ODIM: Outlier Detection via Likelihood of Under-Fitted Generative Models

0
🔎
Sign in to get full access
Overview
- The paper addresses the unsupervised outlier detection (UOD) problem, which involves identifying inliers (normal data points) from a dataset that contains both inliers and outliers (anomalies) without any labeled information.
- The authors claim that the likelihood from a carefully under-fitted deep generative model (DGM) can be a powerful signal for identifying inliers in UOD tasks.
- They introduce the "inlier-memorization (IM) effect," which observes that DGMs initially memorize inliers before outliers during training.
- The authors develop a new method called "outlier detection via the IM effect (ODIM)" that leverages this effect to efficiently filter out outliers, regardless of the data type.
Plain English Explanation
The paper discusses a problem called unsupervised outlier detection (UOD), where the goal is to identify normal data points (inliers) from a dataset that contains both normal data and abnormal data (outliers), without any labeled information about which is which. The authors claim that the likelihood, or probability, assigned by a carefully trained deep generative model (a type of AI model that can generate new data) can be a powerful way to distinguish inliers from outliers.
The key insight the authors have is the "inlier-memorization (IM) effect" - they find that when training these deep generative models on a dataset with both inliers and outliers, the models initially learn to "memorize" the inlier data before the outlier data. Based on this observation, the authors develop a new method called "outlier detection via the IM effect (ODIM)" that can efficiently filter out outliers from the dataset, regardless of whether the data is in the form of tables, images, or text.
The main advantage of the ODIM method is that it is computationally efficient, requiring only a few training updates to achieve good outlier detection performance, which is much faster than other deep learning-based outlier detection algorithms. The authors validate the effectiveness of their approach through extensive experiments on close to 60 different datasets.
Technical Explanation
The paper explores the unsupervised outlier detection (UOD) problem, where the goal is to identify inliers (normal data points) from a dataset that contains both inliers and outliers (anomalies), without any labeled information about which data points are which.
The authors observe that using fully-trained likelihood-based deep generative models (DGMs) often results in poor performance in distinguishing inliers from outliers. However, they claim that the likelihood itself can serve as powerful evidence for identifying inliers in UOD tasks, provided that the DGMs are carefully under-fitted.
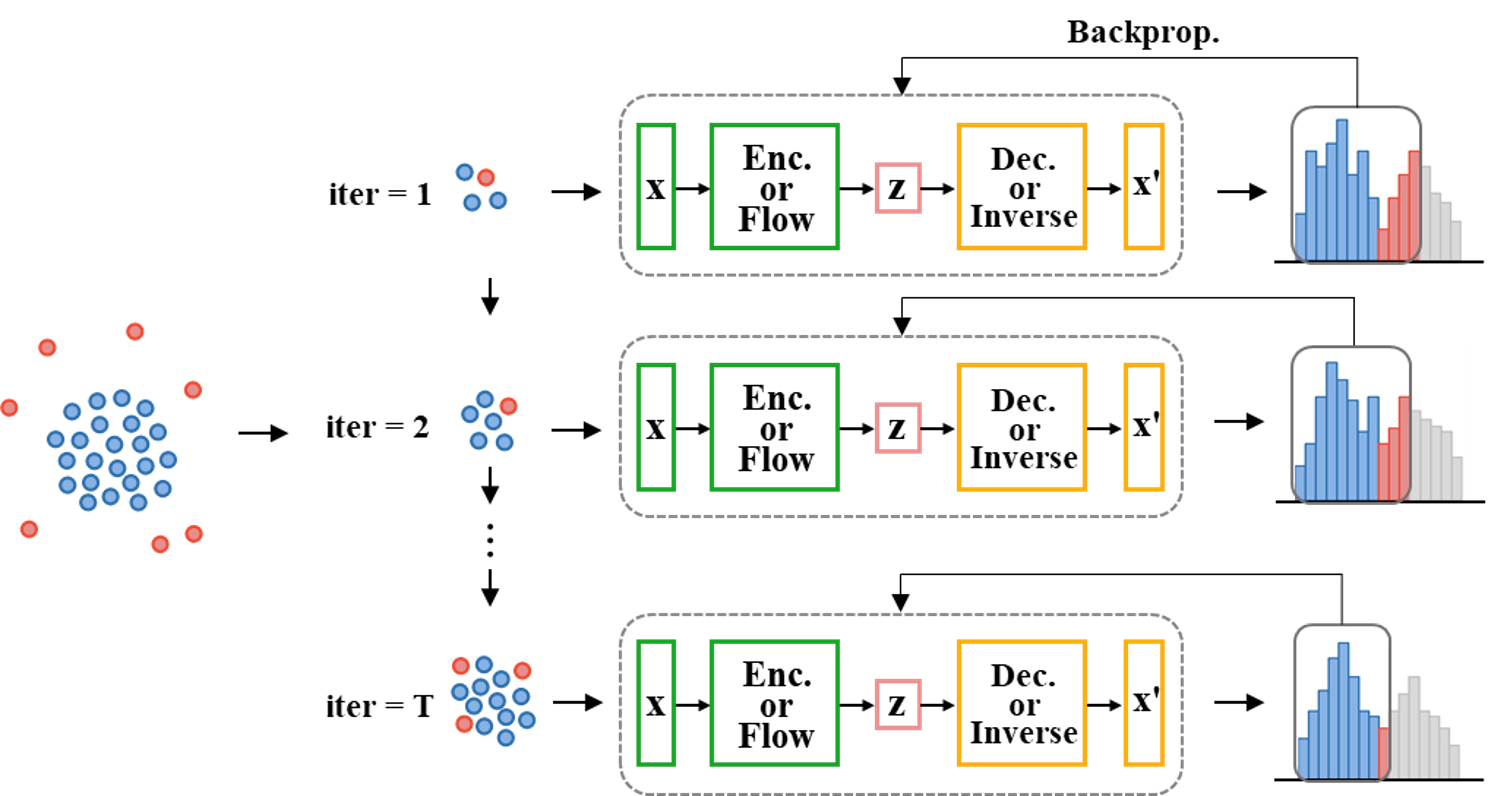
The key insight is the "inlier-memorization (IM) effect" - the authors find that when training a DGM on a dataset with both inliers and outliers, the model initially memorizes the inliers before the outliers. Based on this, the authors develop a new method called "outlier detection via the IM effect (ODIM)" that leverages this effect to efficiently filter out outliers.
The ODIM method requires only a few training updates, making it computationally efficient - at least tens of times faster than other deep-learning-based outlier detection algorithms. The authors demonstrate the ODIM's effectiveness at filtering out outliers across a wide range of data types, including tabular, image, and text data.
To validate their claims, the authors provide extensive empirical analyses on close to 60 datasets. The results show that the ODIM outperforms other state-of-the-art outlier detection methods in terms of both effectiveness and efficiency.
