Off-Policy Correction For Multi-Agent Reinforcement Learning
2111.11229
0
0
🏅
Abstract
Multi-agent reinforcement learning (MARL) provides a framework for problems involving multiple interacting agents. Despite apparent similarity to the single-agent case, multi-agent problems are often harder to train and analyze theoretically. In this work, we propose MA-Trace, a new on-policy actor-critic algorithm, which extends V-Trace to the MARL setting. The key advantage of our algorithm is its high scalability in a multi-worker setting. To this end, MA-Trace utilizes importance sampling as an off-policy correction method, which allows distributing the computations with no impact on the quality of training. Furthermore, our algorithm is theoretically grounded - we prove a fixed-point theorem that guarantees convergence. We evaluate the algorithm extensively on the StarCraft Multi-Agent Challenge, a standard benchmark for multi-agent algorithms. MA-Trace achieves high performance on all its tasks and exceeds state-of-the-art results on some of them.
Create account to get full access
Overview
- Multi-agent reinforcement learning (MARL) is a field that studies how multiple interacting agents can learn to solve complex problems.
- MARL problems are often more challenging to train and analyze compared to single-agent reinforcement learning.
- The authors propose a new MARL algorithm called MA-Trace that extends the V-Trace algorithm and is highly scalable for multi-worker settings.
- MA-Trace uses importance sampling to enable distributed computation without impacting training quality and is theoretically grounded with a proven convergence guarantee.
- The algorithm is evaluated on the StarCraft Multi-Agent Challenge, a standard benchmark for MARL, and achieves high performance.
Plain English Explanation
Imagine a group of people trying to solve a problem together. In the single-person case, it's like one person trying to solve a puzzle alone. But when you have multiple people, it gets more complicated. They have to coordinate, communicate, and figure out how to work together effectively.
That's what multi-agent reinforcement learning (MARL) is all about. It's a way for multiple "agents" (like software programs or robots) to learn how to solve problems by interacting with each other and their environment. The challenge is that MARL problems are often harder to train and understand theoretically compared to single-agent problems.
The researchers in this paper developed a new MARL algorithm called MA-Trace that builds on an existing algorithm called V-Trace. The key advantage of MA-Trace is that it can scale well to settings with multiple workers (like computers) working on the problem simultaneously.
The researchers did this by using a technique called "importance sampling" that allows the computations to be distributed across multiple workers without affecting the quality of the training. This makes the algorithm more efficient and practical to use in real-world situations.
Importantly, the researchers also proved that their MA-Trace algorithm is theoretically sound and guaranteed to converge, meaning it will reliably find a good solution. They tested the algorithm on a well-known benchmark for MARL called the StarCraft Multi-Agent Challenge and found that it performed very well, even beating existing state-of-the-art methods on some tasks.
Technical Explanation
The paper proposes a new on-policy actor-critic algorithm for multi-agent reinforcement learning called MA-Trace. It extends the V-Trace algorithm, which was originally developed for the single-agent case, to the MARL setting.
The key advantage of MA-Trace is its high scalability in a multi-worker environment. It achieves this by using importance sampling as an off-policy correction method, which allows distributing the computations across multiple workers without impacting the quality of the training.
Theoretically, the authors prove a fixed-point theorem that guarantees the convergence of MA-Trace. This provides a strong theoretical foundation for the algorithm.
The algorithm is evaluated extensively on the StarCraft Multi-Agent Challenge, a standard benchmark for MARL. MA-Trace achieves high performance across all the tasks in this challenge and exceeds the state-of-the-art results on some of them.
Critical Analysis
The paper provides a thorough theoretical analysis of the MA-Trace algorithm and demonstrates its strong empirical performance on a well-established MARL benchmark. However, the authors do note some potential limitations and areas for further research.
One limitation mentioned is that the convergence guarantee assumes the presence of a fixed point, which may not always hold in practice. Additionally, the paper does not explore the sample efficiency of MA-Trace compared to other MARL algorithms, which could be an important consideration in real-world applications.
Further research could investigate the scalability of MA-Trace to even larger multi-agent settings, as well as its robustness to various types of environment dynamics and agent interactions. Exploring the interpretability of the learned policies could also be a valuable direction, as understanding how the agents coordinate and make decisions is crucial for many applications.
