Offline Energy-Optimal LLM Serving: Workload-Based Energy Models for LLM Inference on Heterogeneous Systems

0

Sign in to get full access
Overview
- Offline Energy-Optimal LLM Serving: Workload-Based Energy Models for LLM Inference on Heterogeneous Systems
- Explores energy optimization for serving large language models (LLMs) on heterogeneous systems
- Develops energy models based on workload characteristics to enable energy-efficient LLM inference
Plain English Explanation
The paper focuses on making the process of using large language models (LLMs) more energy-efficient. LLMs are powerful AI systems that can perform a variety of tasks, but running them requires a lot of computing power and energy. The researchers developed models that can predict the energy usage of running LLM inference (the process of using the LLM to generate outputs) based on the specific workload or task being performed.
By understanding the energy usage patterns, the goal is to optimize the system to minimize energy consumption without sacrificing the performance of the LLM. This is particularly important as LLMs become more widely used, as reducing their energy footprint can have significant environmental and cost benefits. The researchers tested their energy models on different hardware setups, showing how they can be used to choose the most energy-efficient configuration for a given workload.
Technical Explanation
The paper presents [object Object]. The key contributions are:
-
Energy Modeling: The researchers developed energy consumption models for LLM inference that account for the specific workload characteristics, such as input size, inference latency, and hardware configuration. These models can accurately predict the energy usage of running LLM inference on different hardware setups.
-
Heterogeneous System Optimization: By understanding the energy usage patterns, the paper explores techniques to optimize LLM serving on heterogeneous systems (i.e., systems with a mix of CPU, GPU, and other accelerators). This allows choosing the most energy-efficient hardware configuration for a given LLM inference workload.
-
Experimental Evaluation: The researchers evaluated their energy models and optimization techniques on real-world LLM inference workloads, demonstrating significant energy savings (up to 35%) compared to baseline approaches without compromising performance.
The key insight is that energy consumption for LLM inference is heavily dependent on the specific workload characteristics and hardware configuration. By developing accurate energy models, the paper enables [object Object].
Critical Analysis
The paper provides a thorough and practical approach to energy optimization for LLM serving, addressing an important issue as the use of large language models continues to grow. The energy models developed are a valuable contribution, as they can help system designers and operators make more informed decisions about hardware configuration and resource allocation to minimize energy consumption.
However, the paper does not address some potential limitations and areas for further research:
-
Generalizability: The energy models were evaluated on a limited set of LLM workloads and hardware configurations. More extensive testing would be needed to ensure the models can generalize to a wider range of scenarios, including emerging LLM architectures and use cases.
-
Dynamic Optimization: The current approach focuses on offline optimization, where the energy-efficient configuration is determined before deployment. [object Object] that can adapt to changing workloads and system conditions in real-time could further improve energy efficiency.
-
Holistic System Considerations: The paper primarily focuses on the energy efficiency of LLM inference, but a more [object Object], including data preprocessing, model loading, and other system components, could provide a more complete picture of energy optimization opportunities.
-
User-Centric Optimization: The current approach optimizes for overall energy efficiency, but [object Object], such as response time and cost, could lead to more holistic optimization strategies that balance multiple objectives.
Conclusion
This paper presents a significant step forward in enabling energy-efficient serving of large language models on heterogeneous systems. By developing accurate energy models that account for workload characteristics, the researchers have laid the groundwork for optimizing LLM inference to minimize energy consumption without sacrificing performance. As the use of LLMs continues to grow, these techniques can help reduce the environmental impact and operational costs associated with running these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Offline Energy-Optimal LLM Serving: Workload-Based Energy Models for LLM Inference on Heterogeneous Systems
Grant Wilkins, Srinivasan Keshav, Richard Mortier
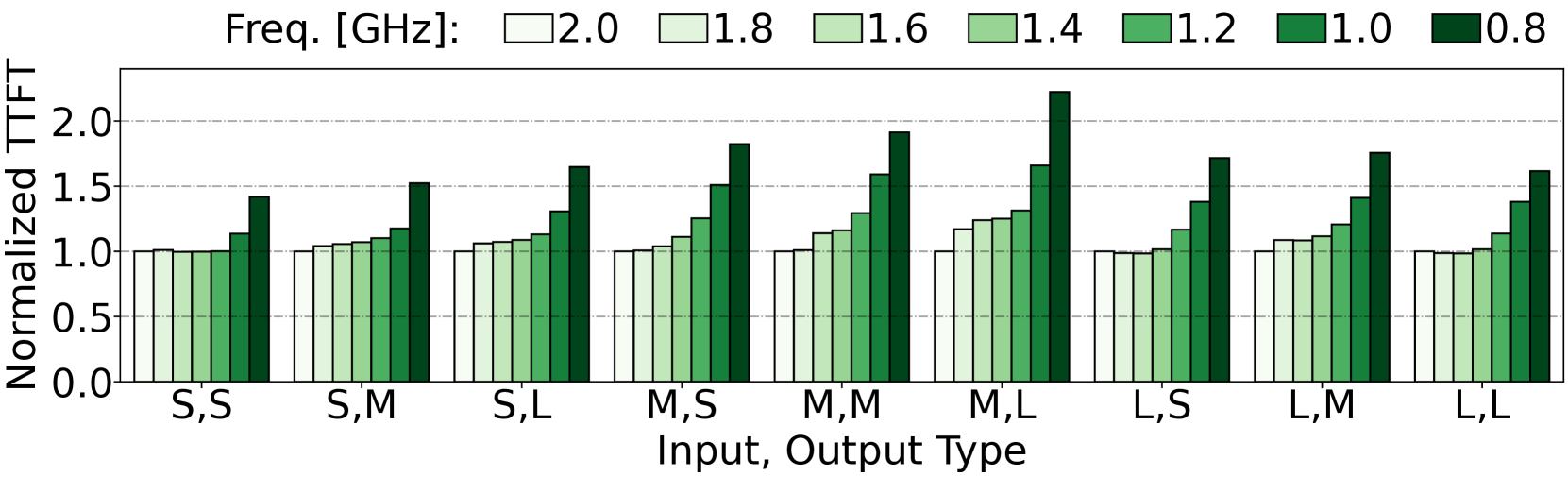
The rapid adoption of large language models (LLMs) has led to significant advances in natural language processing and text generation. However, the energy consumed through LLM model inference remains a major challenge for sustainable AI deployment. To address this problem, we model the workload-dependent energy consumption and runtime of LLM inference tasks on heterogeneous GPU-CPU systems. By conducting an extensive characterization study of several state-of-the-art LLMs and analyzing their energy and runtime behavior across different magnitudes of input prompts and output text, we develop accurate (R^2>0.96) energy and runtime models for each LLM. We employ these models to explore an offline, energy-optimal LLM workload scheduling framework. Through a case study, we demonstrate the advantages of energy and accuracy aware scheduling compared to existing best practices.
Read more7/8/2024
0
Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference
Jovan Stojkovic, Esha Choukse, Chaojie Zhang, Inigo Goiri, Josep Torrellas
With the ubiquitous use of modern large language models (LLMs) across industries, the inference serving for these models is ever expanding. Given the high compute and memory requirements of modern LLMs, more and more top-of-the-line GPUs are being deployed to serve these models. Energy availability has come to the forefront as the biggest challenge for data center expansion to serve these models. In this paper, we present the trade-offs brought up by making energy efficiency the primary goal of LLM serving under performance SLOs. We show that depending on the inputs, the model, and the service-level agreements, there are several knobs available to the LLM inference provider to use for being energy efficient. We characterize the impact of these knobs on the latency, throughput, as well as the energy. By exploring these trade-offs, we offer valuable insights into optimizing energy usage without compromising on performance, thereby paving the way for sustainable and cost-effective LLM deployment in data center environments.
Read more4/1/2024