Critical Analysis
The paper presents a novel and promising approach to the unsupervised outlier detection problem. The key insight about the "inlier-memorization effect" and the resulting ODIM method appear to be effective and computationally efficient compared to other deep learning-based outlier detection techniques.
However, the paper does not delve deeply into the limitations or potential issues with the proposed approach. For example, it would be helpful to understand how the ODIM method performs on datasets with different levels of outlier contamination or with outliers that are more subtle and difficult to distinguish from inliers.
Additionally, the authors could have provided more discussion on the theoretical underpinnings of the IM effect and how it relates to the properties of deep generative models. A deeper analysis of this phenomenon could lead to further insights and potential improvements to the ODIM method.
Overall, the paper presents a valuable contribution to the field of unsupervised outlier detection, but there are opportunities for further research to address the method's limitations and expand our understanding of the underlying principles.
Conclusion
This paper introduces a novel approach to the unsupervised outlier detection (UOD) problem, which is an important task in many real-world applications. The key innovation is the discovery of the "inlier-memorization (IM) effect" - the observation that deep generative models initially memorize inliers before outliers during training.
By leveraging this effect, the authors develop a new method called "outlier detection via the IM effect (ODIM)" that can efficiently filter out outliers from datasets, regardless of the data type. The ODIM method is shown to outperform other state-of-the-art deep learning-based outlier detection approaches in terms of both effectiveness and computational efficiency.
The implications of this research are significant, as efficient and robust outlier detection can have a wide range of applications, from anomaly detection in sensor networks to fraud identification in financial transactions. The insights gained from this work could also lead to further advancements in unsupervised out-of-distribution detection and outlier-aware metric learning, paving the way for more reliable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
ODIM: Outlier Detection via Likelihood of Under-Fitted Generative Models
Dongha Kim, Jaesung Hwang, Jongjin Lee, Kunwoong Kim, Yongdai Kim
The unsupervised outlier detection (UOD) problem refers to a task to identify inliers given training data which contain outliers as well as inliers, without any labeled information about inliers and outliers. It has been widely recognized that using fully-trained likelihood-based deep generative models (DGMs) often results in poor performance in distinguishing inliers from outliers. In this study, we claim that the likelihood itself could serve as powerful evidence for identifying inliers in UOD tasks, provided that DGMs are carefully under-fitted. Our approach begins with a novel observation called the inlier-memorization (IM) effect-when training a deep generative model with data including outliers, the model initially memorizes inliers before outliers. Based on this finding, we develop a new method called the outlier detection via the IM effect (ODIM). Remarkably, the ODIM requires only a few updates, making it computationally efficient-at least tens of times faster than other deep-learning-based algorithms. Also, the ODIM filters out outliers excellently, regardless of the data type, including tabular, image, and text data. To validate the superiority and efficiency of our method, we provide extensive empirical analyses on close to 60 datasets.