Overall, the MA-Trace algorithm represents a promising advance in the field of MARL, with its strong theoretical foundations and empirical performance. However, as with any research, there are still opportunities for further refinement and exploration to fully unlock the potential of this approach.
Conclusion
The paper presents a new multi-agent reinforcement learning algorithm called MA-Trace that extends the V-Trace algorithm to the MARL setting. The key innovation is the use of importance sampling to enable high scalability in a multi-worker environment, combined with a strong theoretical foundation that guarantees convergence.
The extensive evaluation on the StarCraft Multi-Agent Challenge demonstrates the practical effectiveness of MA-Trace, as it achieves state-of-the-art performance on several tasks. This research represents an important step forward in the field of MARL, providing a scalable and theoretically grounded approach to solving complex, multi-agent problems.
As MARL becomes increasingly relevant in areas like robotics, autonomous systems, and collaborative decision-making, algorithms like MA-Trace will be crucial for developing efficient and reliable multi-agent solutions. This work lays the groundwork for further advancements in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024
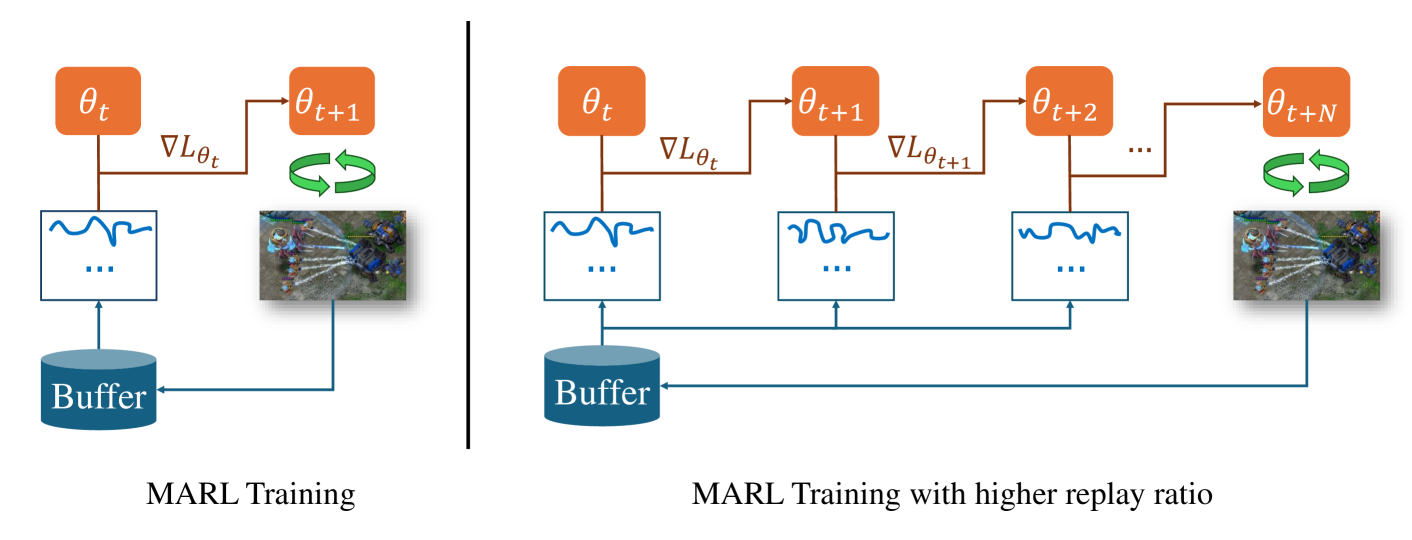
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Linjie Xu, Zichuan Liu, Alexander Dockhorn, Diego Perez-Liebana, Jinyu Wang, Lei Song, Jiang Bian
0
0
One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
4/16/2024
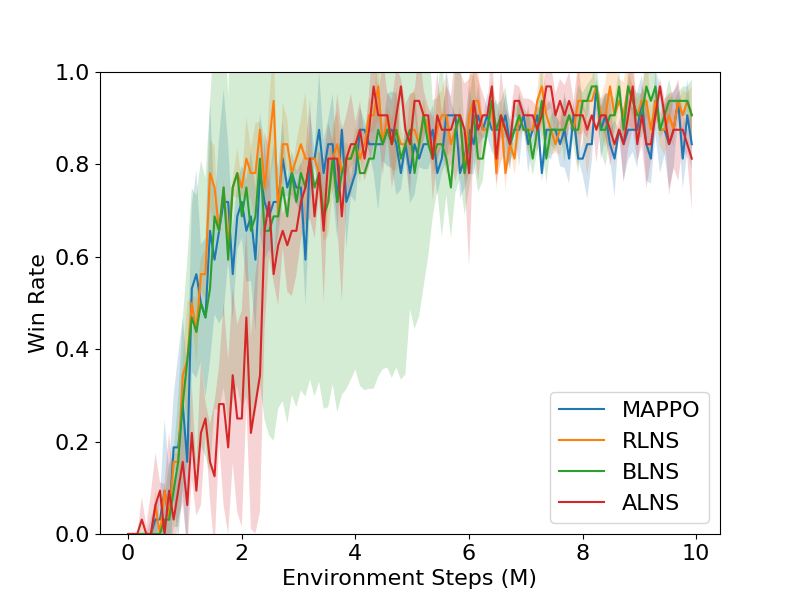
MARL-LNS: Cooperative Multi-agent Reinforcement Learning via Large Neighborhoods Search
Weizhe Chen, Sven Koenig, Bistra Dilkina
0
0
Cooperative multi-agent reinforcement learning (MARL) has been an increasingly important research topic in the last half-decade because of its great potential for real-world applications. Because of the curse of dimensionality, the popular centralized training decentralized execution framework requires a long time in training, yet still cannot converge efficiently. In this paper, we propose a general training framework, MARL-LNS, to algorithmically address