Is a 3D-Tokenized LLM the Key to Reliable Autonomous Driving?
2405.18361
0
0

Abstract
Rapid advancements in Autonomous Driving (AD) tasks turned a significant shift toward end-to-end fashion, particularly in the utilization of vision-language models (VLMs) that integrate robust logical reasoning and cognitive abilities to enable comprehensive end-to-end planning. However, these VLM-based approaches tend to integrate 2D vision tokenizers and a large language model (LLM) for ego-car planning, which lack 3D geometric priors as a cornerstone of reliable planning. Naturally, this observation raises a critical concern: Can a 2D-tokenized LLM accurately perceive the 3D environment? Our evaluation of current VLM-based methods across 3D object detection, vectorized map construction, and environmental caption suggests that the answer is, unfortunately, NO. In other words, 2D-tokenized LLM fails to provide reliable autonomous driving. In response, we introduce DETR-style 3D perceptrons as 3D tokenizers, which connect LLM with a one-layer linear projector. This simple yet elegant strategy, termed Atlas, harnesses the inherent priors of the 3D physical world, enabling it to simultaneously process high-resolution multi-view images and employ spatiotemporal modeling. Despite its simplicity, Atlas demonstrates superior performance in both 3D detection and ego planning tasks on nuScenes dataset, proving that 3D-tokenized LLM is the key to reliable autonomous driving. The code and datasets will be released.
Create account to get full access
Overview
• This paper investigates whether a 3D-tokenized large language model (LLM) could be the key to reliable autonomous driving.
• The researchers explore the limitations of 2D-tokenized LLMs in accurately perceiving 3D environments, and propose a 3D-tokenized approach as a potential solution.
• The paper delves into the challenges of grounding language models in 3D spatial understanding, and examines existing work on enhancing multi-modal tokens and developing holistic LLM frameworks for autonomous driving.
Plain English Explanation
Self-driving cars rely on complex AI systems to perceive and understand the 3D world around them. However, most current language models used in these AI systems are trained on 2D data, which may limit their ability to accurately comprehend the 3D environment.
The researchers in this paper explore whether a 3D-tokenized LLM could be a more effective approach for autonomous driving. By representing the world in 3D rather than 2D, the model may be better equipped to understand the depth, scale, and spatial relationships of objects and obstacles, leading to more reliable decision-making for the self-driving car.
The paper examines existing research on grounding language models in 3D understanding, as well as efforts to enhance multi-modal tokens and develop holistic LLM frameworks for autonomous driving applications. [Relevant internal links: Prompting Multi-Modal Tokens to Enhance End-to-End Visual Navigation, OmniDrive: A Holistic LLM Agent Framework for Autonomous Driving, Language-Image Models for 3D Understanding, Grounded 3D LLM with Referent Tokens, When LLMs Step into the 3D World: A Survey]
Technical Explanation
The paper explores the limitations of 2D-tokenized LLMs in accurately perceiving 3D environments, which can be critical for autonomous driving applications. The researchers hypothesize that a 3D-tokenized LLM could be more effective in understanding the depth, scale, and spatial relationships of objects and obstacles in the 3D world.
The paper reviews existing research on enhancing multi-modal tokens and developing holistic LLM frameworks for autonomous driving. For example, Prompting Multi-Modal Tokens to Enhance End-to-End Visual Navigation explores how prompting can be used to imbue language models with a richer understanding of visual and spatial information. OmniDrive: A Holistic LLM Agent Framework for Autonomous Driving proposes a comprehensive LLM-based framework that integrates perception, planning, and control for autonomous driving.
The paper also examines research on Language-Image Models for 3D Understanding and Grounded 3D LLM with Referent Tokens, which explore how language models can be grounded in 3D spatial understanding. Additionally, the authors review the broader landscape of When LLMs Step into the 3D World: A Survey to situate their work in the context of the latest research on 3D-aware language models.
Critical Analysis
The paper raises important questions about the limitations of 2D-tokenized language models in accurately perceiving and understanding 3D environments, which is crucial for the reliability of autonomous driving systems. The researchers make a compelling case for exploring a 3D-tokenized approach as a potential solution.
However, the paper does not provide a detailed implementation or evaluation of the proposed 3D-tokenized LLM approach. It primarily focuses on reviewing existing research and highlighting the potential benefits of this approach, without delving into the practical challenges and technical details of developing and deploying such a system.
