OLLIE: Imitation Learning from Offline Pretraining to Online Finetuning
2405.17477
0
0
Abstract
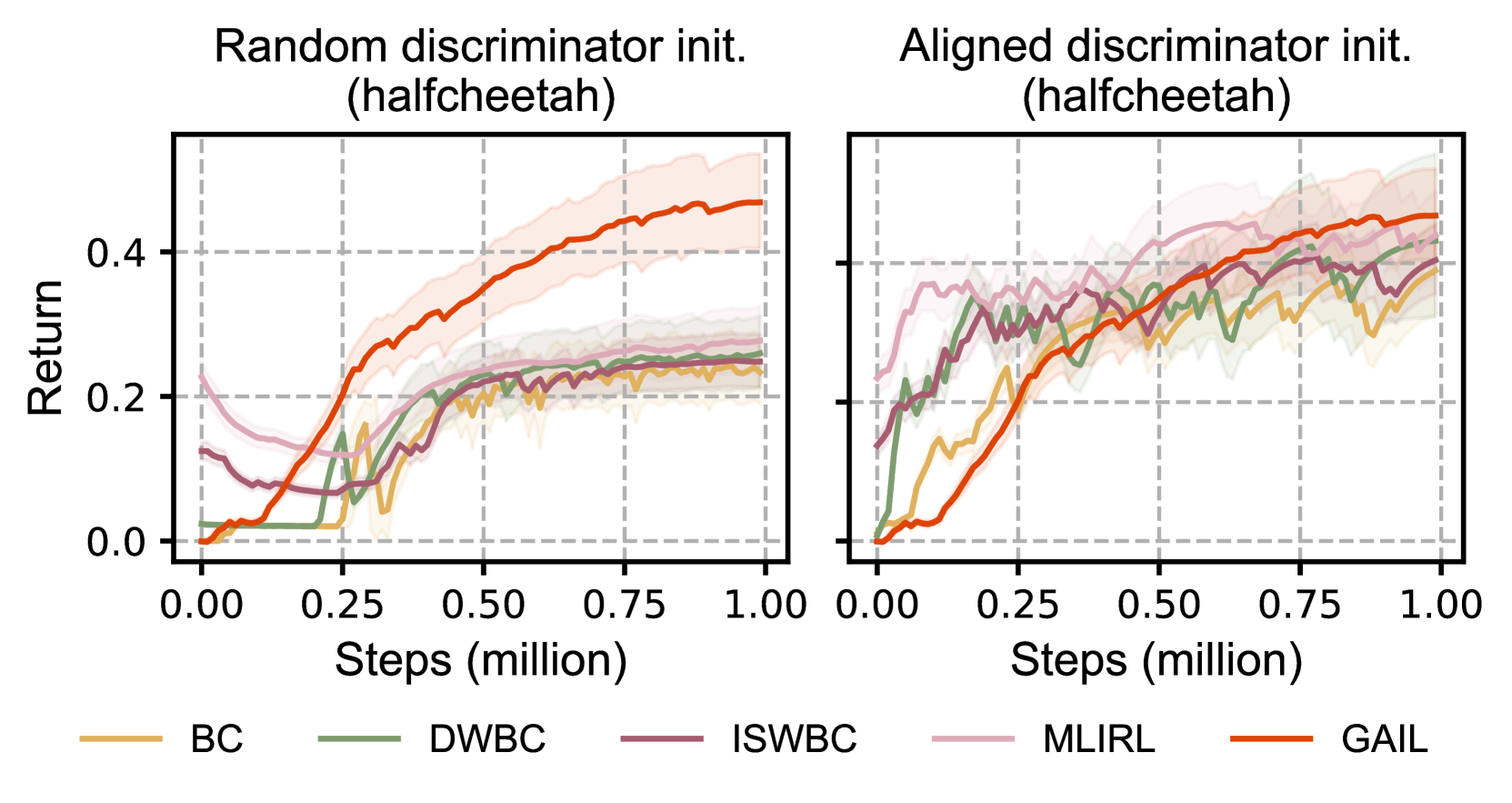
In this paper, we study offline-to-online Imitation Learning (IL) that pretrains an imitation policy from static demonstration data, followed by fast finetuning with minimal environmental interaction. We find the naive combination of existing offline IL and online IL methods tends to behave poorly in this context, because the initial discriminator (often used in online IL) operates randomly and discordantly against the policy initialization, leading to misguided policy optimization and $textit{unlearning}$ of pretraining knowledge. To overcome this challenge, we propose a principled offline-to-online IL method, named $texttt{OLLIE}$, that simultaneously learns a near-expert policy initialization along with an $textit{aligned discriminator initialization}$, which can be seamlessly integrated into online IL, achieving smooth and fast finetuning. Empirically, $texttt{OLLIE}$ consistently and significantly outperforms the baseline methods in $textbf{20}$ challenging tasks, from continuous control to vision-based domains, in terms of performance, demonstration efficiency, and convergence speed. This work may serve as a foundation for further exploration of pretraining and finetuning in the context of IL.
