OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving

0

Sign in to get full access
Overview
- The paper presents OccLLaMA, a generative world model for autonomous driving that integrates occupancy, language, and action.
- It leverages large language models (LLMs) to generate realistic 3D occupancy maps, text descriptions, and driving actions.
- The model is trained on the comprehensive COVLA dataset, which includes driving scenes, language, and actions.
- OccLLaMA aims to enable more intelligent and safe autonomous driving by building a rich understanding of the driving environment.
Plain English Explanation
OccLLaMA is a new AI system designed to help self-driving cars better understand and navigate their surroundings. It uses large language models to create a detailed 3D map of the driving environment, describe what it sees in natural language, and generate appropriate driving actions.
The key innovation is that OccLLaMA integrates three crucial elements for autonomous driving: occupancy (the 3D layout of the environment), language (textual descriptions of the scene), and action (the driving behaviors required to safely navigate). By bringing these together, the model can build a richer, more holistic understanding of the driving world.
This is important because self-driving cars today still struggle with complex, real-world driving scenarios. They often rely on narrow, specialized algorithms that can't handle the full complexity of driving. OccLLaMA aims to address this by creating an AI "world model" that can reason about the driving environment in a more human-like way, using language and high-level concepts.
The researchers trained OccLLaMA on the COVLA dataset, which contains a wealth of driving data - including 3D scenes, natural language descriptions, and recorded driving actions. By learning from this diverse data, the model can generate plausible occupancy maps, text descriptions, and driving behaviors, all in an integrated fashion.
Technical Explanation
OccLLaMA is a novel generative world model that jointly models the 3D occupancy of a driving scene, the language description of that scene, and the driving actions required to navigate it. The key technical contributions are:
-
Occupancy Modeling: OccLLaMA uses a voxel-based representation to capture the 3D layout and structure of the driving environment. It can generate realistic occupancy maps that capture the positions of roads, buildings, obstacles, etc.
-
Language Generation: The model leverages large language models (e.g. GPT) to generate natural language descriptions of the driving scene. This allows the system to communicate its understanding of the environment in human-readable form.
-
Action Prediction: In addition to the occupancy and language outputs, OccLLaMA also predicts the sequence of driving actions (e.g. accelerate, brake, steer) required to navigate the environment safely.
The model is trained end-to-end on the COVLA dataset, which provides the necessary supervision across the occupancy, language, and action modalities. This allows OccLLaMA to learn the complex relationships between these different aspects of the driving world.
Critical Analysis
The authors acknowledge several limitations and areas for future work with OccLLaMA:
-
The model is trained on limited data from the COVLA dataset, which may not capture the full diversity of real-world driving scenarios. Expanding the training data could improve the model's generalization.
-
The occupancy modeling is currently based on a voxel representation, which can be memory-intensive. Exploring more efficient 3D representations could make the system more practical for real-world deployment.
-
While the language generation capabilities are impressive, the model still struggles with producing coherent, context-aware descriptions for complex driving scenes. Further advances in multimodal language understanding are needed.
-
The action prediction component is relatively simplistic, only outputting low-level control commands. Incorporating higher-level planning and decision-making would be necessary for truly autonomous driving.
Additionally, some open questions remain about the interpretability and safety of such a large, generative world model. Ensuring the model's outputs are reliable and that it behaves predictably in safety-critical driving situations will be crucial for real-world deployment.
Conclusion
OccLLaMA represents an important step towards building more intelligent and capable autonomous driving systems. By jointly modeling the 3D occupancy, language, and actions required for navigation, the model can develop a richer, more holistic understanding of the driving environment.
This could enable self-driving cars to better perceive, reason about, and interact with the world around them. While the current implementation has limitations, the core idea of an integrated "world model" that can leverage large language models is a promising direction for the field of autonomous driving.
