Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
2305.15083
0
0
💬
Abstract
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) like ChatGPT and GPT-4 have shown impressive abilities in multilingual translation, even without being explicitly trained on parallel corpora.
- This paper presents a detailed analysis of how these LLMs obtain their translation capabilities by fine-tuning a multilingual model called XGLM-7B.
- The researchers found that multilingual LLMs have stronger translation abilities than previously demonstrated, with performance depending on the language's similarity to English and the amount of data used during pre-training.
- The LLMs' ability to follow translation instructions relies on their understanding of those instructions and the alignment between different languages.
- Through multilingual fine-tuning, the LLMs can learn to perform well on translation tasks, even for language pairs not seen during the instruction tuning phase.
Plain English Explanation
Large language models (LLMs) like ChatGPT and GPT-4 have surprised people with their ability to translate between different languages, even though they weren't explicitly trained on translation tasks. This paper looks closely at how these models are able to do this.
The researchers took a multilingual language model called XGLM-7B and fine-tuned it to perform translation tasks, following specific instructions. What they found is that these LLMs are even better at translation than we thought. Their performance depends on how similar the language is to English and how much data was used to train the model initially.
The key to the LLMs' translation abilities seems to be their understanding of the translation instructions and how the different languages are aligned with each other. Even for language pairs the model had never seen before, it was able to learn to translate well through this multilingual fine-tuning process.
Technical Explanation
The researchers fine-tuned a large, multilingual pre-trained language model called XGLM-7B to perform translation tasks following given instructions. Their analysis provides several insights:
-
Multilingual LLMs have stronger translation capabilities than previously demonstrated. The performance on a given language depends on its similarity to English and the amount of data used during the pre-training phase.
-
The LLMs' ability to follow translation instructions relies on their understanding of those instructions and the alignment between the different languages. Through multilingual fine-tuning, the model can learn to translate well even for language pairs that were not seen during the instruction tuning phase.
The researchers designed experiments to test the translation abilities of the fine-tuned XGLM-7B model. They evaluated its performance on a variety of language pairs and examined how factors like language similarity and pre-training data volume impacted the results.
By closely examining the model's behavior, the researchers were able to gain insights into the mechanisms underlying the LLMs' surprising multilingual translation capabilities, which go beyond what was previously known. This suggests that large language models could be further improved for better multilingual translation by guiding them with appropriate instructions and leveraging their ability to learn from diverse data.
Critical Analysis
The paper provides a thorough analysis of how multilingual LLMs acquire translation abilities, but it also acknowledges some limitations and areas for further research.
One limitation is that the study focused on a single multilingual model, XGLM-7B. It would be valuable to see if the findings hold true for other large language models and multilingual architectures as well. Examining a broader range of models could lead to a more comprehensive understanding of this phenomenon.
Additionally, the paper does not delve into the potential biases or errors that may arise in the LLMs' translation outputs. Further research is needed to assess the quality, reliability, and fairness of the translations produced by these models.
Overall, this paper offers a thought-provoking exploration of the mechanisms underlying multilingual translation capabilities in large language models. The insights presented could inform future efforts to improve and harness the translation abilities of these powerful AI systems.
Conclusion
This research provides valuable insights into how large language models like ChatGPT and GPT-4 are able to perform multilingual translation tasks, even without being explicitly trained on parallel corpora. The key findings are:
- Multilingual LLMs have stronger translation abilities than previously shown, with performance depending on the language's similarity to English and the amount of pre-training data.
- The LLMs' translation capabilities rely on their understanding of the translation instructions and the alignment between different languages.
- Through multilingual fine-tuning, the LLMs can learn to translate well even for language pairs not seen during the instruction tuning phase.
These findings suggest that large language models could be further improved for multilingual translation by guiding them with appropriate instructions and leveraging their ability to learn from diverse data. As the field of AI continues to advance, research like this will be crucial for developing more capable and effective translation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024

New!GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024
💬
Empirical study of pretrained multilingual language models for zero-shot cross-lingual knowledge transfer in generation
Nadezhda Chirkova, Sheng Liang, Vassilina Nikoulina
0
0
Zero-shot cross-lingual knowledge transfer enables the multilingual pretrained language model (mPLM), finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work, we test alternative mPLMs, such as mBART and NLLB-200, considering full finetuning and parameter-efficient finetuning with adapters. We find that mBART with adapters performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. We also underline the importance of tuning learning rate used for finetuning, which helps to alleviate the problem of generation in the wrong language.
