PixelLM: Pixel Reasoning with Large Multimodal Model

0
📈
Sign in to get full access
Overview
- Researchers introduce PixelLM, a large multimodal model (LMM) that can effectively generate pixel-level masks for image reasoning tasks involving multiple open-world targets.
- PixelLM includes a novel, lightweight pixel decoder and a comprehensive segmentation codebook, which allow it to efficiently produce high-quality masks without the need for additional costly segmentation models.
- The researchers also propose a target refinement loss to enhance the model's ability to differentiate between multiple targets, leading to improved mask quality.
- To advance research in this area, the researchers construct MUSE, a high-quality multi-target reasoning segmentation benchmark.
Plain English Explanation
Large multimodal models (LMMs) have made impressive progress, but generating pixel-level masks for image reasoning tasks involving multiple real-world objects remains a challenge. To address this, the researchers developed PixelLM, a new type of LMM that can effectively create detailed masks, or outlines, of the various objects in an image.
The key innovations in PixelLM are a lightweight pixel decoder and a comprehensive segmentation codebook. The decoder can efficiently produce these masks from the hidden information in the model, without requiring additional, costly segmentation models. The researchers also introduced a "target refinement loss" to help the model better distinguish between multiple objects in the image, further improving the quality of the masks.
To encourage more research in this area, the team also created a new benchmark dataset called MUSE, which contains high-quality examples of multi-target image reasoning and segmentation tasks.
Overall, PixelLM demonstrates significant improvements in pixel-level image reasoning and understanding compared to previous methods, as shown across several benchmarks, including MUSE and single- and multi-referring segmentation tasks. The researchers plan to release the code, models, and datasets to support further advancements in this important field of large language model research.
Technical Explanation
At the core of PixelLM is a novel, lightweight pixel decoder that can efficiently generate pixel-level masks from the hidden embeddings of a comprehensive segmentation codebook. This codebook encodes detailed, target-relevant information, which the decoder then uses to produce high-quality masks.
The researchers designed PixelLM to harmonize with the structure of popular LMMs, avoiding the need for separate, costly segmentation models. Additionally, they introduced a target refinement loss to enhance the model's ability to differentiate between multiple targets in the image, leading to substantially improved mask quality.
To advance research in this area, the team constructed MUSE, a high-quality multi-target reasoning segmentation benchmark. Evaluations on MUSE, as well as single- and multi-referring segmentation tasks, demonstrate that PixelLM outperforms well-established methods in pixel-level image reasoning and understanding.
The researchers also conducted comprehensive ablation studies to confirm the efficacy of each proposed component of PixelLM, including the pixel decoder and target refinement loss.
Critical Analysis
While PixelLM represents a significant advancement in pixel-level image reasoning and understanding, the researchers acknowledge that there is still room for improvement. For example, the paper notes that PixelLM may struggle with certain types of complex scenes or objects that are not well-represented in the training data.
Additionally, the researchers highlight the potential for further refinements to the target refinement loss or the segmentation codebook to enhance the model's ability to differentiate between multiple targets. Ongoing research into large language models may also yield insights that could be incorporated to improve PixelLM's performance.
It's worth noting that the MUSE benchmark, while a valuable contribution, may not capture the full complexity of real-world image reasoning tasks. As with any benchmark, there may be biases or limitations that could affect the generalization of the results.
Overall, PixelLM represents an important step forward in bridging the gap between image segmentation and large language models, but continued research and refinement will be needed to fully realize the potential of this approach.
Conclusion
The introduction of PixelLM, a large multimodal model with a novel pixel decoder and segmentation codebook, represents a significant advancement in pixel-level image reasoning and understanding. By efficiently generating high-quality masks for multiple open-world targets, PixelLM addresses a key challenge in this domain and outperforms well-established methods across various benchmarks.
