One for All: Toward Unified Foundation Models for Earth Vision
2401.07527
0
0

Abstract
Foundation models characterized by extensive parameters and trained on large-scale datasets have demonstrated remarkable efficacy across various downstream tasks for remote sensing data. Current remote sensing foundation models typically specialize in a single modality or a specific spatial resolution range, limiting their versatility for downstream datasets. While there have been attempts to develop multi-modal remote sensing foundation models, they typically employ separate vision encoders for each modality or spatial resolution, necessitating a switch in backbones contingent upon the input data. To address this issue, we introduce a simple yet effective method, termed OFA-Net (One-For-All Network): employing a single, shared Transformer backbone for multiple data modalities with different spatial resolutions. Using the masked image modeling mechanism, we pre-train a single Transformer backbone on a curated multi-modal dataset with this simple design. Then the backbone model can be used in different downstream tasks, thus forging a path towards a unified foundation backbone model in Earth vision. The proposed method is evaluated on 12 distinct downstream tasks and demonstrates promising performance.
Create account to get full access
Overview
- The paper proposes a unified approach to developing Foundation Models for Earth vision tasks, which can encompass a wide range of applications such as remote sensing, ophthalmology, and multi-modal re-identification.
- The key idea is to construct large-scale, multi-modal datasets that can serve as the foundation for these models, allowing them to learn general representations that can be adapted to various downstream tasks.
- The paper covers the methodology for dataset construction, model architecture, and evaluation on several benchmark tasks, demonstrating the potential of this unified approach.
Plain English Explanation
The paper is about a new way to develop AI models that can be used for a wide variety of tasks related to understanding the Earth, such as analyzing satellite images, medical imaging of the eye, and tracking people in different settings. The key idea is to build very large datasets that include different types of data, like images, text, and other information, and then use these datasets to train foundation models that can learn general representations. These foundation models can then be adapted to work on specific tasks, like identifying eye conditions or tracking people in crowded scenes.
The researchers explain how they built these large, multi-modal datasets and designed the model architecture to take advantage of the diverse information. They then show that these unified foundation models can perform well on a variety of benchmark tasks, suggesting that this approach could be very useful for developing AI systems that can handle many different real-world applications related to understanding the Earth.
Technical Explanation
The paper proposes a methodology for constructing large-scale, multi-modal datasets to serve as the foundation for developing unified Foundation Models for Earth vision tasks. The key idea is to bring together diverse data sources, such as satellite imagery, ground-level photos, text descriptions, and sensor measurements, to create comprehensive datasets that can capture the complexity of the real world.
The authors describe a dataset construction process that involves carefully curating and aligning data from multiple modalities, handling challenges like missing data and cross-modal correspondence. They also discuss the model architecture, which leverages self-supervised learning and multi-modal fusion to learn general representations that can be adapted to a wide range of downstream tasks, such as remote sensing, ophthalmology, and multi-modal person re-identification.
Through extensive experiments, the authors demonstrate the effectiveness of their unified approach, showing that the foundation models can achieve strong performance on a variety of benchmark tasks while also exhibiting promising transfer learning capabilities.
Critical Analysis
The paper presents a compelling vision for developing more general and adaptable AI systems for Earth-related applications. By constructing large-scale, multi-modal datasets and training unified foundation models, the researchers aim to overcome the limitations of more specialized or narrow-focused models.
However, the paper does not thoroughly address some potential challenges and limitations of this approach. For example, the authors do not discuss the scalability and computational requirements of training and deploying these large-scale foundation models, which could be a significant practical concern. Additionally, the paper does not explore the potential biases and ethical implications of using such broad-reaching models in sensitive domains like healthcare and public safety.
Further research is needed to fully understand the trade-offs and real-world implications of the proposed unified approach. Exploring techniques for improving the interpretability and robustness of these foundation models, as well as investigating their fairness and accountability, could be valuable areas for future work.
Conclusion
The paper presents a promising direction for developing more versatile and adaptable AI systems for a wide range of Earth-related applications. By constructing large-scale, multi-modal datasets and training unified foundation models, the researchers aim to enable more general and transferable representations that can be leveraged across diverse tasks, from remote sensing to ophthalmology to multi-modal person re-identification.
