Object Instance Retrieval in Assistive Robotics: Leveraging Fine-Tuned SimSiam with Multi-View Images Based on 3D Semantic Map
2404.09647
0
0

Abstract
Robots that assist in daily life are required to locate specific instances of objects that match the user's desired object in the environment. This task is known as Instance-Specific Image Goal Navigation (InstanceImageNav), which requires a model capable of distinguishing between different instances within the same class. One significant challenge in robotics is that when a robot observes the same object from various 3D viewpoints, its appearance may differ greatly, making it difficult to recognize and locate the object accurately. In this study, we introduce a method, SimView, that leverages multi-view images based on a 3D semantic map of the environment and self-supervised learning by SimSiam to train an instance identification model on-site. The effectiveness of our approach is validated using a photorealistic simulator, Habitat Matterport 3D, created by scanning real home environments. Our results demonstrate a 1.7-fold improvement in task accuracy compared to CLIP, which is pre-trained multimodal contrastive learning for object search. This improvement highlights the benefits of our proposed fine-tuning method in enhancing the performance of assistive robots in InstanceImageNav tasks. The project website is https://emergentsystemlabstudent.github.io/MultiViewRetrieve/.
Create account to get full access
Overview
- This paper presents a system for object instance retrieval in assistive robotics, leveraging a fine-tuned SimSiam model and multi-view images based on a 3D semantic map.
- The proposed approach aims to enable robots to efficiently locate and identify specific objects within indoor environments, a key capability for assistive robotics applications.
- The system utilizes a 3D semantic map to generate multi-view images of target objects, which are then used to fine-tune a SimSiam model for effective instance-level recognition.
Plain English Explanation
The paper describes a technique to help robots quickly find and recognize specific objects in a room. This is an important capability for assistive robots that need to locate and interact with particular items, like a user's coffee mug or car keys.
The key idea is to use a 3D map of the environment that labels different surfaces and objects. From this map, the system can generate multiple views of a target object, like a mug from different angles. These multi-view images are then used to fine-tune a machine learning model called SimSiam, which learns to recognize that specific mug instance.
By fine-tuning SimSiam on these multiple views of the target object, the system becomes adept at quickly detecting and identifying that particular mug when the robot encounters it in the real world. This allows the robot to efficiently locate and interact with the desired object, which is a crucial skill for assistive robots to have.
Technical Explanation
The paper proposes an approach for object instance retrieval in assistive robotics that leverages a fine-tuned SimSiam model and multi-view images based on a 3D semantic map.
The system first constructs a 3D semantic map of the environment, which labels different surfaces and objects. Using this map, the approach can generate multiple camera views of a target object, capturing it from various angles. These multi-view images are then used to fine-tune a pre-trained SimSiam model, a self-supervised learning technique that learns robust visual representations.
By fine-tuning SimSiam on the multi-view images of the target object, the model becomes specialized at recognizing that specific instance. This allows the robot to efficiently locate and identify the desired object when encountering it in the real world, a key capability for assistive robotics applications.
The authors evaluate their approach on a dataset of household objects and demonstrate its effectiveness in object instance retrieval compared to other techniques.
Critical Analysis
The paper presents a promising approach for enabling assistive robots to efficiently locate and identify specific objects in indoor environments. By leveraging a 3D semantic map and fine-tuning a SimSiam model on multi-view images, the system appears to achieve strong object instance retrieval performance.
However, the authors do not extensively discuss potential limitations or caveats of their approach. For example, the reliance on a 3D semantic map may limit the system's applicability to environments where such detailed maps are not available. Additionally, the fine-tuning process may require a significant amount of training data for each target object, which could be a challenge in real-world deployments.
Further research could explore ways to reduce the amount of labeled data needed for fine-tuning, potentially through more advanced self-supervised or few-shot learning techniques. Investigating the robustness of the system to changes in object appearance or occlusion would also be valuable.
Conclusion
This paper presents a novel approach for enabling assistive robots to efficiently locate and recognize specific objects in indoor environments. By combining a 3D semantic map, multi-view images, and a fine-tuned SimSiam model, the system demonstrates strong performance in object instance retrieval tasks.