The researchers' creation of the MUSE dataset further contributes to the field by providing a valuable resource for evaluating and advancing research in multi-target image reasoning and segmentation. While there is still room for improvement, PixelLM's innovative design and strong performance highlight the potential of large language models to tackle complex visual reasoning tasks, with important implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
PixelLM: Pixel Reasoning with Large Multimodal Model
Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, Xiaojie Jin
While large multimodal models (LMMs) have achieved remarkable progress, generating pixel-level masks for image reasoning tasks involving multiple open-world targets remains a challenge. To bridge this gap, we introduce PixelLM, an effective and efficient LMM for pixel-level reasoning and understanding. Central to PixelLM is a novel, lightweight pixel decoder and a comprehensive segmentation codebook. The decoder efficiently produces masks from the hidden embeddings of the codebook tokens, which encode detailed target-relevant information. With this design, PixelLM harmonizes with the structure of popular LMMs and avoids the need for additional costly segmentation models. Furthermore, we propose a target refinement loss to enhance the model's ability to differentiate between multiple targets, leading to substantially improved mask quality. To advance research in this area, we construct MUSE, a high-quality multi-target reasoning segmentation benchmark. PixelLM excels across various pixel-level image reasoning and understanding tasks, outperforming well-established methods in multiple benchmarks, including MUSE, single- and multi-referring segmentation. Comprehensive ablations confirm the efficacy of each proposed component. All code, models, and datasets will be publicly available.
Read more7/19/2024
0
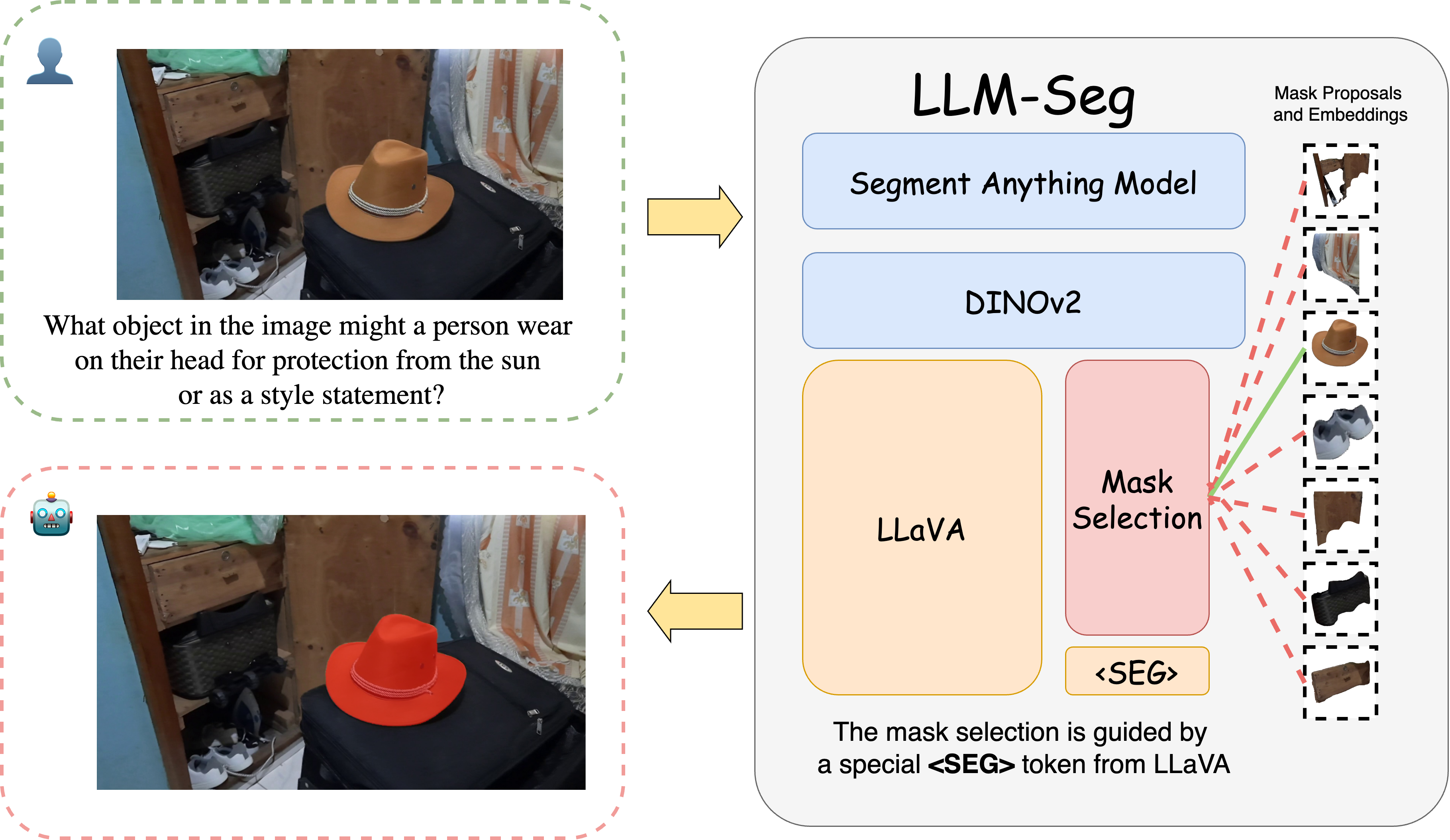
LLM-Seg: Bridging Image Segmentation and Large Language Model Reasoning
Junchi Wang, Lei Ke
