NYK-MS: A Well-annotated Multi-modal Metaphor and Sarcasm Understanding Benchmark on Cartoon-Caption Dataset

0

Sign in to get full access
Overview
- This paper introduces NYK-MS, a well-annotated multi-modal dataset for metaphor and sarcasm understanding on cartoon captions.
- The dataset contains over 25,000 cartoon-caption pairs with annotations for metaphor, sarcasm, and multimodal linguistic features.
- The authors benchmark the performance of several state-of-the-art models on this dataset, revealing key insights into the challenges of multimodal metaphor and sarcasm understanding.
Plain English Explanation
The researchers have created a new dataset called NYK-MS that contains over 25,000 cartoon-caption pairs. Each pair has been carefully annotated to indicate whether the caption contains metaphor, sarcasm, or both. Additionally, the dataset includes annotations for various linguistic features that are relevant to understanding these figurative language phenomena.
The key contribution of this work is providing a high-quality, well-curated benchmark for evaluating the performance of AI systems on the task of multimodal metaphor and sarcasm understanding. The authors test several state-of-the-art models on this dataset and share insights into the challenges these models face. This information can help guide future research and development efforts in this important area of natural language processing.
Metaphor and sarcasm are common in human communication, but they can be difficult for AI systems to comprehend, especially when visual information is also involved. By creating this specialized dataset and sharing their findings, the researchers are helping to advance the field of multimodal language understanding, which has far-reaching applications in areas like conversational AI, content moderation, and sentiment analysis.
Technical Explanation
The NYK-MS dataset consists of over 25,000 cartoon-caption pairs, each of which has been manually annotated for the presence of metaphor, sarcasm, or both. The dataset also includes annotations for various linguistic features, such as sentiment, emotion, concreteness, and imageability. This rich set of annotations allows for a comprehensive evaluation of a model's ability to understand the nuanced interplay between visual and textual information in the context of figurative language.
The authors benchmark the performance of several state-of-the-art multimodal models on the NYK-MS dataset, including LINK: Evaluating Large Language Models' Ability using Psychiatric Notes, LINK: SarcasmBench: Towards Evaluating Large Language Models' Sarcasm Understanding Ability, and LINK: VyangNet: A Novel Multi-modal Sarcasm Recognition Model. The results reveal that even the most advanced models struggle to achieve high performance on the metaphor and sarcasm understanding tasks, highlighting the significant challenges involved in this area of research.
Critical Analysis
The NYK-MS dataset represents a valuable contribution to the field of multimodal language understanding, as it provides a well-annotated, challenging benchmark for evaluating the performance of AI systems. The authors have been careful to ensure the dataset is of high quality, with clear and consistent annotation guidelines.
However, the paper does acknowledge several limitations of the dataset and the experimental setup. For example, the dataset is limited to cartoon-caption pairs, which may not fully capture the diversity of real-world multimodal contexts. Additionally, the authors note that the performance of the tested models is still far from human-level, suggesting that significant progress is needed to develop truly robust and generalizable multimodal language understanding capabilities.
Readers are encouraged to carefully consider the implications of the research findings and to think critically about the potential pitfalls and areas for further investigation. For example, the authors did not explore the effects of different training data sizes or the use of more advanced model architectures, which could provide additional insights into the challenges of this task.
Conclusion
The NYK-MS dataset and the associated benchmarking results presented in this paper represent an important step forward in the field of multimodal metaphor and sarcasm understanding. By providing a high-quality, well-annotated dataset and revealing the current limitations of state-of-the-art models, the authors have laid the groundwork for future research and development efforts in this critical area of natural language processing.