4/23/2024
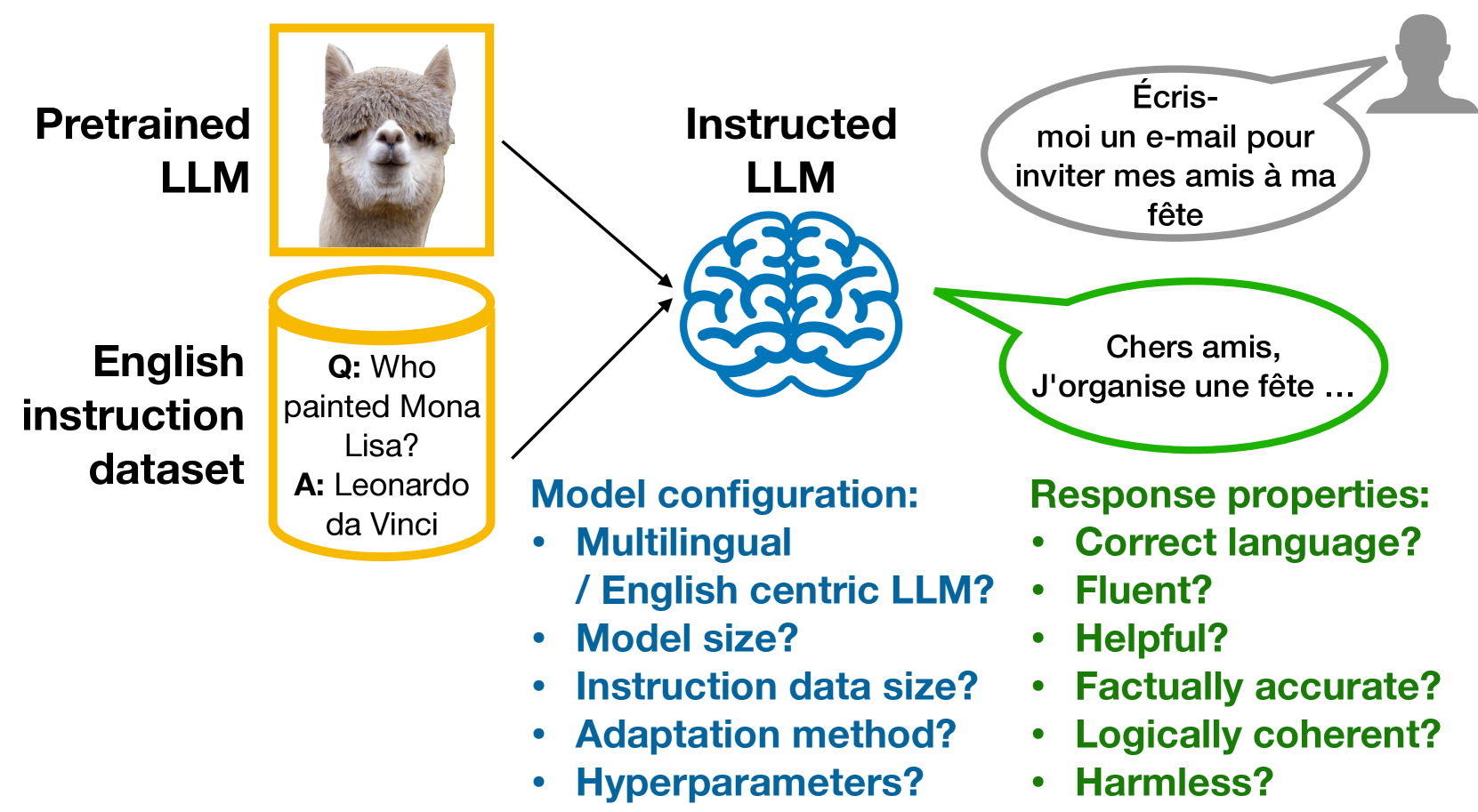
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024