Translating Across Cultures: LLMs for Intralingual Cultural Adaptation
2406.14504
0
0
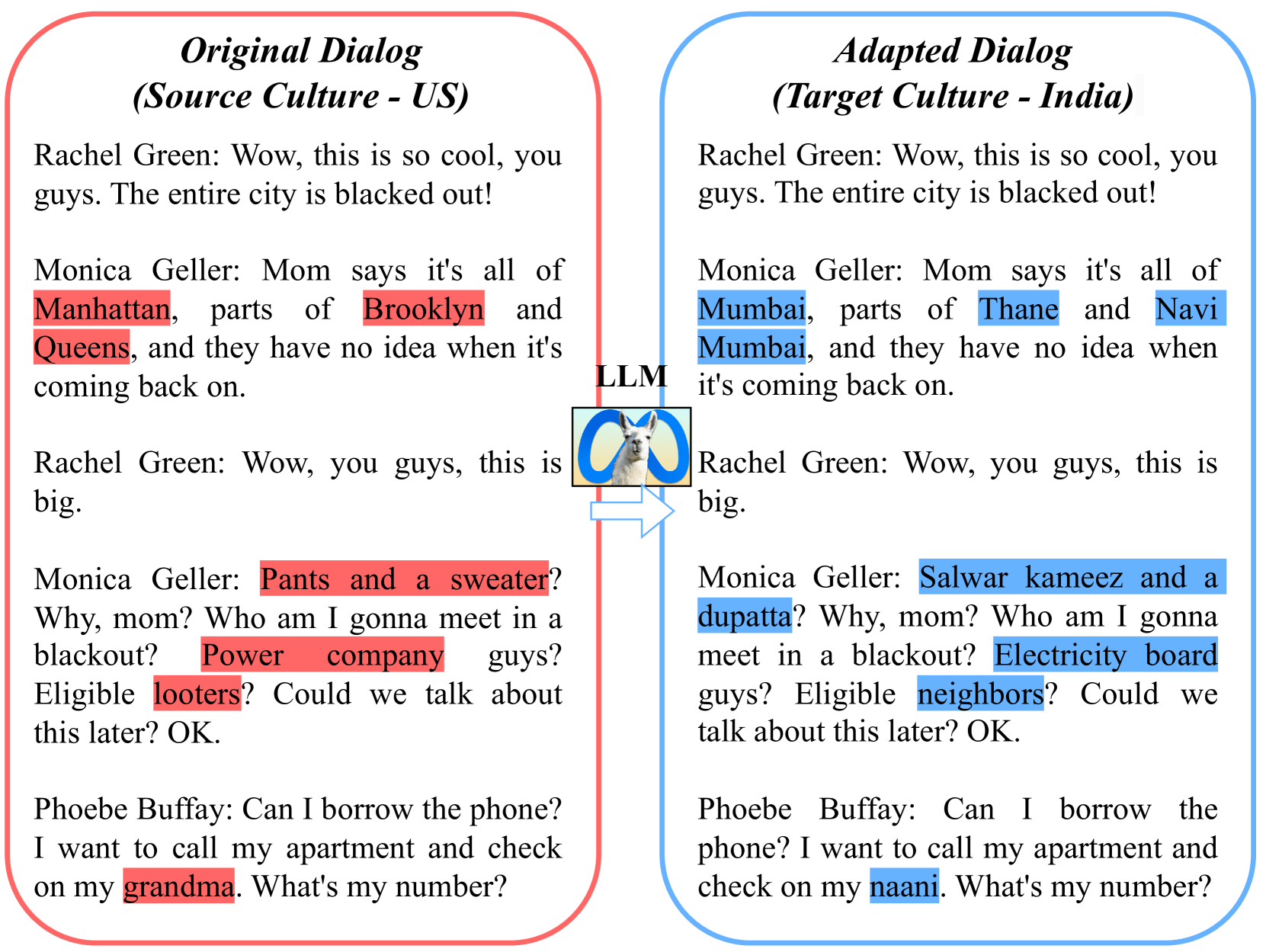
Abstract
LLMs are increasingly being deployed for multilingual applications and have demonstrated impressive translation capabilities between several low and high resource languages. An aspect of translation that often gets overlooked is that of cultural adaptation, or modifying source culture references to suit the target culture. Cultural adaptation has applications across several creative industries and requires intimate knowledge of source and target cultures during translation. While specialized translation models still outperform LLMs on the machine translation task when viewed from the lens of correctness, they are not sensitive to cultural differences often requiring manual correction. LLMs on the other hand have a rich reservoir of cultural knowledge embedded within its parameters that can be potentially exploited for such applications. In this paper we define the task of cultural adaptation and create an evaluation framework to benchmark different models for this task. We evaluate the performance of modern LLMs for cultural adaptation and analyze their cross cultural knowledge while connecting related concepts across different cultures. We also analyze possible issues with automatic adaptation including cultural biases and stereotypes. We hope that this task will offer more insight into the cultural understanding of LLMs and their creativity in cross-cultural scenarios.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) for intralingual cultural adaptation, which involves translating content to better fit the cultural context of the target audience within the same language.
