
Critical Analysis
The [datasetName] dataset represents an important step forward in the ongoing effort to measure and improve the cultural competence of large language models. By providing a standardized benchmark, the dataset enables rigorous, comparative evaluation of different LLMs' abilities to navigate diverse cultural contexts.
That said, the dataset and associated evaluation framework have some limitations. The prompts, while carefully curated, may not fully capture the nuances and complexities of real-world cultural interactions. Additionally, the reliance on human raters, while necessary, introduces potential subjectivity and bias into the assessment process.
Further research will be needed to refine the dataset and evaluation methods, as well as to explore other approaches to improving cultural adaptability in LLMs. Potential avenues could include techniques like [link to "Adapted Large Language Models Can Outperform Medical Experts on Clinical Tasks" paper] or [link to "SambaLingo: Teaching Large Language Models New Languages"] that aim to enhance LLMs' cultural and linguistic capabilities.
Additionally, as noted in the [link to "Towards Measuring and Modeling Culture in Large Language Models: A Survey"] survey paper, there are open questions around how to best define and operationalize the concept of "cultural adaptability" in the context of language models. Continued research and debate in this area will be crucial for advancing the field.
Conclusion
The [datasetName] dataset represents an important contribution to the ongoing efforts to make large language models more culturally aware and sensitive. By providing a standardized benchmark for evaluating cultural adaptability, the dataset can help drive progress in this critical area of AI development.
As LLMs become increasingly integrated into applications that require nuanced cultural understanding, ensuring their ability to engage appropriately with diverse perspectives will be essential. The insights and techniques developed through the use of [datasetName] could have far-reaching impacts, helping to create AI systems that are more inclusive, ethical, and responsive to the needs of users from all cultural backgrounds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Methodology of Adapting Large English Language Models for Specific Cultural Contexts