Additionally, the paper does not address potential concerns or limitations of the 3D-tokenized LLM approach, such as the potential for increased complexity, computational requirements, or the difficulty of aligning the 3D understanding with other components of an autonomous driving system. Further research and empirical evaluation would be needed to fully assess the feasibility and effectiveness of this approach.
Conclusion
This paper explores the idea of using a 3D-tokenized LLM as a potential solution to the limitations of 2D-tokenized models in accurately perceiving and understanding 3D environments, which is crucial for reliable autonomous driving. The researchers review existing research on enhancing multi-modal tokens, developing holistic LLM frameworks, and grounding language models in 3D spatial understanding.
While the paper makes a compelling case for the potential benefits of a 3D-tokenized LLM approach, it does not provide a detailed implementation or evaluation of this solution. Further research and empirical validation would be needed to fully assess the feasibility and effectiveness of this approach in improving the reliability and safety of autonomous driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
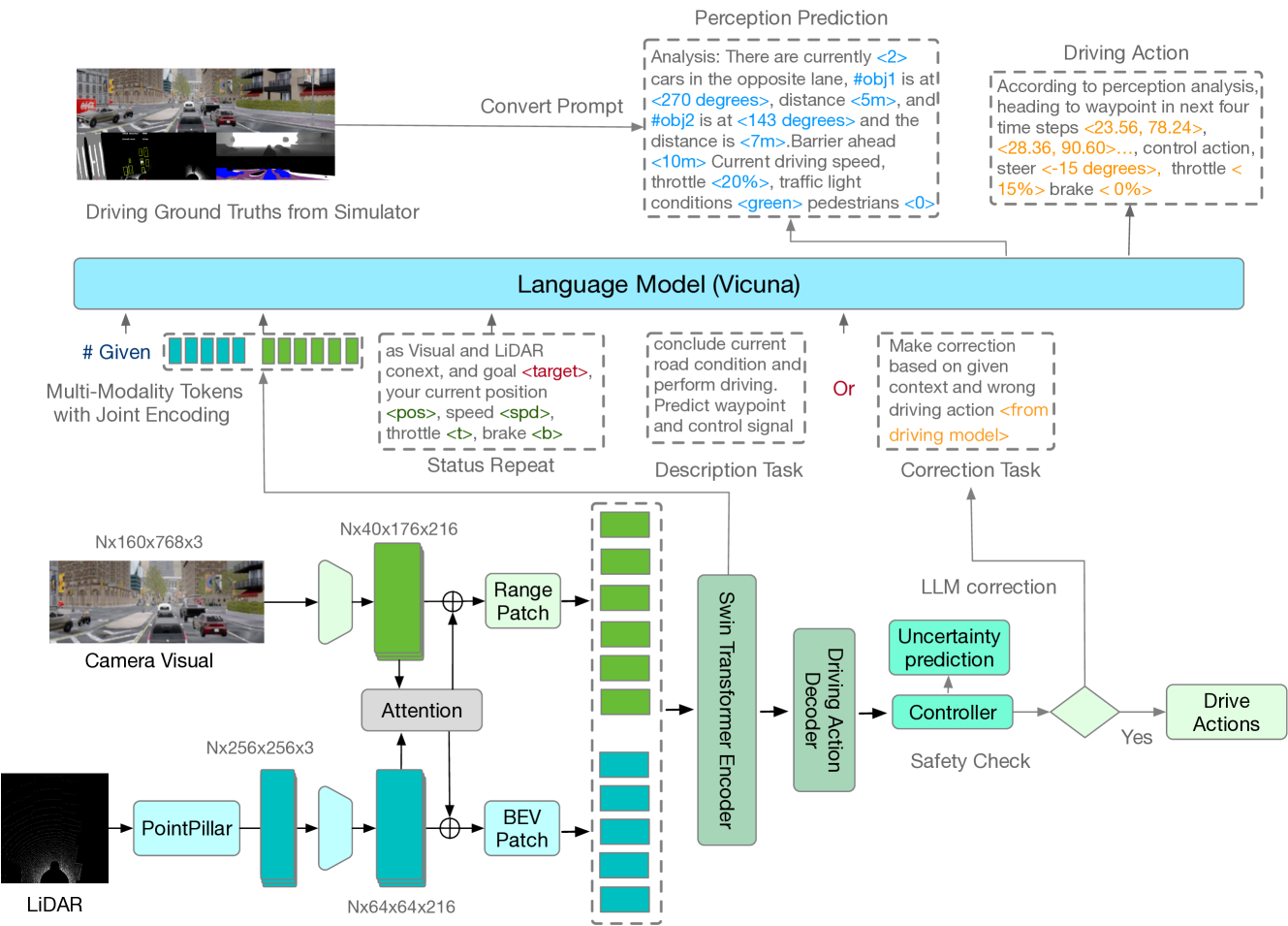
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
Yiqun Duan, Qiang Zhang, Renjing Xu
0
0
The utilization of Large Language Models (LLMs) within the realm of reinforcement learning, particularly as planners, has garnered a significant degree of attention in recent scholarly literature. However, a substantial proportion of existing research predominantly focuses on planning models for robotics that transmute the outputs derived from perception models into linguistic forms, thus adopting a `pure-language' strategy. In this research, we propose a hybrid End-to-End learning framework for autonomous driving by combining basic driving imitation learning with LLMs based on multi-modality prompt tokens. Instead of simply converting perception results from the separated train model into pure language input, our novelty lies in two aspects. 1) The end-to-end integration of visual and LiDAR sensory input into learnable multi-modality tokens, thereby intrinsically alleviating description bias by separated pre-trained perception models. 2) Instead of directly letting LLMs drive, this paper explores a hybrid setting of letting LLMs help the driving model correct mistakes and complicated scenarios. The results of our experiments suggest that the proposed methodology can attain driving scores of 49.21%, coupled with an impressive route completion rate of 91.34% in the offline evaluation conducted via CARLA. These performance metrics are comparable to the most advanced driving models.
4/9/2024
↗️
OmniDrive: A Holistic LLM-Agent Framework for Autonomous Driving with 3D Perception, Reasoning and Planning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, Jose M. Alvarez
0
0