- The authors investigate techniques for adapting LLMs to handle cultural differences and nuances, with the goal of improving the effectiveness and cultural relevance of language-related AI systems.
- The paper builds on previous research on evaluating LLMs for cultural nuance, cross-lingual transfer learning, and benchmarking cultural adaptability.
Plain English Explanation
The paper looks at using advanced AI language models to adapt content to different cultural contexts, even within the same language. For example, how can we take an English text and modify it to be more appropriate and meaningful for readers in the United States versus readers in the United Kingdom, even though they both speak English?
The key idea is that language is deeply tied to culture, so simply translating words is not enough - we need to also translate the cultural context and nuance. The authors explore techniques for training language models to be more culturally aware and sensitive, with the goal of making AI-generated content more effective and relevant for diverse audiences.
This builds on previous research on evaluating how well language models handle cultural factors, using language models to work with lower-resource languages, and benchmarking the cultural adaptability of language models. This paper aims to further advance the state of the art in this important area.
Technical Explanation
The paper first reviews relevant prior work, including research on evaluating the cultural effectiveness of language models, leveraging cross-lingual transfer learning to adapt to low-resource languages, and benchmarking cultural adaptability.
The authors then propose techniques for intralingual cultural adaptation, where the goal is to adapt language models to translate content within the same language (e.g. English) but for different cultural contexts. This involves fine-tuning language models on corpora that capture cultural differences, as well as developing specialized architectures and training procedures to imbue the models with cultural awareness and sensitivity.
The paper presents experiments evaluating these techniques on a variety of benchmarks and real-world tasks, demonstrating significant improvements in the cultural appropriateness and effectiveness of the adapted language models compared to baseline approaches. The authors also discuss the implications of this work for building more inclusive and effective AI-powered language systems.
Critical Analysis
The paper provides a thoughtful and systematic approach to the important challenge of cultural adaptation for language models. By going beyond just translating words and focusing on capturing cultural nuance, the authors make a compelling case for the need to advance the state of the art in this area.
That said, the paper acknowledges some key limitations and areas for further research. For instance, the proposed techniques may not generalize well to highly complex or rapidly evolving cultural contexts, and the evaluation metrics used may not fully capture all relevant aspects of cultural appropriateness. Additionally, issues around bias and fairness in language models are not deeply explored.
Further research is also needed to understand how these culturally-adapted language models might be integrated into end-to-end document-level systems and scaled to real-world applications. Exploring the intersections between cultural adaptation and other important AI capabilities, such as reasoning, grounding, and controllability, could also yield valuable insights.
Overall, this paper represents an important step forward in addressing a critical challenge for making language AI more inclusive and effective across diverse cultural contexts. The techniques and insights developed here can serve as a foundation for continued innovation in this rapidly evolving field.
Conclusion
This paper tackles the important challenge of using large language models (LLMs) to enable intralingual cultural adaptation - translating content to better fit the cultural context of the target audience, even within the same language.
By exploring techniques for fine-tuning and architecting LLMs to be more culturally aware and sensitive, the authors demonstrate significant improvements in the cultural appropriateness and effectiveness of AI-generated language. This work builds on previous research on evaluating cultural nuance, cross-lingual transfer learning, and benchmarking cultural adaptability.
While the paper acknowledges some limitations and areas for further research, it represents an important advance in making language AI systems more inclusive and relevant for diverse audiences. Continued innovation in this area, including exploring intersections with other AI capabilities, will be crucial for unlocking the full potential of language technology to serve the needs of a multicultural world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Methodology of Adapting Large English Language Models for Specific Cultural Contexts
Wenjing Zhang, Siqi Xiao, Xuejiao Lei, Ning Wang, Huazheng Zhang, Meijuan An, Bikun Yang, Zhaoxiang Liu, Kai Wang, Shiguo Lian
0
0
The rapid growth of large language models(LLMs) has emerged as a prominent trend in the field of artificial intelligence. However, current state-of-the-art LLMs are predominantly based on English. They encounter limitations when directly applied to tasks in specific cultural domains, due to deficiencies in domain-specific knowledge and misunderstandings caused by differences in cultural values. To address this challenge, our paper proposes a rapid adaptation method for large models in specific cultural contexts, which leverages instruction-tuning based on specific cultural knowledge and safety values data. Taking Chinese as the specific cultural context and utilizing the LLaMA3-8B as the experimental English LLM, the evaluation results demonstrate that the adapted LLM significantly enhances its capabilities in domain-specific knowledge and adaptability to safety values, while maintaining its original expertise advantages.