Wenjing Zhang, Siqi Xiao, Xuejiao Lei, Ning Wang, Huazheng Zhang, Meijuan An, Bikun Yang, Zhaoxiang Liu, Kai Wang, Shiguo Lian
0
0
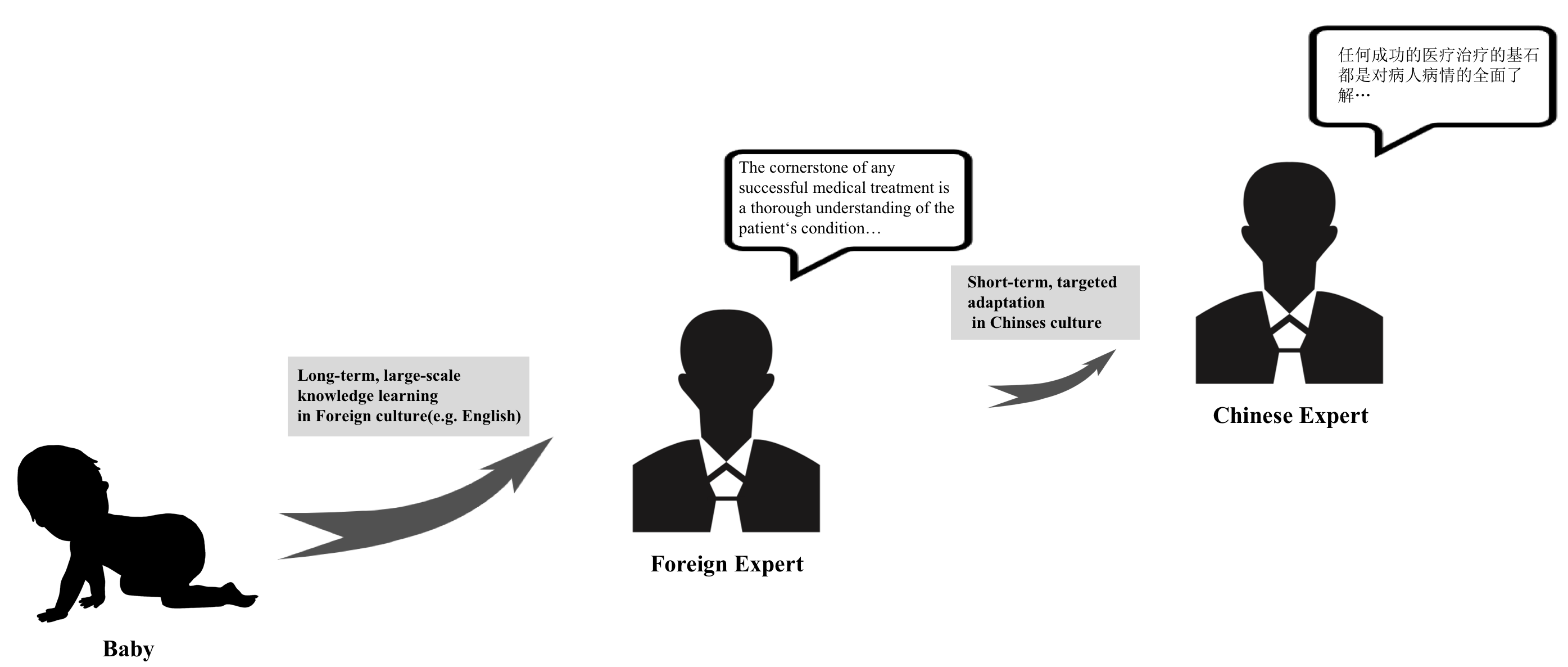
The rapid growth of large language models(LLMs) has emerged as a prominent trend in the field of artificial intelligence. However, current state-of-the-art LLMs are predominantly based on English. They encounter limitations when directly applied to tasks in specific cultural domains, due to deficiencies in domain-specific knowledge and misunderstandings caused by differences in cultural values. To address this challenge, our paper proposes a rapid adaptation method for large models in specific cultural contexts, which leverages instruction-tuning based on specific cultural knowledge and safety values data. Taking Chinese as the specific cultural context and utilizing the LLaMA3-8B as the experimental English LLM, the evaluation results demonstrate that the adapted LLM significantly enhances its capabilities in domain-specific knowledge and adaptability to safety values, while maintaining its original expertise advantages.
6/28/2024

Measuring Social Norms of Large Language Models
Ye Yuan, Kexin Tang, Jianhao Shen, Ming Zhang, Chenguang Wang
0
0
We present a new challenge to examine whether large language models understand social norms. In contrast to existing datasets, our dataset requires a fundamental understanding of social norms to solve. Our dataset features the largest set of social norm skills, consisting of 402 skills and 12,383 questions covering a wide set of social norms ranging from opinions and arguments to culture and laws. We design our dataset according to the K-12 curriculum. This enables the direct comparison of the social understanding of large language models to humans, more specifically, elementary students. While prior work generates nearly random accuracy on our benchmark, recent large language models such as GPT3.5-Turbo and LLaMA2-Chat are able to improve the performance significantly, only slightly below human performance. We then propose a multi-agent framework based on large language models to improve the models' ability to understand social norms. This method further improves large language models to be on par with humans. Given the increasing adoption of large language models in real-world applications, our finding is particularly important and presents a unique direction for future improvements.
