OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
2405.01533
0
0
↗️
Abstract
The advances in multimodal large language models (MLLMs) have led to growing interests in LLM-based autonomous driving agents to leverage their strong reasoning capabilities. However, capitalizing on MLLMs' strong reasoning capabilities for improved planning behavior is challenging since planning requires full 3D situational awareness beyond 2D reasoning. To address this challenge, our work proposes a holistic framework for strong alignment between agent models and 3D driving tasks. Our framework starts with a novel 3D MLLM architecture that uses sparse queries to lift and compress visual representations into 3D before feeding them into an LLM. This query-based representation allows us to jointly encode dynamic objects and static map elements (e.g., traffic lanes), providing a condensed world model for perception-action alignment in 3D. We further propose OmniDrive-nuScenes, a new visual question-answering dataset challenging the true 3D situational awareness of a model with comprehensive visual question-answering (VQA) tasks, including scene description, traffic regulation, 3D grounding, counterfactual reasoning, decision making and planning. Extensive studies show the effectiveness of the proposed architecture as well as the importance of the VQA tasks for reasoning and planning in complex 3D scenes.
Create account to get full access
Overview
- Recent advancements in multimodal large language models (MLLMs) have led to growing interest in using them for autonomous driving agents
- However, leveraging MLLM's strong reasoning capabilities for improved planning behavior is challenging, as planning requires full 3D situational awareness beyond 2D reasoning
- This paper proposes a holistic framework to align MLLM-based agent models with 3D driving tasks
Plain English Explanation
Autonomous driving is a complex challenge that requires cars to navigate the 3D world around them. Recent developments in large language models that can process and understand multiple types of information (called multimodal large language models or MLLMs) have sparked interest in using these models to power autonomous driving agents.
The key advantage of MLLMs is their strong reasoning capabilities, which could help autonomous cars make better decisions. However, translating these reasoning skills into effective planning and navigation in the real 3D world is difficult. Planning for driving requires a full 3D understanding of the vehicle's surroundings, beyond just 2D reasoning.
To address this challenge, the researchers in this paper have developed a new framework that better aligns MLLM-based agent models with the requirements of 3D driving tasks. At the core of their approach is a novel 3D MLLM architecture that can efficiently represent and reason about the 3D environment around the vehicle, including both dynamic objects and static map elements like traffic lanes. This provides the agent with a more comprehensive "world model" to guide its planning and decision-making.
The researchers also created a new dataset called OmniDrive-nuScenes that challenges models to demonstrate true 3D situational awareness through a variety of visual question-answering tasks about the driving scene. Extensive testing shows this dataset is valuable for pushing models to develop stronger 3D reasoning and planning capabilities.
Technical Explanation
The key innovation in this work is a novel 3D MLLM architecture that can effectively represent the full 3D driving environment. It uses sparse queries to "lift" and compress visual information into a 3D format, which is then fed into the language model. This allows the model to jointly encode both dynamic objects and static map elements like traffic lanes, providing a comprehensive world model for aligning perception and action in 3D.
Additionally, the researchers developed the OmniDrive-nuScenes dataset, which presents a variety of visual question-answering tasks that require true 3D situational awareness. This includes challenges like scene description, traffic regulation understanding, 3D grounding, counterfactual reasoning, and planning/decision-making. Extensive experiments demonstrate the effectiveness of the proposed 3D MLLM architecture on this dataset, as well as the importance of these VQA tasks for developing 3D reasoning and planning capabilities in autonomous driving agents.
Critical Analysis
The researchers acknowledge that there are still significant challenges in fully aligning MLLM-based agents with the requirements of 3D driving. While their 3D MLLM architecture represents an important step forward, further advancements may be needed to handle the full complexity and dynamism of real-world driving scenarios.
Additionally, the OmniDrive-nuScenes dataset, while a valuable benchmark, may not capture all the nuances and edge cases that autonomous driving systems will need to handle in the real world. Continued expansion and refinement of such datasets will be crucial for driving progress in this area.