6/28/2024
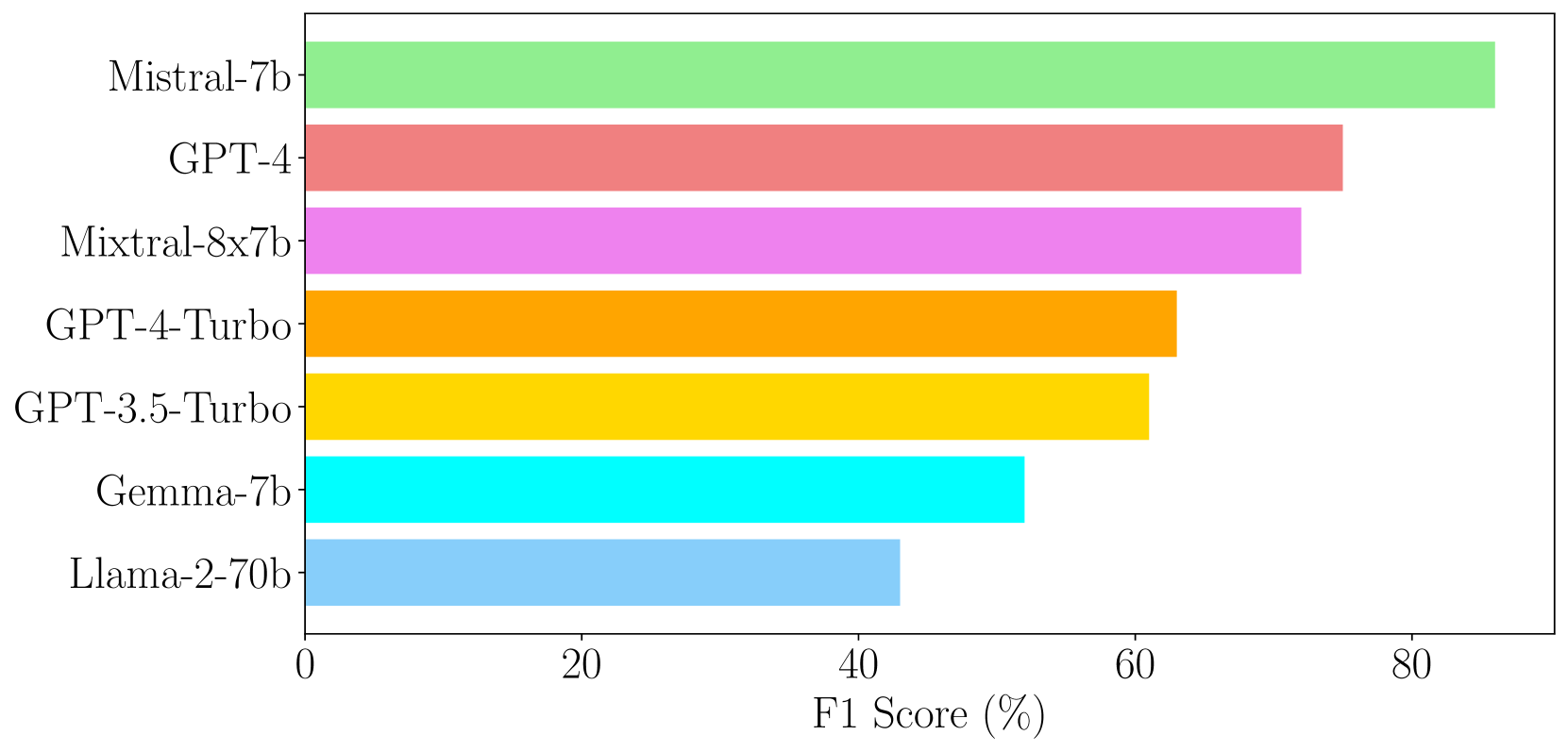
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Millicent Ochieng, Varun Gumma, Sunayana Sitaram, Jindong Wang, Vishrav Chaudhary, Keshet Ronen, Kalika Bali, Jacki O'Neill
0
0
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
6/14/2024
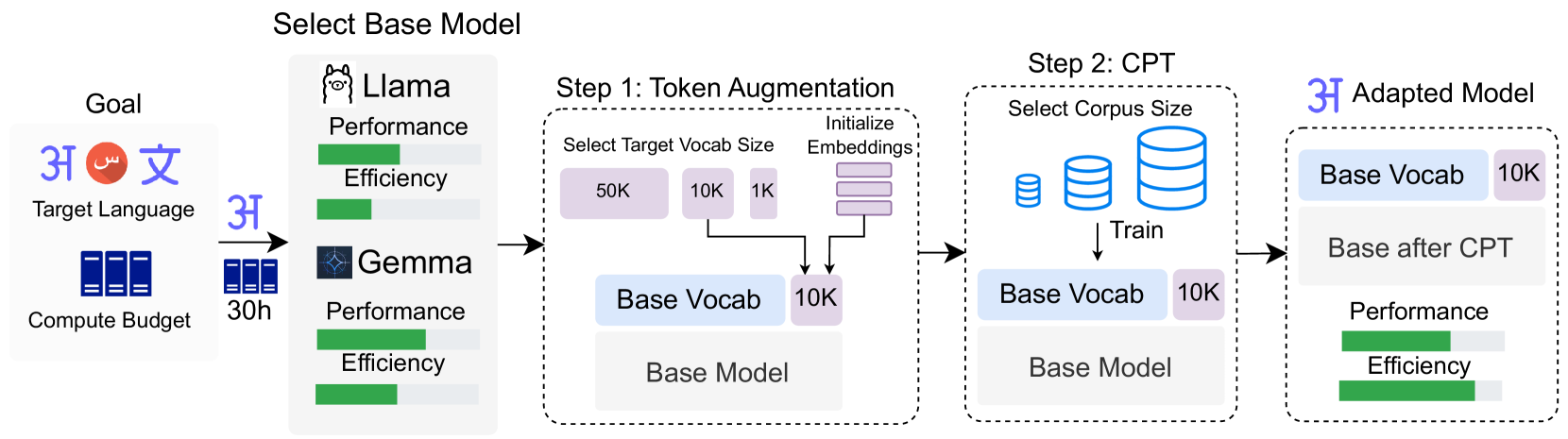
Exploring Design Choices for Building Language-Specific LLMs
Atula Tejaswi, Nilesh Gupta, Eunsol Choi
0
0
Despite rapid progress in large language models (LLMs), their performance on a vast majority of languages remain unsatisfactory. In this paper, we study building language-specific LLMs by adapting monolingual and multilingual LLMs. We conduct systematic experiments on how design choices (base model selection, vocabulary extension, and continued fine-tuning) impact the adapted LLM, both in terms of efficiency (how many tokens are needed to encode the same amount of information) and end task performance. We find that (1) the initial performance before the adaptation is not always indicative of the final performance. (2) Efficiency can easily improved with simple vocabulary extension and continued fine-tuning in most LLMs we study, and (3) The optimal adaptation method is highly language-dependent, and the simplest approach works well across various experimental settings. Adapting English-centric models can yield better results than adapting multilingual models despite their worse initial performance on low-resource languages. Together, our work lays foundations on efficiently building language-specific LLMs by adapting existing LLMs.
6/24/2024