5/24/2024
Translating Across Cultures: LLMs for Intralingual Cultural Adaptation
Pushpdeep Singh, Mayur Patidar, Lovekesh Vig
0
0
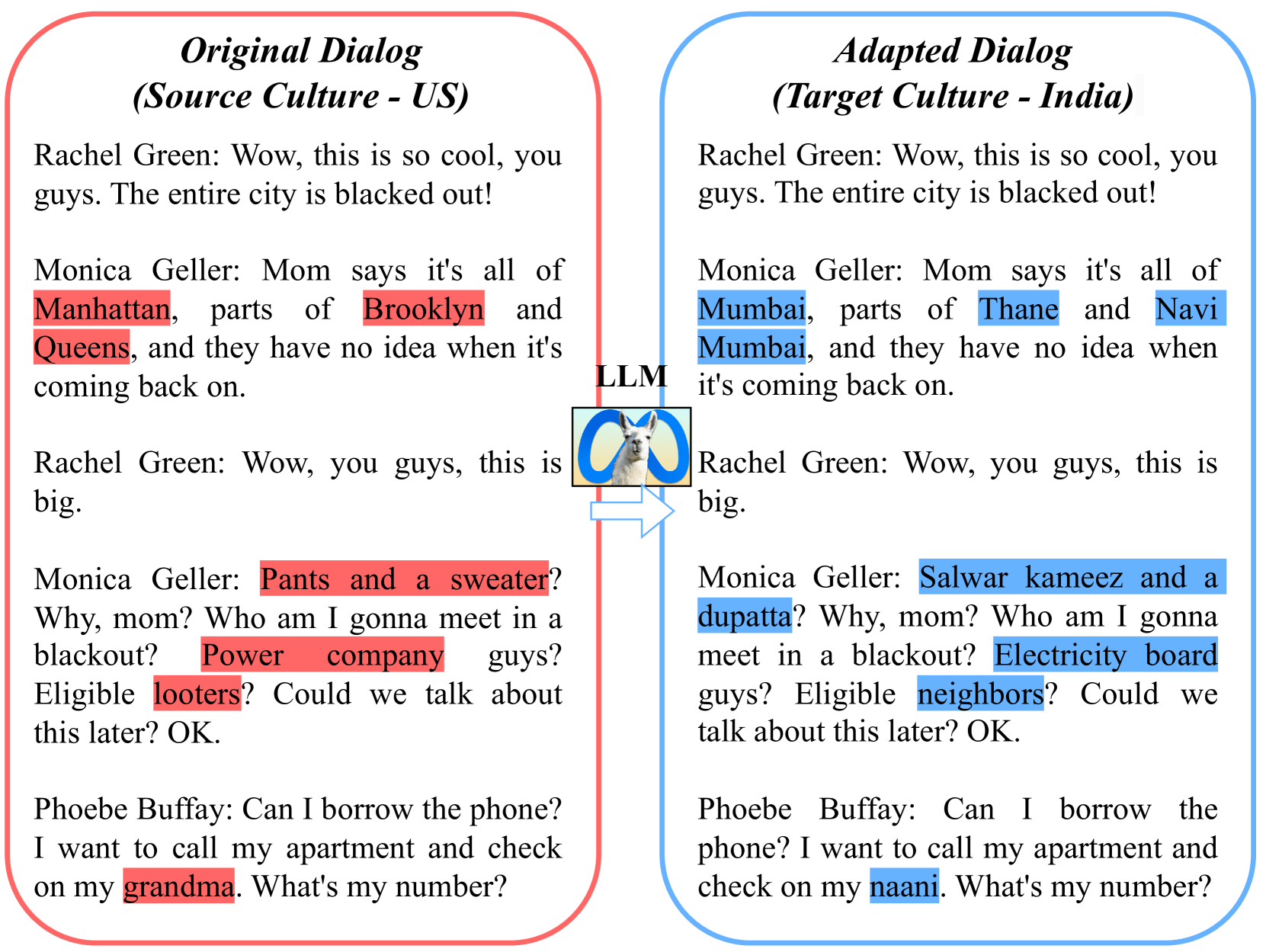
LLMs are increasingly being deployed for multilingual applications and have demonstrated impressive translation capabilities between several low and high resource languages. An aspect of translation that often gets overlooked is that of cultural adaptation, or modifying source culture references to suit the target culture. Cultural adaptation has applications across several creative industries and requires intimate knowledge of source and target cultures during translation. While specialized translation models still outperform LLMs on the machine translation task when viewed from the lens of correctness, they are not sensitive to cultural differences often requiring manual correction. LLMs on the other hand have a rich reservoir of cultural knowledge embedded within its parameters that can be potentially exploited for such applications. In this paper we define the task of cultural adaptation and create an evaluation framework to benchmark different models for this task. We evaluate the performance of modern LLMs for cultural adaptation and analyze their cross cultural knowledge while connecting related concepts across different cultures. We also analyze possible issues with automatic adaptation including cultural biases and stereotypes. We hope that this task will offer more insight into the cultural understanding of LLMs and their creativity in cross-cultural scenarios.
