Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
2404.17922
0
0

Abstract
Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
Create account to get full access
Overview
• This paper presents a novel approach for open-set 3D semantic instance mapping, called O3D-SIM, which aims to address the challenge of vision-language navigation in complex indoor environments. • The proposed method leverages 3D semantic instance information to construct a richer representation of the environment, going beyond traditional 2D or 3D occupancy maps. • The paper introduces a novel dataset and benchmark for evaluating open-set 3D semantic instance mapping, which includes diverse indoor scenes and a wide range of object categories.
Plain English Explanation
The paper focuses on a problem called vision-language navigation, where a robot or agent needs to navigate through a complex indoor environment based on natural language instructions. To address this challenge, the researchers developed a new approach called O3D-SIM, which creates a detailed 3D map of the environment that includes not just the physical layout, but also the specific objects and their categories.
Traditionally, robots have used simple 2D or 3D maps to navigate, but these don't provide much detail about the contents of the environment. O3D-SIM aims to create a richer representation by identifying individual objects and their semantic categories, such as "table," "chair," or "plant." This additional information can help the robot better understand the environment and follow more complex language instructions, like "Go to the table next to the plant."
To evaluate this new approach, the researchers also created a new dataset and benchmark, which includes a variety of indoor scenes and a wide range of object categories. This will allow other researchers to test and compare different methods for this type of open-set 3D semantic instance mapping.
Technical Explanation
The O3D-SIM approach combines several key components to construct a detailed 3D semantic instance map of the environment. First, it uses a 3D object detector to identify individual objects and their locations in the 3D point cloud. This is combined with a semantic segmentation model to classify each object into a specific category, such as "chair" or "table."
To handle the challenge of "open-set" mapping, where the robot may encounter objects it has not been trained on, the system includes a novel open-set object recognition module. This allows the robot to detect and categorize previously unseen objects, expanding the set of known object classes over time.
The resulting 3D semantic instance map provides a rich representation of the environment, capturing both the physical layout and the semantic content. This information can then be used to guide the robot's navigation, allowing it to follow more complex language instructions that refer to specific objects and their spatial relationships.
The researchers evaluate their approach on a new benchmark dataset, which includes a variety of indoor scenes and a wide range of object categories. The results demonstrate the advantages of the O3D-SIM approach compared to traditional 2D or 3D mapping methods, particularly in terms of the robot's ability to understand and navigate complex environments based on natural language instructions.
Critical Analysis
The O3D-SIM approach represents a significant advancement in the field of vision-language navigation, but it also has some potential limitations and areas for further research. One key challenge is the scalability of the open-set object recognition module, as the robot's knowledge base must continue to expand to handle increasingly diverse environments.
Additionally, the current evaluation is limited to static indoor environments, but real-world scenarios often involve dynamic elements, such as moving people or objects. Incorporating mechanisms to handle these dynamic aspects could be an important area for future work.
Finally, while the benchmark dataset provides a valuable resource for evaluating 3D semantic instance mapping, it may not fully capture the complexity and variability of real-world indoor environments. Expanding the dataset or developing additional benchmarks could help to further validate the approach and identify potential areas for improvement.
Conclusion
The O3D-SIM paper presents a novel approach for open-set 3D semantic instance mapping, which has the potential to significantly improve the performance of vision-language navigation systems in complex indoor environments. By capturing detailed information about the objects and their spatial relationships, the system can better understand and respond to natural language instructions, opening up new possibilities for human-robot interaction and assistive robotics.
The researchers have also made important contributions to the field by introducing a new benchmark dataset and evaluation framework, which will enable further research and development in this area. While there are still some limitations and challenges to be addressed, the O3D-SIM approach represents an important step forward in the quest for more intelligent and capable robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Object Instance Retrieval in Assistive Robotics: Leveraging Fine-Tuned SimSiam with Multi-View Images Based on 3D Semantic Map
Taichi Sakaguchi, Akira Taniguchi, Yoshinobu Hagiwara, Lotfi El Hafi, Shoichi Hasegawa, Tadahiro Taniguchi
0
0
Robots that assist in daily life are required to locate specific instances of objects that match the user's desired object in the environment. This task is known as Instance-Specific Image Goal Navigation (InstanceImageNav), which requires a model capable of distinguishing between different instances within the same class. One significant challenge in robotics is that when a robot observes the same object from various 3D viewpoints, its appearance may differ greatly, making it difficult to recognize and locate the object accurately. In this study, we introduce a method, SimView, that leverages multi-view images based on a 3D semantic map of the environment and self-supervised learning by SimSiam to train an instance identification model on-site. The effectiveness of our approach is validated using a photorealistic simulator, Habitat Matterport 3D, created by scanning real home environments. Our results demonstrate a 1.7-fold improvement in task accuracy compared to CLIP, which is pre-trained multimodal contrastive learning for object search. This improvement highlights the benefits of our proposed fine-tuning method in enhancing the performance of assistive robots in InstanceImageNav tasks. The project website is https://emergentsystemlabstudent.github.io/MultiViewRetrieve/.
4/16/2024
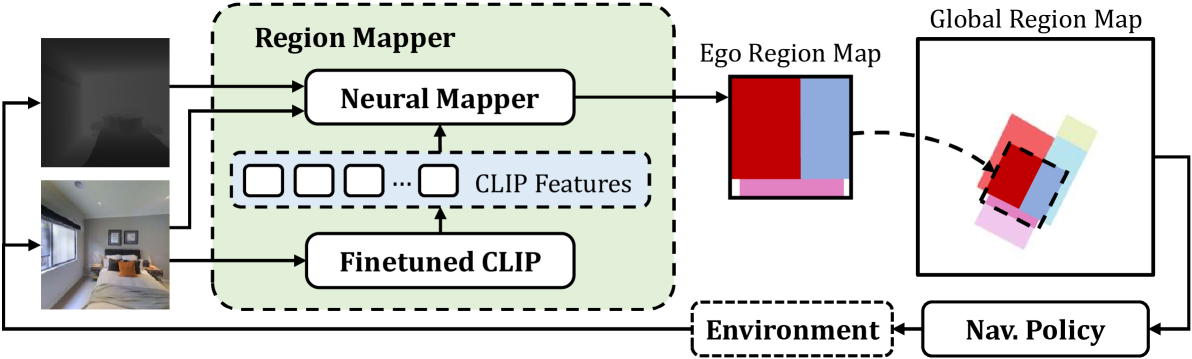
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Roberto Bigazzi, Lorenzo Baraldi, Shreyas Kousik, Rita Cucchiara, Marco Pavone
0
0
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
4/16/2024