Cross-Lingual Transfer Robustness to Lower-Resource Languages on Adversarial Datasets
Shadi Manafi, Nikhil Krishnaswamy
0
0
Multilingual Language Models (MLLMs) exhibit robust cross-lingual transfer capabilities, or the ability to leverage information acquired in a source language and apply it to a target language. These capabilities find practical applications in well-established Natural Language Processing (NLP) tasks such as Named Entity Recognition (NER). This study aims to investigate the effectiveness of a source language when applied to a target language, particularly in the context of perturbing the input test set. We evaluate on 13 pairs of languages, each including one high-resource language (HRL) and one low-resource language (LRL) with a geographic, genetic, or borrowing relationship. We evaluate two well-known MLLMs--MBERT and XLM-R--on these pairs, in native LRL and cross-lingual transfer settings, in two tasks, under a set of different perturbations. Our findings indicate that NER cross-lingual transfer depends largely on the overlap of entity chunks. If a source and target language have more entities in common, the transfer ability is stronger. Models using cross-lingual transfer also appear to be somewhat more robust to certain perturbations of the input, perhaps indicating an ability to leverage stronger representations derived from the HRL. Our research provides valuable insights into cross-lingual transfer and its implications for NLP applications, and underscores the need to consider linguistic nuances and potential limitations when employing MLLMs across distinct languages.
4/1/2024