The insights gained from this work can inform the design of more effective AI systems for a wide range of applications, from conversational interfaces to content moderation and sentiment analysis. As the field of multimodal language understanding continues to evolve, the NYK-MS dataset and the lessons learned from this study will undoubtedly play a key role in driving progress and unlocking new possibilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NYK-MS: A Well-annotated Multi-modal Metaphor and Sarcasm Understanding Benchmark on Cartoon-Caption Dataset
Ke Chang, Hao Li, Junzhao Zhang, Yunfang Wu
Metaphor and sarcasm are common figurative expressions in people's communication, especially on the Internet or the memes popular among teenagers. We create a new benchmark named NYK-MS (NewYorKer for Metaphor and Sarcasm), which contains 1,583 samples for metaphor understanding tasks and 1,578 samples for sarcasm understanding tasks. These tasks include whether it contains metaphor/sarcasm, which word or object contains metaphor/sarcasm, what does it satirize and why does it contains metaphor/sarcasm, all of the 7 tasks are well-annotated by at least 3 annotators. We annotate the dataset for several rounds to improve the consistency and quality, and use GUI and GPT-4V to raise our efficiency. Based on the benchmark, we conduct plenty of experiments. In the zero-shot experiments, we show that Large Language Models (LLM) and Large Multi-modal Models (LMM) can't do classification task well, and as the scale increases, the performance on other 5 tasks improves. In the experiments on traditional pre-train models, we show the enhancement with augment and alignment methods, which prove our benchmark is consistent with previous dataset and requires the model to understand both of the two modalities.
Read more9/4/2024
0
Evaluating Large Language Models' Ability Using a Psychiatric Screening Tool Based on Metaphor and Sarcasm Scenarios
Hiromu Yakura
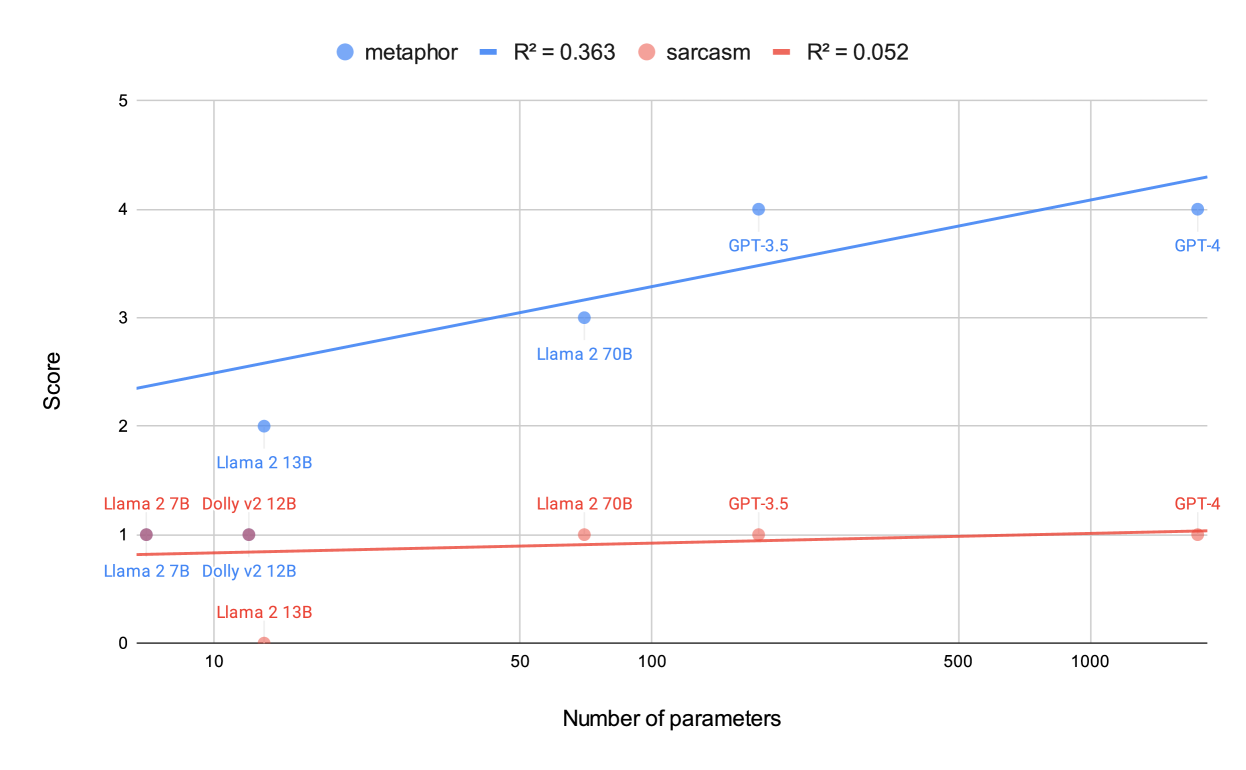
Metaphors and sarcasm are precious fruits of our highly evolved social communication skills. However, children with the condition then known as Asperger syndrome are known to have difficulties in comprehending sarcasm, even if they possess adequate verbal IQs for understanding metaphors. Accordingly, researchers had employed a screening test that assesses metaphor and sarcasm comprehension to distinguish Asperger syndrome from other conditions with similar external behaviors (e.g., attention-deficit/hyperactivity disorder). This study employs a standardized test to evaluate recent large language models' (LLMs) understanding of nuanced human communication. The results indicate improved metaphor comprehension with increased model parameters; however, no similar improvement was observed for sarcasm comprehension. Considering that a human's ability to grasp sarcasm has been associated with the amygdala, a pivotal cerebral region for emotional learning, a distinctive strategy for training LLMs would be imperative to imbue them with the ability in a cognitively grounded manner.