these issues by training on alternating subsets of agents using existing deep MARL algorithms as low-level trainers, while not involving any additional parameters to be trained. Based on this framework, we provide three algorithm variants based on the framework: random large neighborhood search (RLNS), batch large neighborhood search (BLNS), and adaptive large neighborhood search (ALNS), which alternate the subsets of agents differently. We test our algorithms on both the StarCraft Multi-Agent Challenge and Google Research Football, showing that our algorithms can automatically reduce at least 10% of training time while reaching the same final skill level as the original algorithm.
4/5/2024
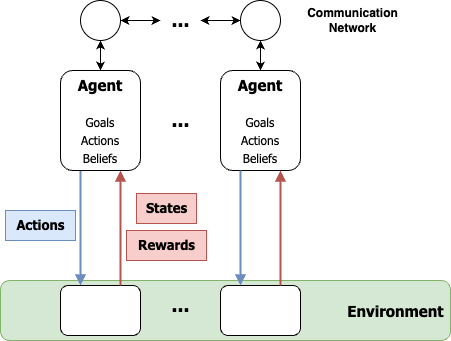
New!Multi-agent Reinforcement Learning: A Comprehensive Survey
Dom Huh, Prasant Mohapatra
0
0
Multi-agent systems (MAS) are widely prevalent and crucially important in numerous real-world applications, where multiple agents must make decisions to achieve their objectives in a shared environment. Despite their ubiquity, the development of intelligent decision-making agents in MAS poses several open challenges to their effective implementation. This survey examines these challenges, placing an emphasis on studying seminal concepts from game theory (GT) and machine learning (ML) and connecting them to recent advancements in multi-agent reinforcement learning (MARL), i.e. the research of data-driven decision-making within MAS. Therefore, the objective of this survey is to provide a comprehensive perspective along the various dimensions of MARL, shedding light on the unique opportunities that are presented in MARL applications while highlighting the inherent challenges that accompany this potential. Therefore, we hope that our work will not only contribute to the field by analyzing the current landscape of MARL but also motivate future directions with insights for deeper integration of concepts from related domains of GT and ML. With this in mind, this work delves into a detailed exploration of recent and past efforts of MARL and its related fields and describes prior solutions that were proposed and their limitations, as well as their applications.
7/4/2024