Understanding human instructions to identify the target objects is vital for perception systems. In recent years, the advancements of Large Language Models (LLMs) have introduced new possibilities for image segmentation. In this work, we delve into reasoning segmentation, a novel task that enables segmentation system to reason and interpret implicit user intention via large language model reasoning and then segment the corresponding target. Our work on reasoning segmentation contributes on both the methodological design and dataset labeling. For the model, we propose a new framework named LLM-Seg. LLM-Seg effectively connects the current foundational Segmentation Anything Model and the LLM by mask proposals selection. For the dataset, we propose an automatic data generation pipeline and construct a new reasoning segmentation dataset named LLM-Seg40K. Experiments demonstrate that our LLM-Seg exhibits competitive performance compared with existing methods. Furthermore, our proposed pipeline can efficiently produce high-quality reasoning segmentation datasets. The LLM-Seg40K dataset, developed through this pipeline, serves as a new benchmark for training and evaluating various reasoning segmentation approaches. Our code, models and dataset are at https://github.com/wangjunchi/LLMSeg.
Read more4/16/2024
0
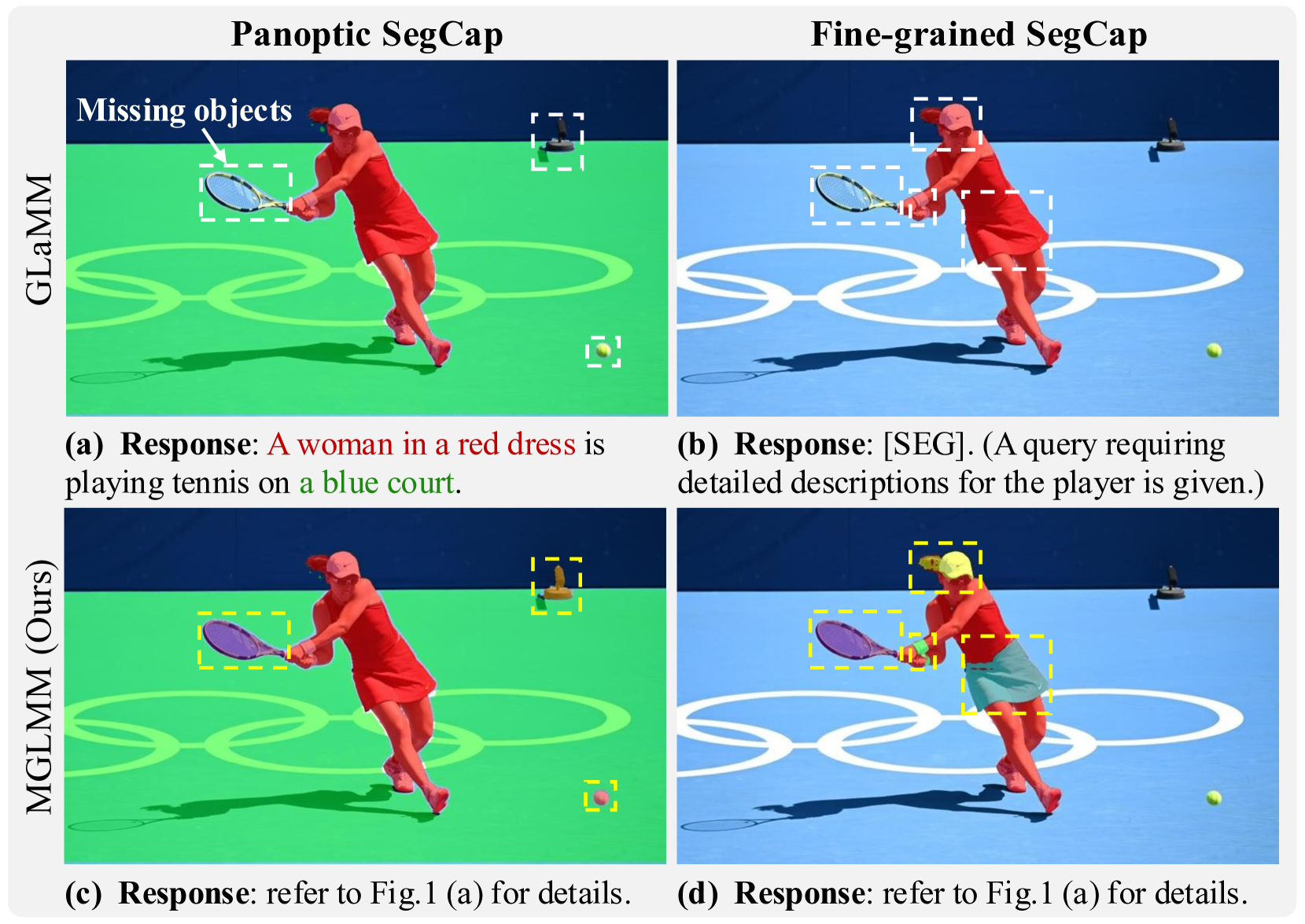
Instruction-guided Multi-Granularity Segmentation and Captioning with Large Multimodal Model
Li Zhou, Xu Yuan, Zenghui Sun, Zikun Zhou, Jingsong Lan
Large Multimodal Models (LMMs) have achieved significant progress by extending large language models. Building on this progress, the latest developments in LMMs demonstrate the ability to generate dense pixel-wise segmentation through the integration of segmentation models.Despite the innovations, the textual responses and segmentation masks of existing works remain at the instance level, showing limited ability to perform fine-grained understanding and segmentation even provided with detailed textual cues.To overcome this limitation, we introduce a Multi-Granularity Large Multimodal Model (MGLMM), which is capable of seamlessly adjusting the granularity of Segmentation and Captioning (SegCap) following user instructions, from panoptic SegCap to fine-grained SegCap. We name such a new task Multi-Granularity Segmentation and Captioning (MGSC). Observing the lack of a benchmark for model training and evaluation over the MGSC task, we establish a benchmark with aligned masks and captions in multi-granularity using our customized automated annotation pipeline. This