The proposed technique has the potential to significantly improve the capabilities of assistive robots, allowing them to more effectively interact with and manipulate the objects that users require. As the field of assistive robotics continues to advance, approaches like the one described in this paper will be crucial for developing robots that can seamlessly integrate into and assist in human environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Laksh Nanwani, Kumaraditya Gupta, Aditya Mathur, Swayam Agrawal, A. H. Abdul Hafez, K. Madhava Krishna
0
0
Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
4/30/2024

Real-world Instance-specific Image Goal Navigation for Service Robots: Bridging the Domain Gap with Contrastive Learning
Taichi Sakaguchi, Akira Taniguchi, Yoshinobu Hagiwara, Lotfi El Hafi, Shoichi Hasegawa, Tadahiro Taniguchi
0
0
Improving instance-specific image goal navigation (InstanceImageNav), which locates the identical object in a real-world environment from a query image, is essential for robotic systems to assist users in finding desired objects. The challenge lies in the domain gap between low-quality images observed by the moving robot, characterized by motion blur and low-resolution, and high-quality query images provided by the user. Such domain gaps could significantly reduce the task success rate but have not been the focus of previous work. To address this, we propose a novel method called Few-shot Cross-quality Instance-aware Adaptation (CrossIA), which employs contrastive learning with an instance classifier to align features between massive low- and few high-quality images. This approach effectively reduces the domain gap by bringing the latent representations of cross-quality images closer on an instance basis. Additionally, the system integrates an object image collection with a pre-trained deblurring model to enhance the observed image quality. Our method fine-tunes the SimSiam model, pre-trained on ImageNet, using CrossIA. We evaluated our method's effectiveness through an InstanceImageNav task with 20 different types of instances, where the robot identifies the same instance in a real-world environment as a high-quality query image. Our experiments showed that our method improves the task success rate by up to three times compared to the baseline, a conventional approach based on SuperGlue. These findings highlight the potential of leveraging contrastive learning and image enhancement techniques to bridge the domain gap and improve object localization in robotic applications. The project website is https://emergentsystemlabstudent.github.io/DomainBridgingNav/.
4/16/2024
🤿
Unknown Object Grasping for Assistive Robotics
Elle Miller, Maximilian Durner, Matthias Humt, Gabriel Quere, Wout Boerdijk, Ashok M. Sundaram, Freek Stulp, Jorn Vogel
0
0
We propose a novel pipeline for unknown object grasping in shared robotic autonomy scenarios. State-of-the-art methods for fully autonomous scenarios are typically learning-based approaches optimised for a specific end-effector, that generate grasp poses directly from sensor input. In the domain of assistive robotics, we seek instead to utilise the user's cognitive abilities for enhanced satisfaction, grasping performance, and alignment with their high level task-specific goals. Given a pair of stereo images, we perform unknown object instance segmentation and generate a 3D reconstruction of the object of interest. In shared control, the user then guides the robot end-effector across a virtual hemisphere centered around the object to their desired approach direction. A physics-based grasp planner finds the most stable local grasp on the reconstruction, and finally the user is guided by shared control to this grasp. In experiments on the DLR EDAN platform, we report a grasp success rate of 87% for 10 unknown objects, and demonstrate the method's capability to grasp objects in structured clutter and from shelves.
5/7/2024
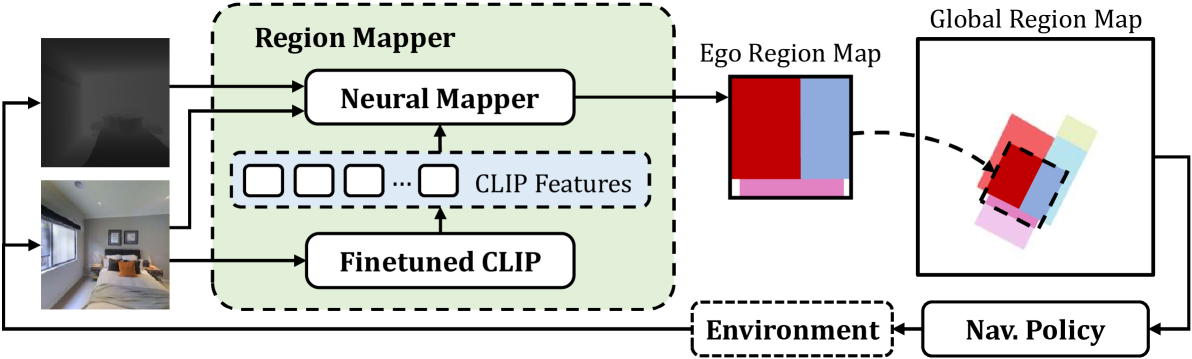
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Roberto Bigazzi, Lorenzo Baraldi, Shreyas Kousik, Rita Cucchiara, Marco Pavone
0
0
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
4/16/2024