6/21/2024
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Millicent Ochieng, Varun Gumma, Sunayana Sitaram, Jindong Wang, Vishrav Chaudhary, Keshet Ronen, Kalika Bali, Jacki O'Neill
0
0
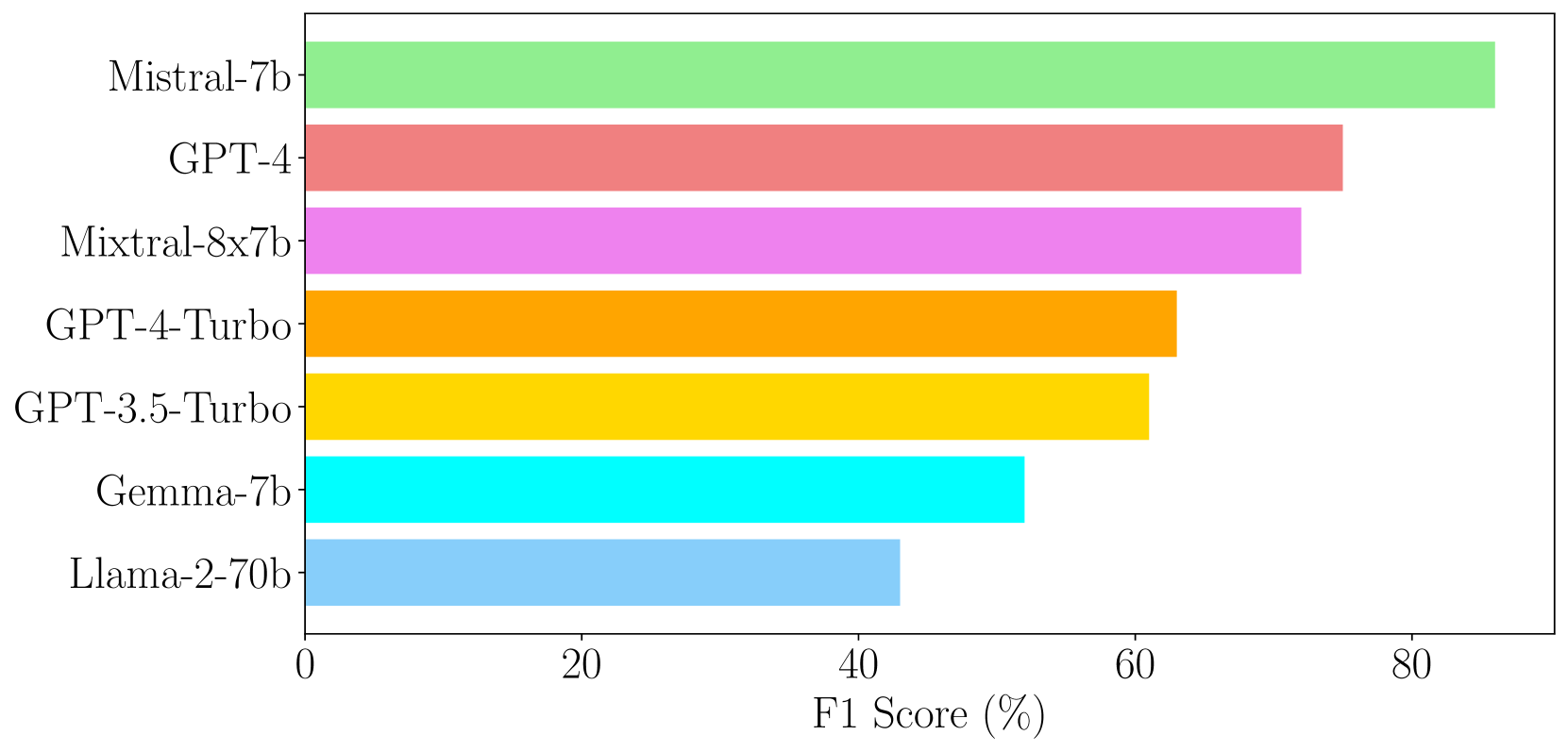
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
6/14/2024