Off-OAB: Off-Policy Policy Gradient Method with Optimal Action-Dependent Baseline

0
📊
Sign in to get full access
Overview
- This paper proposes an off-policy policy gradient method with an optimal action-dependent baseline (Off-OAB) to address the high variance issue in off-policy policy gradient (OPPG) estimators.
- Off-policy policy gradient methods can leverage off-policy data, which is important for improving sample efficiency in reinforcement learning.
- However, OPPG estimators suffer from high variance, leading to poor sample efficiency during training.
- The proposed Off-OAB method aims to decrease the variance of the OPPG estimator while maintaining its unbiasedness.
Plain English Explanation
In reinforcement learning, policy-based methods have been very successful at solving complex problems. Among these methods, off-policy policy gradient methods are particularly important because they can use data collected from different policies (off-policy data), which can improve the efficiency of the learning process.
However, the key challenge with off-policy policy gradient methods is that the estimator they use (the OPPG estimator) has high variance. This high variance leads to poor sample efficiency during training, meaning the agent needs to experience a lot of samples before it can learn an effective policy.
To address this issue, the researchers propose a new method called Off-OAB. The key idea is to use an "optimal action-dependent baseline" that can reduce the variance of the OPPG estimator while still keeping it unbiased (meaning the estimator's average value is still correct). To make this practical, they also design an approximated version of this optimal baseline.
By using this variance-reduced OPPG estimator, the Off-OAB method aims to improve the sample efficiency of the policy optimization process, allowing the agent to learn effective policies more quickly.
Technical Explanation
The paper proposes an off-policy policy gradient method called Off-OAB that uses an optimal action-dependent baseline to reduce the variance of the off-policy policy gradient (OPPG) estimator.
The OPPG estimator is used in off-policy policy gradient methods, such as DOLLARÕ policy gradient and REBEL, to update the policy based on data collected under a different policy. However, the high variance of the OPPG estimator can lead to poor sample efficiency during training.
To address this, the Off-OAB method maintains the unbiasedness of the OPPG estimator while theoretically minimizing its variance. Specifically, the method uses an optimal action-dependent baseline that is derived to minimize the variance of the OPPG estimator.
To enhance the practical computational efficiency, the researchers also design an approximated version of this optimal baseline. By using this approximated baseline, the Off-OAB method aims to decrease the variance of the OPPG estimator during policy optimization.
The proposed Off-OAB method is evaluated on six representative tasks from OpenAI Gym and MuJoCo, where it outperforms state-of-the-art methods on the majority of these tasks.
Critical Analysis
The paper provides a novel approach to addressing the high variance issue in off-policy policy gradient methods, which is an important problem in reinforcement learning. The use of an optimal action-dependent baseline to reduce the variance of the OPPG estimator is a clever idea and the theoretical analysis is sound.
However, the paper does not discuss the limitations of the proposed method or potential areas for further research. For example, the approximation used to enhance computational efficiency may introduce additional bias or errors, and the performance of the method on a wider range of tasks or in more complex environments is not explored.
Additionally, while the experimental results are promising, the paper does not provide a deep analysis of the factors contributing to the improved performance or compare the method to a wider range of baselines, such as off-policy primal-dual safe reinforcement learning or other variance reduction techniques.
Overall, the paper presents a valuable contribution to the field of reinforcement learning, but further research is needed to fully understand the strengths, weaknesses, and broader applicability of the Off-OAB method.
Conclusion
This paper introduces an off-policy policy gradient method called Off-OAB that addresses the high variance issue in off-policy policy gradient (OPPG) estimators. By using an optimal action-dependent baseline, the method can reduce the variance of the OPPG estimator while maintaining its unbiasedness, which is crucial for improving the sample efficiency of the policy optimization process.
The experimental results demonstrate the effectiveness of the Off-OAB method, as it outperforms state-of-the-art techniques on a variety of tasks. This work represents an important step forward in developing more efficient off-policy reinforcement learning algorithms, which have the potential to significantly advance the field and enable the application of RL to an even wider range of real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Off-OAB: Off-Policy Policy Gradient Method with Optimal Action-Dependent Baseline
Wenjia Meng, Qian Zheng, Long Yang, Yilong Yin, Gang Pan
Policy-based methods have achieved remarkable success in solving challenging reinforcement learning problems. Among these methods, off-policy policy gradient methods are particularly important due to that they can benefit from off-policy data. However, these methods suffer from the high variance of the off-policy policy gradient (OPPG) estimator, which results in poor sample efficiency during training. In this paper, we propose an off-policy policy gradient method with the optimal action-dependent baseline (Off-OAB) to mitigate this variance issue. Specifically, this baseline maintains the OPPG estimator's unbiasedness while theoretically minimizing its variance. To enhance practical computational efficiency, we design an approximated version of this optimal baseline. Utilizing this approximation, our method (Off-OAB) aims to decrease the OPPG estimator's variance during policy optimization. We evaluate the proposed Off-OAB method on six representative tasks from OpenAI Gym and MuJoCo, where it demonstrably surpasses state-of-the-art methods on the majority of these tasks.
Read more5/7/2024