Read more7/23/2024

0
Towards Evaluating Large Language Models on Sarcasm Understanding
Yazhou Zhang, Chunwang Zou, Zheng Lian, Prayag Tiwari, Jing Qin
In the era of large language models (LLMs), the task of ``System I''~-~the fast, unconscious, and intuitive tasks, e.g., sentiment analysis, text classification, etc., have been argued to be successfully solved. However, sarcasm, as a subtle linguistic phenomenon, often employs rhetorical devices like hyperbole and figuration to convey true sentiments and intentions, involving a higher level of abstraction than sentiment analysis. There is growing concern that the argument about LLMs' success may not be fully tenable when considering sarcasm understanding. To address this question, we select eleven SOTA LLMs and eight SOTA pre-trained language models (PLMs) and present comprehensive evaluations on six widely used benchmark datasets through different prompting approaches, i.e., zero-shot input/output (IO) prompting, few-shot IO prompting, chain of thought (CoT) prompting. Our results highlight three key findings: (1) current LLMs underperform supervised PLMs based sarcasm detection baselines across six sarcasm benchmarks. This suggests that significant efforts are still required to improve LLMs' understanding of human sarcasm. (2) GPT-4 consistently and significantly outperforms other LLMs across various prompting methods, with an average improvement of 14.0%$uparrow$. Claude 3 and ChatGPT demonstrate the next best performance after GPT-4. (3) Few-shot IO prompting method outperforms the other two methods: zero-shot IO and few-shot CoT. The reason is that sarcasm detection, being a holistic, intuitive, and non-rational cognitive process, is argued not to adhere to step-by-step logical reasoning, making CoT less effective in understanding sarcasm compared to its effectiveness in mathematical reasoning tasks.
Read more8/27/2024
👁️
0
VyAnG-Net: A Novel Multi-Modal Sarcasm Recognition Model by Uncovering Visual, Acoustic and Glossary Features
Ananya Pandey, Dinesh Kumar Vishwakarma
Various linguistic and non-linguistic clues, such as excessive emphasis on a word, a shift in the tone of voice, or an awkward expression, frequently convey sarcasm. The computer vision problem of sarcasm recognition in conversation aims to identify hidden sarcastic, criticizing, and metaphorical information embedded in everyday dialogue. Prior, sarcasm recognition has focused mainly on text. Still, it is critical to consider all textual information, audio stream, facial expression, and body position for reliable sarcasm identification. Hence, we propose a novel approach that combines a lightweight depth attention module with a self-regulated ConvNet to concentrate on the most crucial features of visual data and an attentional tokenizer based strategy to extract the most critical context-specific information from the textual data. The following is a list of the key contributions that our experimentation has made in response to performing the task of Multi-modal Sarcasm Recognition: an attentional tokenizer branch to get beneficial features from the glossary content provided by the subtitles; a visual branch for acquiring the most prominent features from the video frames; an utterance-level feature extraction from acoustic content and a multi-headed attention based feature fusion branch to blend features obtained from multiple modalities. Extensive testing on one of the benchmark video datasets, MUSTaRD, yielded an accuracy of 79.86% for speaker dependent and 76.94% for speaker independent configuration demonstrating that our approach is superior to the existing methods. We have also conducted a cross-dataset analysis to test the adaptability of VyAnG-Net with unseen samples of another dataset MUStARD++.
Read more8/21/2024