Off-Policy Primal-Dual Safe Reinforcement Learning
2401.14758
0
1
🏅
Abstract
Primal-dual safe RL methods commonly perform iterations between the primal update of the policy and the dual update of the Lagrange Multiplier. Such a training paradigm is highly susceptible to the error in cumulative cost estimation since this estimation serves as the key bond connecting the primal and dual update processes. We show that this problem causes significant underestimation of cost when using off-policy methods, leading to the failure to satisfy the safety constraint. To address this issue, we propose conservative policy optimization, which learns a policy in a constraint-satisfying area by considering the uncertainty in cost estimation. This improves constraint satisfaction but also potentially hinders reward maximization. We then introduce local policy convexification to help eliminate such suboptimality by gradually reducing the estimation uncertainty. We provide theoretical interpretations of the joint coupling effect of these two ingredients and further verify them by extensive experiments. Results on benchmark tasks show that our method not only achieves an asymptotic performance comparable to state-of-the-art on-policy methods while using much fewer samples, but also significantly reduces constraint violation during training. Our code is available at https://github.com/ZifanWu/CAL.
Create account to get full access
Overview
- The paper focuses on addressing the issue of cost estimation error in primal-dual safe reinforcement learning (RL) methods.
- It proposes a two-part solution: 1) Conservative Policy Optimization to learn a policy that satisfies safety constraints, and 2) Local Policy Convexification to gradually reduce the estimation uncertainty.
- The method is shown to achieve performance comparable to state-of-the-art on-policy methods while using fewer samples and significantly reducing constraint violations during training.
Plain English Explanation
Primal-dual safe RL methods commonly perform alternating updates between the policy (the "primal" update) and the Lagrange Multiplier (the "dual" update). This training process relies heavily on accurately estimating the cumulative cost, which serves as the key connection between the primal and dual updates.
The paper shows that when using off-policy methods, this cost estimation can be significantly underestimated, leading to the failure to satisfy safety constraints. To address this issue, the authors propose Conservative Policy Optimization, which learns a policy that operates in a constrained area by considering the uncertainty in cost estimation. This helps ensure constraint satisfaction, but may also limit reward maximization.
To overcome this potential suboptimality, the paper introduces Local Policy Convexification, which gradually reduces the estimation uncertainty. The combination of these two techniques – Conservative Policy Optimization and Local Policy Convexification – allows the method to achieve strong performance while maintaining safety constraints.
Technical Explanation
The paper addresses the challenge of cost estimation error in primal-dual safe reinforcement learning (RL) methods. These methods alternate between updating the policy (the "primal" update) and the Lagrange Multiplier (the "dual" update), with the cumulative cost serving as the key connection between the two.
The authors show that when using off-policy methods, the cost estimation can be significantly underestimated, leading to the failure to satisfy safety constraints. To mitigate this issue, they propose Conservative Policy Optimization, which learns a policy that operates within a constrained area by considering the uncertainty in cost estimation. This helps ensure constraint satisfaction, but may also limit reward maximization.
To overcome the potential suboptimality introduced by the conservative policy, the paper introduces Local Policy Convexification. This technique gradually reduces the estimation uncertainty, allowing the method to achieve strong performance while maintaining safety constraints.
The authors provide theoretical interpretations of the joint coupling effect of these two ingredients and verify their effectiveness through extensive experiments. The results show that the proposed method not only achieves an asymptotic performance comparable to state-of-the-art on-policy methods while using much fewer samples, but also significantly reduces constraint violations during training.
Critical Analysis
The paper presents a compelling solution to the problem of cost estimation error in primal-dual safe RL methods. The authors' approach of combining Conservative Policy Optimization and Local Policy Convexification is well-designed and shows promising results.
However, the paper does not provide a detailed analysis of the potential limitations or caveats of the proposed method. For example, it would be valuable to understand how the method might perform in more complex environments or with different types of safety constraints.
Additionally, the authors do not discuss the computational overhead or training time required by their approach compared to other safe RL methods. This information would be useful for practitioners evaluating the feasibility of adopting the proposed technique.
Overall, the research presented in the paper is a significant contribution to the field of safe reinforcement learning, and the authors' insights could pave the way for further advancements in this area. Encouraging readers to think critically about the research and form their own opinions is an important aspect of a balanced analysis.
Conclusion
The paper tackles the critical issue of cost estimation error in primal-dual safe reinforcement learning methods, which can lead to the failure to satisfy safety constraints. The authors' proposed solution, combining Conservative Policy Optimization and Local Policy Convexification, demonstrates the ability to achieve strong performance while maintaining safety, using significantly fewer samples than state-of-the-art on-policy methods.