The potential of this unified approach, if realized, could lead to more efficient and versatile AI systems that can better understand and model the complex and interconnected systems that shape our planet. However, further research is needed to address the practical and ethical challenges that come with developing such broad-reaching AI models. Nonetheless, the ideas presented in this paper represent an important step towards a more holistic and impactful vision for Earth-centric AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Neural Plasticity-Inspired Multimodal Foundation Model for Earth Observation
Zhitong Xiong, Yi Wang, Fahong Zhang, Adam J. Stewart, Joelle Hanna, Damian Borth, Ioannis Papoutsis, Bertrand Le Saux, Gustau Camps-Valls, Xiao Xiang Zhu
0
0
The development of foundation models has revolutionized our ability to interpret the Earth's surface using satellite observational data. Traditional models have been siloed, tailored to specific sensors or data types like optical, radar, and hyperspectral, each with its own unique characteristics. This specialization hinders the potential for a holistic analysis that could benefit from the combined strengths of these diverse data sources. Our novel approach introduces the Dynamic One-For-All (DOFA) model, leveraging the concept of neural plasticity in brain science to integrate various data modalities into a single framework adaptively. This dynamic hypernetwork, adjusting to different wavelengths, enables a single versatile Transformer jointly trained on data from five sensors to excel across 12 distinct Earth observation tasks, including sensors never seen during pretraining. DOFA's innovative design offers a promising leap towards more accurate, efficient, and unified Earth observation analysis, showcasing remarkable adaptability and performance in harnessing the potential of multimodal Earth observation data.
6/10/2024
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Yiqun Xie, Zhihao Wang, Weiye Chen, Zhili Li, Xiaowei Jia, Yanhua Li, Ruichen Wang, Kangyang Chai, Ruohan Li, Sergii Skakun
0
0
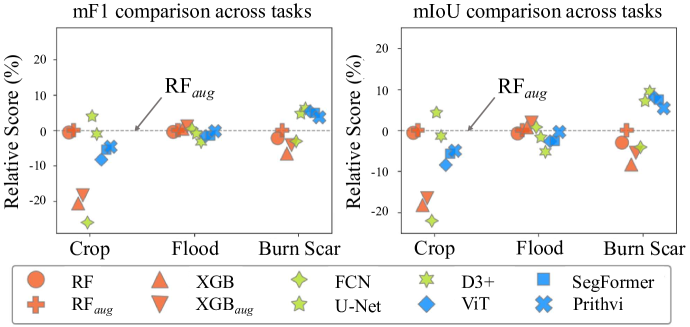
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
4/19/2024
📈
A Billion-scale Foundation Model for Remote Sensing Images
Keumgang Cha, Junghoon Seo, Taekyung Lee
0
0
As the potential of foundation models in visual tasks has garnered significant attention, pretraining these models before downstream tasks has become a crucial step. The three key factors in pretraining foundation models are the pretraining method, the size of the pretraining dataset, and the number of model parameters. Recently, research in the remote sensing field has focused primarily on the pretraining method and the size of the dataset, with limited emphasis on the number of model parameters. This paper addresses this gap by examining the effect of increasing the number of model parameters on the performance of foundation models in downstream tasks such as rotated object detection and semantic segmentation. We pretrained foundation models with varying numbers of parameters, including 86M, 605.26M, 1.3B, and 2.4B, to determine whether performance in downstream tasks improved with an increase in parameters. To the best of our knowledge, this is the first billion-scale foundation model in the remote sensing field. Furthermore, we propose an effective method for scaling up and fine-tuning a vision transformer in the remote sensing field. To evaluate general performance in downstream tasks, we employed the DOTA v2.0 and DIOR-R benchmark datasets for rotated object detection, and the Potsdam and LoveDA datasets for semantic segmentation. Experimental results demonstrated that, across all benchmark datasets and downstream tasks, the performance of the foundation models and data efficiency improved as the number of parameters increased. Moreover, our models achieve the state-of-the-art performance on several datasets including DIOR-R, Postdam, and LoveDA.
5/15/2024
📈
EyeFound: A Multimodal Generalist Foundation Model for Ophthalmic Imaging
Danli Shi, Weiyi Zhang, Xiaolan Chen, Yexin Liu, Jiancheng Yang, Siyu Huang, Yih Chung Tham, Yingfeng Zheng, Mingguang He
0
0
Artificial intelligence (AI) is vital in ophthalmology, tackling tasks like diagnosis, classification, and visual question answering (VQA). However, existing AI models in this domain often require extensive annotation and are task-specific, limiting their clinical utility. While recent developments have brought about foundation models for ophthalmology, they are limited by the need to train separate weights for each imaging modality, preventing a comprehensive representation of multi-modal features. This highlights the need for versatile foundation models capable of handling various tasks and modalities in ophthalmology. To address this gap, we present EyeFound, a multimodal foundation model for ophthalmic images. Unlike existing models, EyeFound learns generalizable representations from unlabeled multimodal retinal images, enabling efficient model adaptation across multiple applications. Trained on 2.78 million images from 227 hospitals across 11 ophthalmic modalities, EyeFound facilitates generalist representations and diverse multimodal downstream tasks, even for detecting challenging rare diseases. It outperforms previous work RETFound in diagnosing eye diseases, predicting systemic disease incidents, and zero-shot multimodal VQA. EyeFound provides a generalizable solution to improve model performance and lessen the annotation burden on experts, facilitating widespread clinical AI applications for retinal imaging.
5/24/2024