Create account to get full access
Overview
- This paper introduces a novel approach called OLLIE (Offline Learning to Online Finetuning) that leverages offline pretraining to enable efficient online finetuning for imitation learning tasks.
- OLLIE combines the strengths of offline pretraining and online finetuning to achieve better sample efficiency and performance compared to purely online or offline methods.
- The key idea is to first pretrain a policy network using large-scale offline demonstration data, and then finetune it on a target task using limited online interactions.
Plain English Explanation
OLLIE is a way to teach an AI system how to do a task by first showing it a lot of examples of the task being done, and then letting it practice the task in a real environment with feedback. This is more efficient than just practicing the task in the real environment from the start, because the AI system can learn the general principles from the examples before trying it out in the real world.
The paper on how to leverage diverse demonstrations for offline imitation and the paper on a life-long policy learning framework discuss similar approaches to using offline data to learn general skills before finetuning on a specific task.
In the OLLIE method, the AI system first learns a general policy by looking at a large dataset of demonstrations of the task being done. This gives it a good starting point. Then, it fine-tunes this policy by practicing the task in the real environment and getting feedback. This combination of offline pretraining and online finetuning allows the AI to learn the task more efficiently than if it had to learn everything from scratch in the real world.
The paper on SPRINQL, a sub-optimal demonstrations driven offline imitation approach, the paper on imitation learning from unstructured social demonstrations, and the paper on programmatic imitation learning all explore different ways to leverage offline data for imitation learning.
Technical Explanation
The key technical innovation in OLLIE is the use of offline pretraining to initialize the policy network, followed by online finetuning to adapt it to the target task. During offline pretraining, the policy network is trained on a large dataset of demonstration trajectories, allowing it to learn general behavioral patterns.
This pretrained policy is then finetuned online by interacting with the target environment and receiving rewards. The online finetuning process fine-tunes the policy parameters to optimize for the specific task, while preserving the general knowledge learned during pretraining.
The authors evaluate OLLIE on a range of continuous control tasks and show that it outperforms both purely offline and purely online imitation learning approaches in terms of sample efficiency and asymptotic performance. The benefits of OLLIE are most pronounced when the online interactions are limited, as the offline pretraining allows the policy to get a good initial understanding of the task.
Critical Analysis
The OLLIE approach makes a lot of intuitive sense - leveraging offline data to bootstrap the learning process before fine-tuning in the target environment. This is similar to how humans learn, first observing and imitating others before practicing a skill themselves.
However, the paper does not deeply explore the limitations of this approach. For example, the quality and diversity of the offline demonstration data is crucial - if the demonstrations do not cover the full range of behaviors needed for the target task, the pretrained policy may struggle to generalize. The authors also do not discuss how to automatically determine the right balance between offline pretraining and online finetuning.
Additionally, the evaluation is focused on relatively simple continuous control tasks. It would be interesting to see how well OLLIE scales to more complex, high-dimensional tasks that may require more sophisticated exploration and credit assignment during the online finetuning stage.
Overall, OLLIE represents a promising direction for improving the sample efficiency of imitation learning, but more research is needed to fully understand its capabilities and limitations across a wider range of domains.
Conclusion
The OLLIE approach combines the strengths of offline pretraining and online finetuning to enable efficient imitation learning. By first learning general behavioral patterns from a large dataset of demonstrations, and then fine-tuning the policy in the target environment, OLLIE achieves better sample efficiency and performance compared to purely online or offline methods.
This work builds on a growing body of research exploring ways to leverage diverse offline data for imitation learning, as seen in the paper on how to leverage diverse demonstrations, the life-long policy learning framework, and the other related papers mentioned.
As AI systems become more capable of learning from data, techniques like OLLIE will be increasingly important for enabling efficient and robust learning in real-world applications. However, further research is needed to fully understand the limitations and scaling potential of this approach across a wider range of complex tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Online Adaptation for Enhancing Imitation Learning Policies
Federico Malato, Ville Hautamaki
0
0
Imitation learning enables autonomous agents to learn from human examples, without the need for a reward signal. Still, if the provided dataset does not encapsulate the task correctly, or when the task is too complex to be modeled, such agents fail to reproduce the expert policy. We propose to recover from these failures through online adaptation. Our approach combines the action proposal coming from a pre-trained policy with relevant experience recorded by an expert. The combination results in an adapted action that closely follows the expert. Our experiments show that an adapted agent performs better than its pure imitation learning counterpart. Notably, adapted agents can achieve reasonable performance even when the base, non-adapted policy catastrophically fails.