Overall, this work demonstrates promising progress in bridging the gap between MLLM reasoning and 3D driving tasks. However, there is still much work to be done to develop autonomous driving agents with truly robust and reliable 3D planning and decision-making capabilities.
Conclusion
This paper presents a novel framework for aligning MLLM-based agent models with the demands of 3D driving tasks. At the core is a 3D MLLM architecture that can efficiently represent and reason about the full 3D driving environment, and a new benchmark dataset (OmniDrive-nuScenes) that challenges models to demonstrate true 3D situational awareness.
The researchers' work represents an important step forward in leveraging the powerful reasoning capabilities of MLLMs for autonomous driving applications. By improving the alignment between agent models and the 3D world, this research could help pave the way for more capable and reliable self-driving vehicles in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Superalignment Framework in Autonomous Driving with Large Language Models
Xiangrui Kong, Thomas Braunl, Marco Fahmi, Yue Wang
0
0
Over the last year, significant advancements have been made in the realms of large language models (LLMs) and multi-modal large language models (MLLMs), particularly in their application to autonomous driving. These models have showcased remarkable abilities in processing and interacting with complex information. In autonomous driving, LLMs and MLLMs are extensively used, requiring access to sensitive vehicle data such as precise locations, images, and road conditions. These data are transmitted to an LLM-based inference cloud for advanced analysis. However, concerns arise regarding data security, as the protection against data and privacy breaches primarily depends on the LLM's inherent security measures, without additional scrutiny or evaluation of the LLM's inference outputs. Despite its importance, the security aspect of LLMs in autonomous driving remains underexplored. Addressing this gap, our research introduces a novel security framework for autonomous vehicles, utilizing a multi-agent LLM approach. This framework is designed to safeguard sensitive information associated with autonomous vehicles from potential leaks, while also ensuring that LLM outputs adhere to driving regulations