This research represents an important step forward in the field of safe RL, providing a practical approach to address the challenges posed by cost estimation errors. The implications of this work extend beyond the academic realm, as the ability to deploy RL systems that can reliably satisfy safety constraints is crucial for real-world applications in areas such as robotics, autonomous vehicles, and resource-constrained environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
A Dual Perspective of Reinforcement Learning for Imposing Policy Constraints
Bram De Cooman, Johan Suykens
0
0
Model-free reinforcement learning methods lack an inherent mechanism to impose behavioural constraints on the trained policies. While certain extensions exist, they remain limited to specific types of constraints, such as value constraints with additional reward signals or visitation density constraints. In this work we try to unify these existing techniques and bridge the gap with classical optimization and control theory, using a generic primal-dual framework for value-based and actor-critic reinforcement learning methods. The obtained dual formulations turn out to be especially useful for imposing additional constraints on the learned policy, as an intrinsic relationship between such dual constraints (or regularization terms) and reward modifications in the primal is reveiled. Furthermore, using this framework, we are able to introduce some novel types of constraints, allowing to impose bounds on the policy's action density or on costs associated with transitions between consecutive states and actions. From the adjusted primal-dual optimization problems, a practical algorithm is derived that supports various combinations of policy constraints that are automatically handled throughout training using trainable reward modifications. The resulting $texttt{DualCRL}$ method is examined in more detail and evaluated under different (combinations of) constraints on two interpretable environments. The results highlight the efficacy of the method, which ultimately provides the designer of such systems with a versatile toolbox of possible policy constraints.
4/26/2024
One-Shot Safety Alignment for Large Language Models via Optimal Dualization
Xinmeng Huang, Shuo Li, Edgar Dobriban, Osbert Bastani, Hamed Hassani, Dongsheng Ding
0
0
The growing safety concerns surrounding Large Language Models (LLMs) raise an urgent need to align them with diverse human preferences to simultaneously enhance their helpfulness and safety. A promising approach is to enforce safety constraints through Reinforcement Learning from Human Feedback (RLHF). For such constrained RLHF, common Lagrangian-based primal-dual policy optimization methods are computationally expensive and often unstable. This paper presents a dualization perspective that reduces constrained alignment to an equivalent unconstrained alignment problem. We do so by pre-optimizing a smooth and convex dual function that has a closed form. This shortcut eliminates the need for cumbersome primal-dual policy iterations, thus greatly reducing the computational burden and improving training stability. Our strategy leads to two practical algorithms in model-based and preference-based scenarios (MoCAN and PeCAN, respectively). A broad range of experiments demonstrate the effectiveness of our methods.
5/31/2024
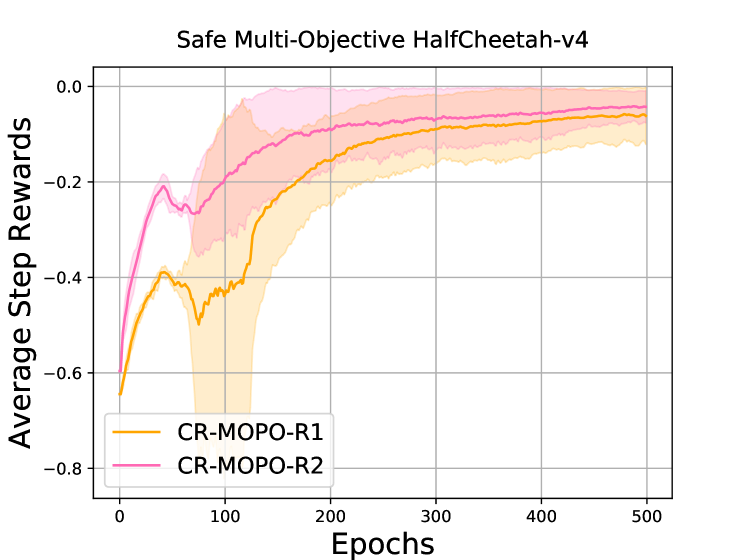
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
0
0
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
5/28/2024
🔍
A Primal-Dual Algorithm for Offline Constrained Reinforcement Learning with Linear MDPs
Kihyuk Hong, Ambuj Tewari
0
0
We study offline reinforcement learning (RL) with linear MDPs under the infinite-horizon discounted setting which aims to learn a policy that maximizes the expected discounted cumulative reward using a pre-collected dataset. Existing algorithms for this setting either require a uniform data coverage assumptions or are computationally inefficient for finding an $epsilon$-optimal policy with $O(epsilon^{-2})$ sample complexity. In this paper, we propose a primal dual algorithm for offline RL with linear MDPs in the infinite-horizon discounted setting. Our algorithm is the first computationally efficient algorithm in this setting that achieves sample complexity of $O(epsilon^{-2})$ with partial data coverage assumption. Our work is an improvement upon a recent work that requires $O(epsilon^{-4})$ samples. Moreover, we extend our algorithm to work in the offline constrained RL setting that enforces constraints on additional reward signals.
6/4/2024