Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
2405.18520
0
0
Abstract
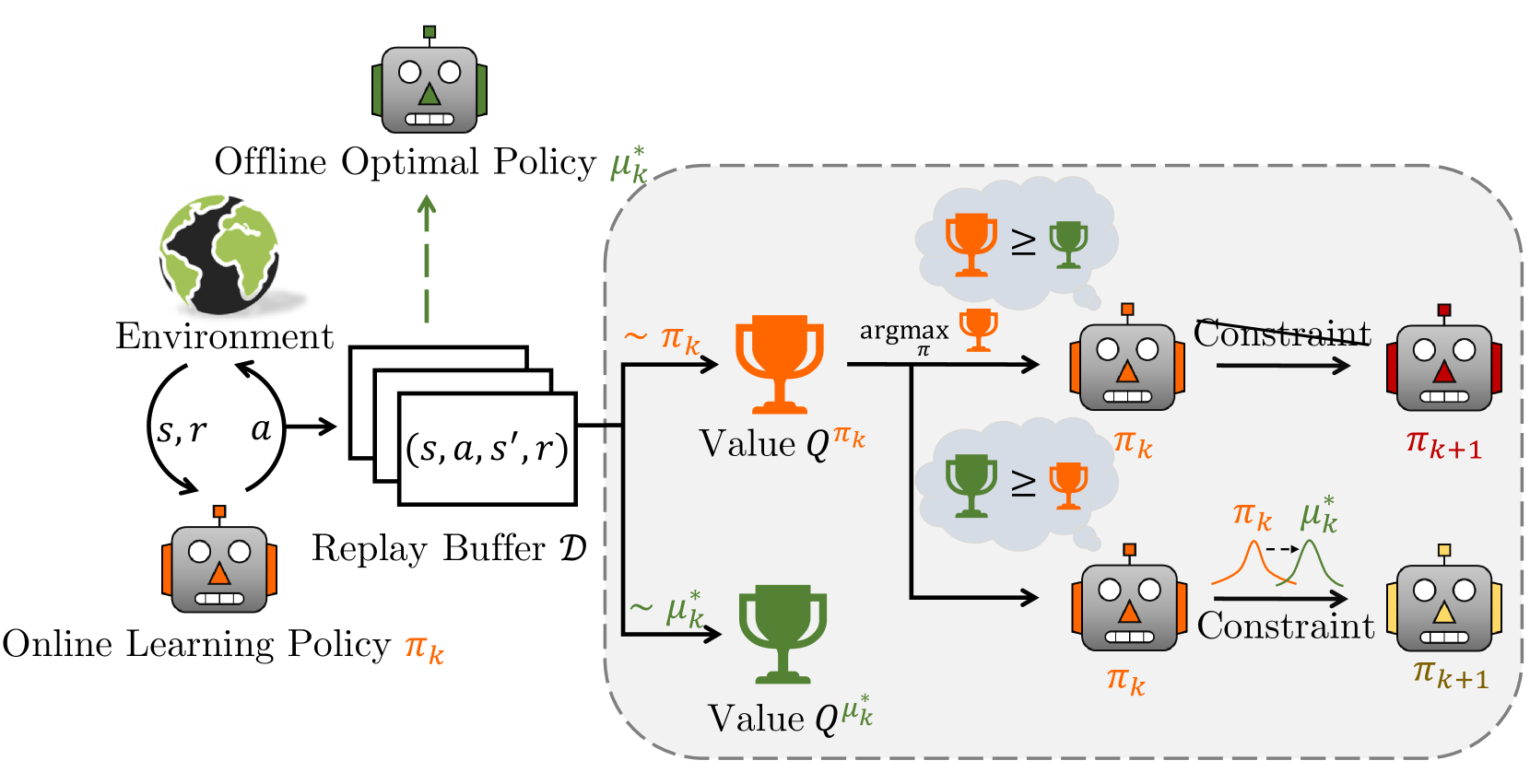
Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.
Create account to get full access
Overview
- This paper proposes a new offline reinforcement learning algorithm called "Offline-Boosted Actor-Critic" (OBAC) that adaptively blends optimal historical behaviors to improve performance in deep off-policy RL.
- OBAC aims to address the challenges of offline RL, where the agent must learn from a fixed dataset without additional interaction with the environment.