0
Optimal Baseline Corrections for Off-Policy Contextual Bandits
Shashank Gupta, Olivier Jeunen, Harrie Oosterhuis, Maarten de Rijke
The off-policy learning paradigm allows for recommender systems and general ranking applications to be framed as decision-making problems, where we aim to learn decision policies that optimize an unbiased offline estimate of an online reward metric. With unbiasedness comes potentially high variance, and prevalent methods exist to reduce estimation variance. These methods typically make use of control variates, either additive (i.e., baseline corrections or doubly robust methods) or multiplicative (i.e., self-normalisation). Our work unifies these approaches by proposing a single framework built on their equivalence in learning scenarios. The foundation of our framework is the derivation of an equivalent baseline correction for all of the existing control variates. Consequently, our framework enables us to characterize the variance-optimal unbiased estimator and provide a closed-form solution for it. This optimal estimator brings significantly improved performance in both evaluation and learning, and minimizes data requirements. Empirical observations corroborate our theoretical findings.
Read more8/15/2024
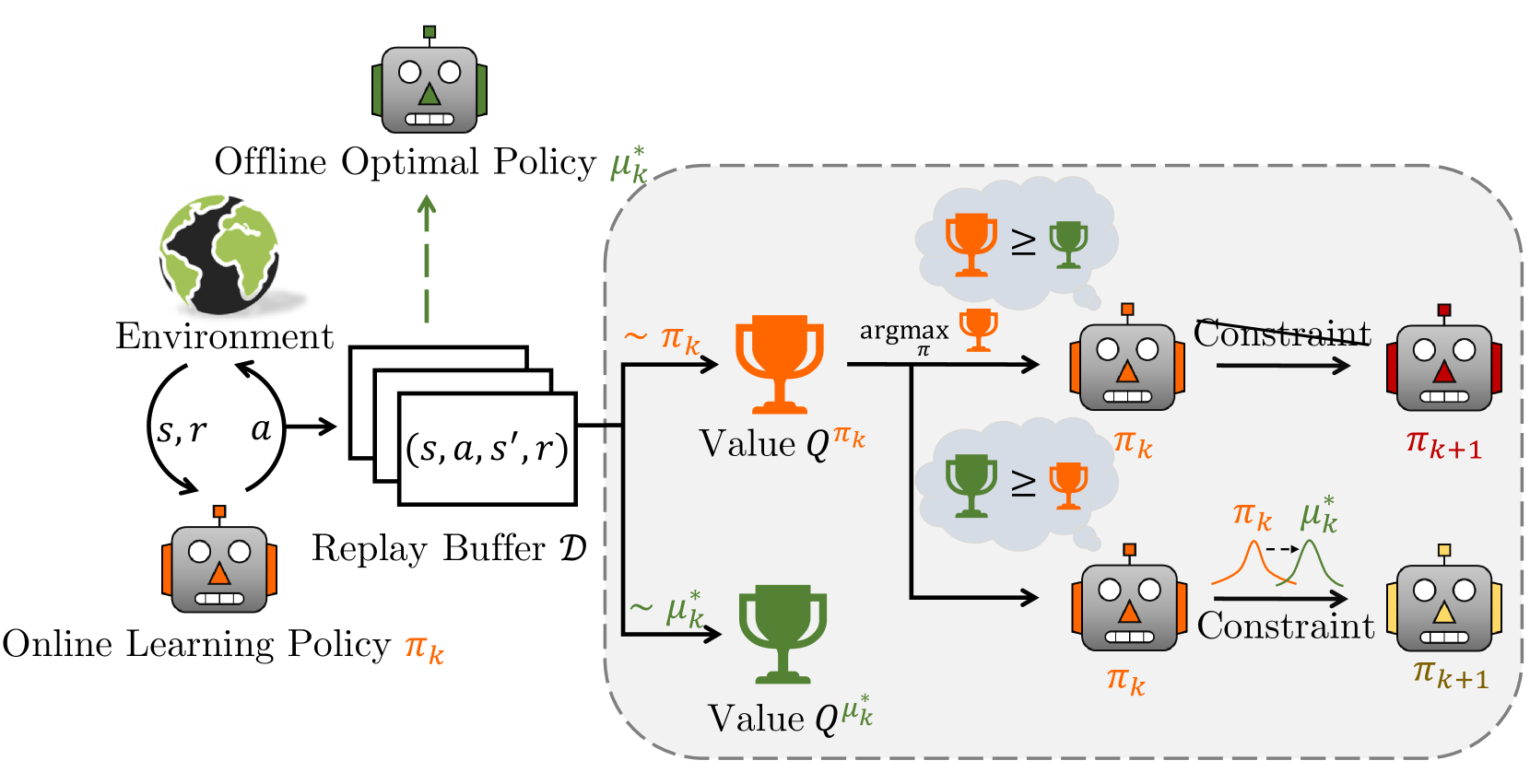
0
Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
Yu Luo, Tianying Ji, Fuchun Sun, Jianwei Zhang, Huazhe Xu, Xianyuan Zhan
Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.
Read more5/30/2024

0
Offline Policy Evaluation for Reinforcement Learning with Adaptively Collected Data
Sunil Madhow, Dan Qiao, Ming Yin, Yu-Xiang Wang
Developing theoretical guarantees on the sample complexity of offline RL methods is an important step towards making data-hungry RL algorithms practically viable. Currently, most results hinge on unrealistic assumptions about the data distribution -- namely that it comprises a set of i.i.d. trajectories collected by a single logging policy. We consider a more general setting where the dataset may have been gathered adaptively. We develop theory for the TMIS Offline Policy Evaluation (OPE) estimator in this generalized setting for tabular MDPs, deriving high-probability, instance-dependent bounds on its estimation error. We also recover minimax-optimal offline learning in the adaptive setting. Finally, we conduct simulations to empirically analyze the behavior of these estimators under adaptive and non-adaptive regimes.
Read more5/2/2024