The advances in multimodal large language models (MLLMs) have led to growing interests in LLM-based autonomous driving agents to leverage their strong reasoning capabilities. However, capitalizing on MLLMs' strong reasoning capabilities for improved planning behavior is challenging since planning requires full 3D situational awareness beyond 2D reasoning. To address this challenge, our work proposes a holistic framework for strong alignment between agent models and 3D driving tasks. Our framework starts with a novel 3D MLLM architecture that uses sparse queries to lift and compress visual representations into 3D before feeding them into an LLM. This query-based representation allows us to jointly encode dynamic objects and static map elements (e.g., traffic lanes), providing a condensed world model for perception-action alignment in 3D. We further propose OmniDrive-nuScenes, a new visual question-answering dataset challenging the true 3D situational awareness of a model with comprehensive visual question-answering (VQA) tasks, including scene description, traffic regulation, 3D grounding, counterfactual reasoning, decision making and planning. Extensive studies show the effectiveness of the proposed architecture as well as the importance of the VQA tasks for reasoning and planning in complex 3D scenes.
5/3/2024
A Superalignment Framework in Autonomous Driving with Large Language Models
Xiangrui Kong, Thomas Braunl, Marco Fahmi, Yue Wang
0
0
Over the last year, significant advancements have been made in the realms of large language models (LLMs) and multi-modal large language models (MLLMs), particularly in their application to autonomous driving. These models have showcased remarkable abilities in processing and interacting with complex information. In autonomous driving, LLMs and MLLMs are extensively used, requiring access to sensitive vehicle data such as precise locations, images, and road conditions. These data are transmitted to an LLM-based inference cloud for advanced analysis. However, concerns arise regarding data security, as the protection against data and privacy breaches primarily depends on the LLM's inherent security measures, without additional scrutiny or evaluation of the LLM's inference outputs. Despite its importance, the security aspect of LLMs in autonomous driving remains underexplored. Addressing this gap, our research introduces a novel security framework for autonomous vehicles, utilizing a multi-agent LLM approach. This framework is designed to safeguard sensitive information associated with autonomous vehicles from potential leaks, while also ensuring that LLM outputs adhere to driving regulations and align with human values. It includes mechanisms to filter out irrelevant queries and verify the safety and reliability of LLM outputs. Utilizing this framework, we evaluated the security, privacy, and cost aspects of eleven large language model-driven autonomous driving cues. Additionally, we performed QA tests on these driving prompts, which successfully demonstrated the framework's efficacy.
6/11/2024
👁️
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
0
0
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
6/26/2024