Continued research and development in this area could lead to significant advancements in the safety, robustness, and user experience of self-driving vehicles - ultimately bringing us closer to a future where autonomous transportation is a safe and reliable reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
Julong Wei, Shanshuai Yuan, Pengfei Li, Qingda Hu, Zhongxue Gan, Wenchao Ding
The rise of multi-modal large language models(MLLMs) has spurred their applications in autonomous driving. Recent MLLM-based methods perform action by learning a direct mapping from perception to action, neglecting the dynamics of the world and the relations between action and world dynamics. In contrast, human beings possess world model that enables them to simulate the future states based on 3D internal visual representation and plan actions accordingly. To this end, we propose OccLLaMA, an occupancy-language-action generative world model, which uses semantic occupancy as a general visual representation and unifies vision-language-action(VLA) modalities through an autoregressive model. Specifically, we introduce a novel VQVAE-like scene tokenizer to efficiently discretize and reconstruct semantic occupancy scenes, considering its sparsity and classes imbalance. Then, we build a unified multi-modal vocabulary for vision, language and action. Furthermore, we enhance LLM, specifically LLaMA, to perform the next token/scene prediction on the unified vocabulary to complete multiple tasks in autonomous driving. Extensive experiments demonstrate that OccLLaMA achieves competitive performance across multiple tasks, including 4D occupancy forecasting, motion planning, and visual question answering, showcasing its potential as a foundation model in autonomous driving.
Read more9/6/2024

0
CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
Hidehisa Arai, Keita Miwa, Kento Sasaki, Yu Yamaguchi, Kohei Watanabe, Shunsuke Aoki, Issei Yamamoto
Autonomous driving, particularly navigating complex and unanticipated scenarios, demands sophisticated reasoning and planning capabilities. While Multi-modal Large Language Models (MLLMs) offer a promising avenue for this, their use has been largely confined to understanding complex environmental contexts or generating high-level driving commands, with few studies extending their application to end-to-end path planning. A major research bottleneck is the lack of large-scale annotated datasets encompassing vision, language, and action. To address this issue, we propose CoVLA (Comprehensive Vision-Language-Action) Dataset, an extensive dataset comprising real-world driving videos spanning more than 80 hours. This dataset leverages a novel, scalable approach based on automated data processing and a caption generation pipeline to generate accurate driving trajectories paired with detailed natural language descriptions of driving environments and maneuvers. This approach utilizes raw in-vehicle sensor data, allowing it to surpass existing datasets in scale and annotation richness. Using CoVLA, we investigate the driving capabilities of MLLMs that can handle vision, language, and action in a variety of driving scenarios. Our results illustrate the strong proficiency of our model in generating coherent language and action outputs, emphasizing the potential of Vision-Language-Action (VLA) models in the field of autonomous driving. This dataset establishes a framework for robust, interpretable, and data-driven autonomous driving systems by providing a comprehensive platform for training and evaluating VLA models, contributing to safer and more reliable self-driving vehicles. The dataset is released for academic purpose.