benchmark comprises 10K images and more than 30K image-question pairs. We will release our dataset along with the implementation of our automated dataset annotation pipeline for further research.Besides, we propose a novel unified SegCap data format to unify heterogeneous segmentation datasets; it effectively facilitates learning to associate object concepts with visual features during multi-task training. Extensive experiments demonstrate that our MGLMM excels at tackling more than eight downstream tasks and achieves state-of-the-art performance in MGSC, GCG, image captioning, referring segmentation, multiple and empty segmentation, and reasoning segmentation tasks. The great performance and versatility of MGLMM underscore its potential impact on advancing multimodal research.
Read more9/23/2024

0
OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding
Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, Shuicheng Yan
Current universal segmentation methods demonstrate strong capabilities in pixel-level image and video understanding. However, they lack reasoning abilities and cannot be controlled via text instructions. In contrast, large vision-language multimodal models exhibit powerful vision-based conversation and reasoning capabilities but lack pixel-level understanding and have difficulty accepting visual prompts for flexible user interaction. This paper proposes OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Specifically, we use a universal segmentation method as the visual encoder, integrating image information, perception priors, and visual prompts into visual tokens provided to the LLM. The LLM is responsible for understanding the user's text instructions and providing text responses and pixel-level segmentation results based on the visual information. We propose perception prior embedding to better integrate perception priors with image features. OMG-LLaVA achieves image-level, object-level, and pixel-level reasoning and understanding in a single model, matching or surpassing the performance of specialized methods on multiple benchmarks. Rather than using LLM to connect each specialist, our work aims at end-to-end training on one encoder, one decoder, and one LLM. The code and model have been released for further research.
Read more6/28/2024