6/10/2024

How to Leverage Diverse Demonstrations in Offline Imitation Learning
Sheng Yue, Jiani Liu, Xingyuan Hua, Ju Ren, Sen Lin, Junshan Zhang, Yaoxue Zhang
0
0
Offline Imitation Learning (IL) with imperfect demonstrations has garnered increasing attention owing to the scarcity of expert data in many real-world domains. A fundamental problem in this scenario is how to extract positive behaviors from noisy data. In general, current approaches to the problem select data building on state-action similarity to given expert demonstrations, neglecting precious information in (potentially abundant) $textit{diverse}$ state-actions that deviate from expert ones. In this paper, we introduce a simple yet effective data selection method that identifies positive behaviors based on their resultant states -- a more informative criterion enabling explicit utilization of dynamics information and effective extraction of both expert and beneficial diverse behaviors. Further, we devise a lightweight behavior cloning algorithm capable of leveraging the expert and selected data correctly. In the experiments, we evaluate our method on a suite of complex and high-dimensional offline IL benchmarks, including continuous-control and vision-based tasks. The results demonstrate that our method achieves state-of-the-art performance, outperforming existing methods on $textbf{20/21}$ benchmarks, typically by $textbf{2-5x}$, while maintaining a comparable runtime to Behavior Cloning ($texttt{BC}$).
5/31/2024
🏷️
Beyond Imitation: A Life-long Policy Learning Framework for Path Tracking Control of Autonomous Driving
C. Gong, C. Lu, Z. Li, Z. Liu, J. Gong, X. Chen
0
0
Model-free learning-based control methods have recently shown significant advantages over traditional control methods in avoiding complex vehicle characteristic estimation and parameter tuning. As a primary policy learning method, imitation learning (IL) is capable of learning control policies directly from expert demonstrations. However, the performance of IL policies is highly dependent on the data sufficiency and quality of the demonstrations. To alleviate the above problems of IL-based policies, a lifelong policy learning (LLPL) framework is proposed in this paper, which extends the IL scheme with lifelong learning (LLL). First, a novel IL-based model-free control policy learning method for path tracking is introduced. Even with imperfect demonstration, the optimal control policy can be learned directly from historical driving data. Second, by using the LLL method, the pre-trained IL policy can be safely updated and fine-tuned with incremental execution knowledge. Third, a knowledge evaluation method for policy learning is introduced to avoid learning redundant or inferior knowledge, thus ensuring the performance improvement of online policy learning. Experiments are conducted using a high-fidelity vehicle dynamic model in various scenarios to evaluate the performance of the proposed method. The results show that the proposed LLPL framework can continuously improve the policy performance with collected incremental driving data, and achieves the best accuracy and control smoothness compared to other baseline methods after evolving on a 7 km curved road. Through learning and evaluation with noisy real-life data collected in an off-road environment, the proposed LLPL framework also demonstrates its applicability in learning and evolving in real-life scenarios.
4/29/2024

SPRINQL: Sub-optimal Demonstrations driven Offline Imitation Learning
Huy Hoang, Tien Mai, Pradeep Varakantham
0
0
We focus on offline imitation learning (IL), which aims to mimic an expert's behavior using demonstrations without any interaction with the environment. One of the main challenges in offline IL is the limited support of expert demonstrations, which typically cover only a small fraction of the state-action space. While it may not be feasible to obtain numerous expert demonstrations, it is often possible to gather a larger set of sub-optimal demonstrations. For example, in treatment optimization problems, there are varying levels of doctor treatments available for different chronic conditions. These range from treatment specialists and experienced general practitioners to less experienced general practitioners. Similarly, when robots are trained to imitate humans in routine tasks, they might learn from individuals with different levels of expertise and efficiency. In this paper, we propose an offline IL approach that leverages the larger set of sub-optimal demonstrations while effectively mimicking expert trajectories. Existing offline IL methods based on behavior cloning or distribution matching often face issues such as overfitting to the limited set of expert demonstrations or inadvertently imitating sub-optimal trajectories from the larger dataset. Our approach, which is based on inverse soft-Q learning, learns from both expert and sub-optimal demonstrations. It assigns higher importance (through learned weights) to aligning with expert demonstrations and lower importance to aligning with sub-optimal ones. A key contribution of our approach, called SPRINQL, is transforming the offline IL problem into a convex optimization over the space of Q functions. Through comprehensive experimental evaluations, we demonstrate that the SPRINQL algorithm achieves state-of-the-art (SOTA) performance on offline IL benchmarks. Code is available at https://github.com/hmhuy2000/SPRINQL.
5/24/2024