0
Hybrid Heterogeneous Clusters Can Lower the Energy Consumption of LLM Inference Workloads
Grant Wilkins, Srinivasan Keshav, Richard Mortier
Both the training and use of Large Language Models (LLMs) require large amounts of energy. Their increasing popularity, therefore, raises critical concerns regarding the energy efficiency and sustainability of data centers that host them. This paper addresses the challenge of reducing energy consumption in data centers running LLMs. We propose a hybrid data center model that uses a cost-based scheduling framework to dynamically allocate LLM tasks across hardware accelerators that differ in their energy efficiencies and computational capabilities. Specifically, our workload-aware strategy determines whether tasks are processed on energy-efficient processors or high-performance GPUs based on the number of input and output tokens in a query. Our analysis of a representative LLM dataset, finds that this hybrid strategy can reduce CPU+GPU energy consumption by 7.5% compared to a workload-unaware baseline.
Read more7/2/2024

0
DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency
Jovan Stojkovic, Chaojie Zhang, 'I~nigo Goiri, Josep Torrellas, Esha Choukse
The rapid evolution and widespread adoption of generative large language models (LLMs) have made them a pivotal workload in various applications. Today, LLM inference clusters receive a large number of queries with strict Service Level Objectives (SLOs). To achieve the desired performance, these models execute on power-hungry GPUs causing the inference clusters to consume large amount of energy and, consequently, result in excessive carbon emissions. Fortunately, we find that there is a great opportunity to exploit the heterogeneity in inference compute properties and fluctuations in inference workloads, to significantly improve energy-efficiency. However, such a diverse and dynamic environment creates a large search-space where different system configurations (e.g., number of instances, model parallelism, and GPU frequency) translate into different energy-performance trade-offs. To address these challenges, we propose DynamoLLM, the first energy-management framework for LLM inference environments. DynamoLLM automatically and dynamically reconfigures the inference cluster to optimize for energy and cost of LLM serving under the service's performance SLOs. We show that at a service-level, DynamoLLM conserves 53% energy and 38% operational carbon emissions, and reduces 61% cost to the customer, while meeting the latency SLOs.
Read more8/2/2024