- The key idea is to leverage past optimal behaviors stored in the dataset to boost the learning of the current policy, adaptively combining them based on their relevance to the current state.
Plain English Explanation
Offline reinforcement learning is a type of machine learning where an AI agent has to learn how to perform a task by analyzing a fixed dataset, without being able to interact with the real-world environment. This is different from the more common "online" RL, where the agent can directly interact with the environment and learn from that experience.
The key challenge in offline RL is that the agent is limited to the data it has access to, which may not cover all the possible situations it might encounter. Offline-Boosted Actor-Critic (OBAC) tries to address this by taking a clever approach: it looks at the historical "optimal" behaviors stored in the dataset and adaptively combines them to help the agent learn a better policy.
The idea is that even though the agent can't interact with the real environment, it can still learn from the successes and failures of past optimal behaviors. OBAC uses these past optimal behaviors to "boost" the learning of the current policy, blending them together based on how relevant they are to the current situation the agent is facing.
This allows the agent to leverage the valuable information contained in the dataset, without being fully constrained by it. It's like the agent is standing on the shoulders of past optimal agents, using their experience to see further and learn more efficiently.
Technical Explanation
The Offline-Boosted Actor-Critic (OBAC) algorithm proposed in this paper aims to improve the performance of deep offline reinforcement learning by adaptively blending optimal historical behaviors from the dataset.
The key components of OBAC are:
-
Offline Policy Evaluation: OBAC first performs an offline policy evaluation step to estimate the value functions of past optimal behaviors stored in the dataset. This allows the algorithm to assess the relevance and value of these historical behaviors.
-
Adaptive Blending: OBAC then adaptively blends the estimated value functions of the past optimal behaviors with the value function of the current policy. The blending weights are determined based on the relevance of each historical behavior to the current state.
-
Policy Optimization: Finally, OBAC performs policy optimization using the adaptively blended value function, which encourages the current policy to mimic the most relevant optimal historical behaviors.
The authors evaluate OBAC on several continuous control tasks and show that it outperforms state-of-the-art offline RL algorithms, particularly in environments with diverse datasets. The adaptive blending of historical optimal behaviors allows OBAC to leverage the valuable information in the dataset more effectively than approaches that solely rely on the current policy.
Critical Analysis
The Offline-Boosted Actor-Critic (OBAC) algorithm presents a promising approach to addressing the challenges of offline reinforcement learning. By adaptively blending optimal historical behaviors, OBAC can effectively leverage the information contained in the dataset, even when it does not cover the full range of possible situations.
However, the paper does not discuss some potential limitations of the approach. For example, the performance of OBAC may depend on the quality and diversity of the dataset – if the dataset is dominated by suboptimal behaviors, the algorithm may struggle to learn an effective policy. Additionally, the computational overhead of the offline policy evaluation step could be a concern, especially for large or complex datasets.
Furthermore, the authors do not provide a detailed analysis of the potential risks or ethical considerations associated with offline RL and the use of historical optimal behaviors. In some applications, relying too heavily on past behaviors could lead to the perpetuation of biases or the adoption of undesirable behaviors.
It would be valuable for future research to explore these aspects in more depth, as well as to investigate the performance of OBAC in a wider range of environments and task domains. Rigorous testing and analysis of the algorithm's robustness and generalizability would help strengthen the case for its practical adoption.
Conclusion
The Offline-Boosted Actor-Critic (OBAC) algorithm presented in this paper represents an important step forward in the field of offline reinforcement learning. By adaptively blending optimal historical behaviors, OBAC can leverage the valuable information contained in a fixed dataset to learn more effective policies than approaches that rely solely on the current policy.
The key innovation of OBAC is its ability to adaptively combine past optimal behaviors based on their relevance to the current state, allowing the agent to benefit from the successes of previous optimal agents without being fully constrained by the limitations of the dataset.