QueSTMaps: Queryable Semantic Topological Maps for 3D Scene Understanding
Yash Mehan, Kumaraditya Gupta, Rohit Jayanti, Anirudh Govil, Sourav Garg, Madhava Krishna
0
0
Understanding the structural organisation of 3D indoor scenes in terms of rooms is often accomplished via floorplan extraction. Robotic tasks such as planning and navigation require a semantic understanding of the scene as well. This is typically achieved via object-level semantic segmentation. However, such methods struggle to segment out topological regions like kitchen in the scene. In this work, we introduce a two-step pipeline. First, we extract a topological map, i.e., floorplan of the indoor scene using a novel multi-channel occupancy representation. Then, we generate CLIP-aligned features and semantic labels for every room instance based on the objects it contains using a self-attention transformer. Our language-topology alignment supports natural language querying, e.g., a place to cook locates the kitchen. We outperform the current state-of-the-art on room segmentation by ~20% and room classification by ~12%. Our detailed qualitative analysis and ablation studies provide insights into the problem of joint structural and semantic 3D scene understanding.
4/10/2024

Open-vocabulary Mobile Manipulation in Unseen Dynamic Environments with 3D Semantic Maps
Dicong Qiu, Wenzong Ma, Zhenfu Pan, Hui Xiong, Junwei Liang
0
0
Open-Vocabulary Mobile Manipulation (OVMM) is a crucial capability for autonomous robots, especially when faced with the challenges posed by unknown and dynamic environments. This task requires robots to explore and build a semantic understanding of their surroundings, generate feasible plans to achieve manipulation goals, adapt to environmental changes, and comprehend natural language instructions from humans. To address these challenges, we propose a novel framework that leverages the zero-shot detection and grounded recognition capabilities of pretraining visual-language models (VLMs) combined with dense 3D entity reconstruction to build 3D semantic maps. Additionally, we utilize large language models (LLMs) for spatial region abstraction and online planning, incorporating human instructions and spatial semantic context. We have built a 10-DoF mobile manipulation robotic platform JSR-1 and demonstrated in real-world robot experiments that our proposed framework can effectively capture spatial semantics and process natural language user instructions for zero-shot OVMM tasks under dynamic environment settings, with an overall navigation and task success rate of 80.95% and 73.33% over 105 episodes, and better SFT and SPL by 157.18% and 19.53% respectively compared to the baseline. Furthermore, the framework is capable of replanning towards the next most probable candidate location based on the spatial semantic context derived from the 3D semantic map when initial plans fail, keeping an average success rate of 76.67%.
6/27/2024