Read more8/21/2024
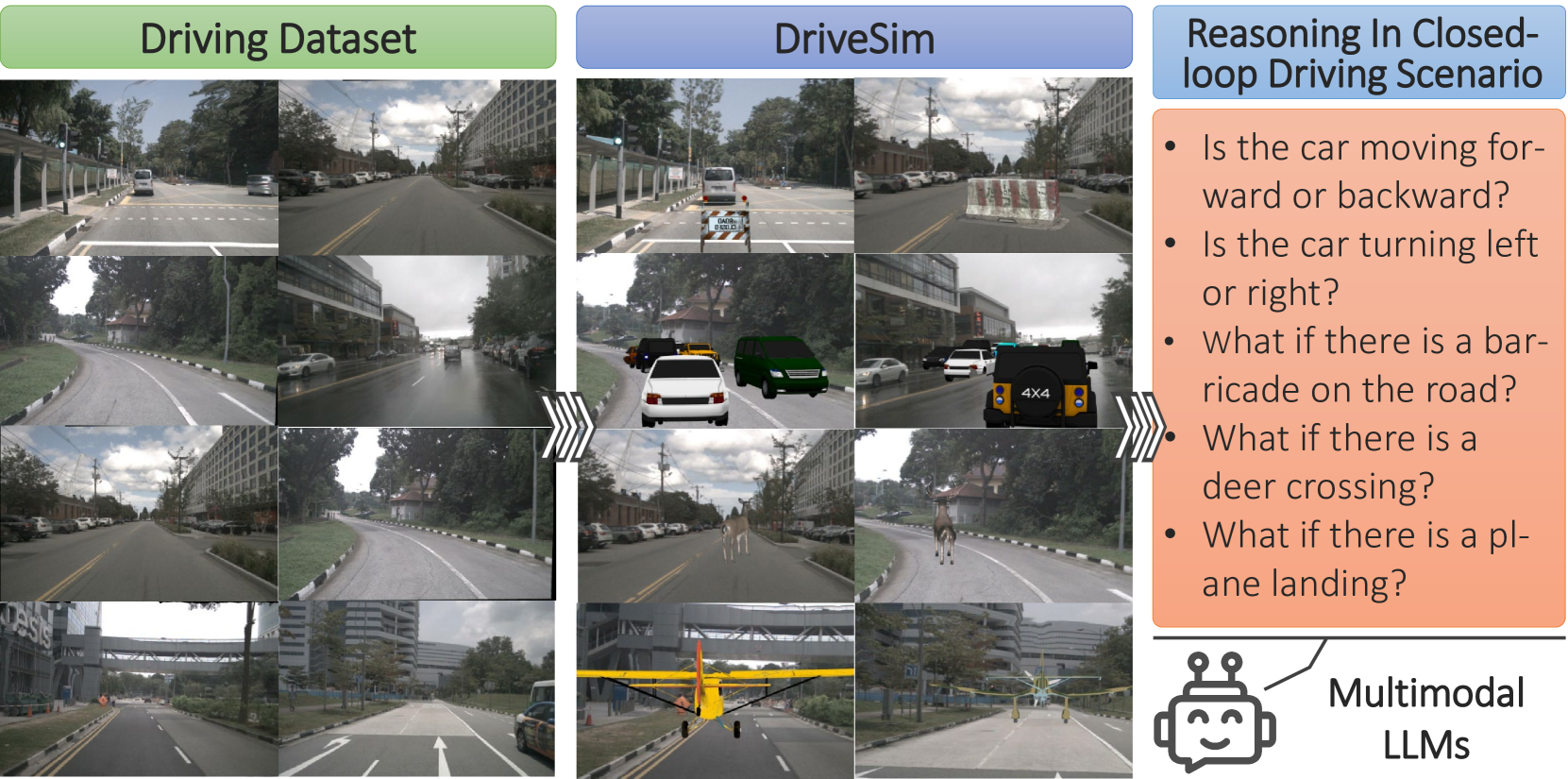
0
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
Read more5/10/2024

0
Leveraging LLMs for Enhanced Open-Vocabulary 3D Scene Understanding in Autonomous Driving
Amirhosein Chahe, Lifeng Zhou
This paper introduces a novel method for open-vocabulary 3D scene understanding in autonomous driving by combining Language Embedded 3D Gaussians with Large Language Models (LLMs) for enhanced inference. We propose utilizing LLMs to generate contextually relevant canonical phrases for segmentation and scene interpretation. Our method leverages the contextual and semantic capabilities of LLMs to produce a set of canonical phrases, which are then compared with the language features embedded in the 3D Gaussians. This LLM-guided approach significantly improves zero-shot scene understanding and detection of objects of interest, even in the most challenging or unfamiliar environments. Experimental results on the WayveScenes101 dataset demonstrate that our approach surpasses state-of-the-art methods in terms of accuracy and flexibility for open-vocabulary object detection and segmentation. This work represents a significant advancement towards more intelligent, context-aware autonomous driving systems, effectively bridging 3D scene representation with high-level semantic understanding.
Read more8/9/2024