As offline RL continues to grow in importance, particularly in applications where direct interaction with the environment is costly or dangerous, algorithms like OBAC will play a crucial role in enabling AI agents to learn and perform effectively in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Efficient Offline Reinforcement Learning: The Critic is Critical
Adam Jelley, Trevor McInroe, Sam Devlin, Amos Storkey
0
0
Recent work has demonstrated both benefits and limitations from using supervised approaches (without temporal-difference learning) for offline reinforcement learning. While off-policy reinforcement learning provides a promising approach for improving performance beyond supervised approaches, we observe that training is often inefficient and unstable due to temporal difference bootstrapping. In this paper we propose a best-of-both approach by first learning the behavior policy and critic with supervised learning, before improving with off-policy reinforcement learning. Specifically, we demonstrate improved efficiency by pre-training with a supervised Monte-Carlo value-error, making use of commonly neglected downstream information from the provided offline trajectories. We find that we are able to more than halve the training time of the considered offline algorithms on standard benchmarks, and surprisingly also achieve greater stability. We further build on the importance of having consistent policy and value functions to propose novel hybrid algorithms, TD3+BC+CQL and EDAC+BC, that regularize both the actor and the critic towards the behavior policy. This helps to more reliably improve on the behavior policy when learning from limited human demonstrations. Code is available at https://github.com/AdamJelley/EfficientOfflineRL
6/21/2024

Augmenting Offline RL with Unlabeled Data
Zhao Wang, Briti Gangopadhyay, Jia-Fong Yeh, Shingo Takamatsu
0
0
Recent advancements in offline Reinforcement Learning (Offline RL) have led to an increased focus on methods based on conservative policy updates to address the Out-of-Distribution (OOD) issue. These methods typically involve adding behavior regularization or modifying the critic learning objective, focusing primarily on states or actions with substantial dataset support. However, we challenge this prevailing notion by asserting that the absence of an action or state from a dataset does not necessarily imply its suboptimality. In this paper, we propose a novel approach to tackle the OOD problem. We introduce an offline RL teacher-student framework, complemented by a policy similarity measure. This framework enables the student policy to gain insights not only from the offline RL dataset but also from the knowledge transferred by a teacher policy. The teacher policy is trained using another dataset consisting of state-action pairs, which can be viewed as practical domain knowledge acquired without direct interaction with the environment. We believe this additional knowledge is key to effectively solving the OOD issue. This research represents a significant advancement in integrating a teacher-student network into the actor-critic framework, opening new avenues for studies on knowledge transfer in offline RL and effectively addressing the OOD challenge.
6/12/2024

Towards Robust Policy: Enhancing Offline Reinforcement Learning with Adversarial Attacks and Defenses
Thanh Nguyen, Tung M. Luu, Tri Ton, Chang D. Yoo
0
0
Offline reinforcement learning (RL) addresses the challenge of expensive and high-risk data exploration inherent in RL by pre-training policies on vast amounts of offline data, enabling direct deployment or fine-tuning in real-world environments. However, this training paradigm can compromise policy robustness, leading to degraded performance in practical conditions due to observation perturbations or intentional attacks. While adversarial attacks and defenses have been extensively studied in deep learning, their application in offline RL is limited. This paper proposes a framework to enhance the robustness of offline RL models by leveraging advanced adversarial attacks and defenses. The framework attacks the actor and critic components by perturbing observations during training and using adversarial defenses as regularization to enhance the learned policy. Four attacks and two defenses are introduced and evaluated on the D4RL benchmark. The results show the vulnerability of both the actor and critic to attacks and the effectiveness of the defenses in improving policy robustness. This framework holds promise for enhancing the reliability of offline RL models in practical scenarios.
5/21/2024
📊
Efficient Policy Evaluation with Offline Data Informed Behavior Policy Design
Shuze Liu, Shangtong Zhang
0
0
Most reinforcement learning practitioners evaluate their policies with online Monte Carlo estimators for either hyperparameter tuning or testing different algorithmic design choices, where the policy is repeatedly executed in the environment to get the average outcome. Such massive interactions with the environment are prohibitive in many scenarios. In this paper, we propose novel methods that improve the data efficiency of online Monte Carlo estimators while maintaining their unbiasedness. We first propose a tailored closed-form behavior policy that provably reduces the variance of an online Monte Carlo estimator. We then design efficient algorithms to learn this closed-form behavior policy from previously collected offline data. Theoretical analysis is provided to characterize how the behavior policy learning error affects the amount of reduced variance. Compared with previous works, our method achieves better empirical performance in a broader set of environments, with fewer requirements for offline data.
6/3/2024