and align with human values. It includes mechanisms to filter out irrelevant queries and verify the safety and reliability of LLM outputs. Utilizing this framework, we evaluated the security, privacy, and cost aspects of eleven large language model-driven autonomous driving cues. Additionally, we performed QA tests on these driving prompts, which successfully demonstrated the framework's efficacy.
6/11/2024
👁️
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
0
0
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
6/26/2024
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
0
0
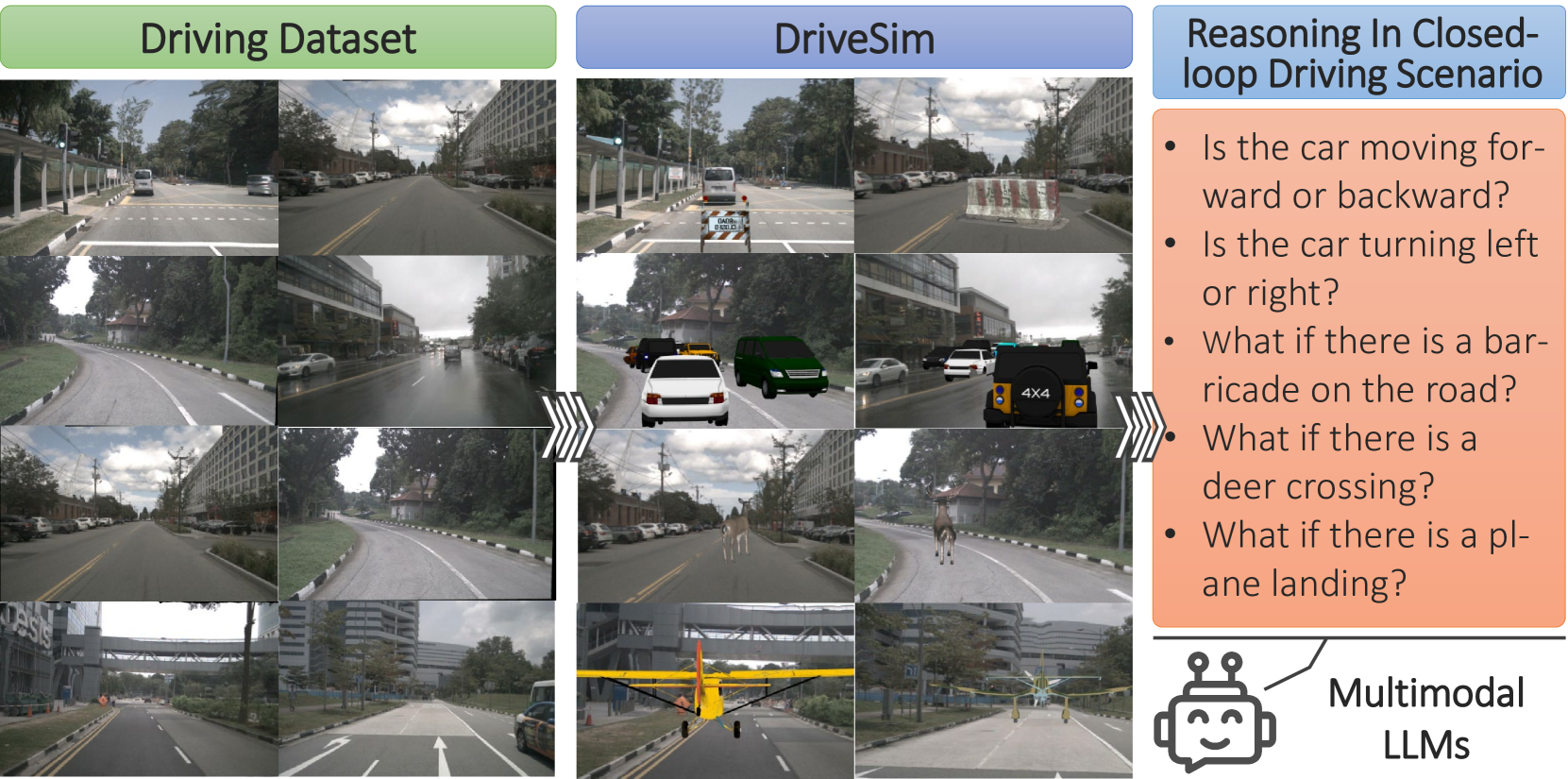
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
5/10/2024

Is a 3D-Tokenized LLM the Key to Reliable Autonomous Driving?
Yifan Bai, Dongming Wu, Yingfei Liu, Fan Jia, Weixin Mao, Ziheng Zhang, Yucheng Zhao, Jianbing Shen, Xing Wei, Tiancai Wang, Xiangyu Zhang
0
0
Rapid advancements in Autonomous Driving (AD) tasks turned a significant shift toward end-to-end fashion, particularly in the utilization of vision-language models (VLMs) that integrate robust logical reasoning and cognitive abilities to enable comprehensive end-to-end planning. However, these VLM-based approaches tend to integrate 2D vision tokenizers and a large language model (LLM) for ego-car planning, which lack 3D geometric priors as a cornerstone of reliable planning. Naturally, this observation raises a critical concern: Can a 2D-tokenized LLM accurately perceive the 3D environment? Our evaluation of current VLM-based methods across 3D object detection, vectorized map construction, and environmental caption suggests that the answer is, unfortunately, NO. In other words, 2D-tokenized LLM fails to provide reliable autonomous driving. In response, we introduce DETR-style 3D perceptrons as 3D tokenizers, which connect LLM with a one-layer linear projector. This simple yet elegant strategy, termed Atlas, harnesses the inherent priors of the 3D physical world, enabling it to simultaneously process high-resolution multi-view images and employ spatiotemporal modeling. Despite its simplicity, Atlas demonstrates superior performance in both 3D detection and ego planning tasks on nuScenes dataset, proving that 3D-tokenized LLM is the key to reliable autonomous driving. The code and datasets will be released.
5/29/2024