Read more7/17/2024
0
ALTBI: Constructing Improved Outlier Detection Models via Optimization of Inlier-Memorization Effect
Seoyoung Cho, Jaesung Hwang, Kwan-Young Bak, Dongha Kim
Outlier detection (OD) is the task of identifying unusual observations (or outliers) from a given or upcoming data by learning unique patterns of normal observations (or inliers). Recently, a study introduced a powerful unsupervised OD (UOD) solver based on a new observation of deep generative models, called inlier-memorization (IM) effect, which suggests that generative models memorize inliers before outliers in early learning stages. In this study, we aim to develop a theoretically principled method to address UOD tasks by maximally utilizing the IM effect. We begin by observing that the IM effect is observed more clearly when the given training data contain fewer outliers. This finding indicates a potential for enhancing the IM effect in UOD regimes if we can effectively exclude outliers from mini-batches when designing the loss function. To this end, we introduce two main techniques: 1) increasing the mini-batch size as the model training proceeds and 2) using an adaptive threshold to calculate the truncated loss function. We theoretically show that these two techniques effectively filter out outliers from the truncated loss function, allowing us to utilize the IM effect to the fullest. Coupled with an additional ensemble strategy, we propose our method and term it Adaptive Loss Truncation with Batch Increment (ALTBI). We provide extensive experimental results to demonstrate that ALTBI achieves state-of-the-art performance in identifying outliers compared to other recent methods, even with significantly lower computation costs. Additionally, we show that our method yields robust performances when combined with privacy-preserving algorithms.
Read more8/20/2024

0
Resultant: Incremental Effectiveness on Likelihood for Unsupervised Out-of-Distribution Detection
Yewen Li, Chaojie Wang, Xiaobo Xia, Xu He, Ruyi An, Dong Li, Tongliang Liu, Bo An, Xinrun Wang
Unsupervised out-of-distribution (U-OOD) detection is to identify OOD data samples with a detector trained solely on unlabeled in-distribution (ID) data. The likelihood function estimated by a deep generative model (DGM) could be a natural detector, but its performance is limited in some popular hard benchmarks, such as FashionMNIST (ID) vs. MNIST (OOD). Recent studies have developed various detectors based on DGMs to move beyond likelihood. However, despite their success on hard benchmarks, most of them struggle to consistently surpass or match the performance of likelihood on some non-hard cases, such as SVHN (ID) vs. CIFAR10 (OOD) where likelihood could be a nearly perfect detector. Therefore, we appeal for more attention to incremental effectiveness on likelihood, i.e., whether a method could always surpass or at least match the performance of likelihood in U-OOD detection. We first investigate the likelihood of variational DGMs and find its detection performance could be improved in two directions: i) alleviating latent distribution mismatch, and ii) calibrating the dataset entropy-mutual integration. Then, we apply two techniques for each direction, specifically post-hoc prior and dataset entropy-mutual calibration. The final method, named Resultant, combines these two directions for better incremental effectiveness compared to either technique alone. Experimental results demonstrate that the Resultant could be a new state-of-the-art U-OOD detector while maintaining incremental effectiveness on likelihood in a wide range of tasks.
Read more9/9/2024

0
A Geometric Explanation of the Likelihood OOD Detection Paradox
Hamidreza Kamkari, Brendan Leigh Ross, Jesse C. Cresswell, Anthony L. Caterini, Rahul G. Krishnan, Gabriel Loaiza-Ganem
Likelihood-based deep generative models (DGMs) commonly exhibit a puzzling behaviour: when trained on a relatively complex dataset, they assign higher likelihood values to out-of-distribution (OOD) data from simpler sources. Adding to the mystery, OOD samples are never generated by these DGMs despite having higher likelihoods. This two-pronged paradox has yet to be conclusively explained, making likelihood-based OOD detection unreliable. Our primary observation is that high-likelihood regions will not be generated if they contain minimal probability mass. We demonstrate how this seeming contradiction of large densities yet low probability mass can occur around data confined to low-dimensional manifolds. We also show that this scenario can be identified through local intrinsic dimension (LID) estimation, and propose a method for OOD detection which pairs the likelihoods and LID estimates obtained from a pre-trained DGM. Our method can be applied to normalizing flows and score-based diffusion models, and obtains results which match or surpass state-of-the-art OOD detection benchmarks using the same DGM backbones. Our code is available at https://github.com/layer6ai-labs/dgm_ood_detection.
Read more6/13/2024