One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion

0

Sign in to get full access
Overview
- The paper presents a method for training a single neural network policy that can control the locomotion of various embodiments, such as different types of legged robots.
- The key idea is to use an end-to-end learning approach that directly maps sensory inputs to motor commands, without relying on manual engineering or separate control modules.
- The trained policy is shown to generalize across a diverse set of embodiments, enabling versatile and adaptable locomotion control.
Plain English Explanation
The researchers developed a machine learning system that can control the walking and running motions of different kinds of legged robots. Typically, each robot would require its own specialized control algorithm, but this new approach uses a single neural network policy that can adapt to work with various robot embodiments.
The key is that the neural network is trained in an "end-to-end" way, meaning it directly maps the sensor inputs from the robot (like cameras and joint positions) to the motor commands needed to make it move, without any intermediate steps or hand-engineered components. This allows the policy to learn a general, adaptable control strategy that can be applied to different robots.
The researchers show that this single trained policy can successfully control the locomotion of a diverse set of embodiments, from quadrupeds to humanoids, demonstrating the versatility and potential of this approach.
Technical Explanation
The paper presents an end-to-end learning method for training a single neural network policy that can control the locomotion of various robot embodiments. The key idea is to directly map the robot's sensory inputs (e.g., camera images, joint positions) to the required motor commands, without relying on any manually engineered control modules or intermediate representations.
The authors train this policy using reinforcement learning, where the agent learns to maximize a reward signal corresponding to efficient and stable locomotion. Crucially, the training is performed across a diverse set of simulated robot embodiments, including quadrupeds, humanoids, and other legged designs.
The trained policy is then evaluated on its ability to control the locomotion of these different embodiments, without any fine-tuning or adaptation. The results show that the single policy can successfully adapt to and control the diverse set of robots, demonstrating the versatility and generalization capabilities of the proposed approach.
Critical Analysis
The paper presents a promising approach to multi-embodiment locomotion control that could have significant implications for the development of versatile and adaptive robotic systems. By training a single neural network policy to handle a variety of embodiments, the authors have demonstrated the potential for scalable and transferable control strategies.
However, the paper does not address the potential limitations or challenges of this approach. For example, it is unclear how the policy would perform on real-world robots, which may have additional complexities and uncertainties not captured in the simulated environments. Additionally, the paper does not discuss the training time and computational requirements, which could be a practical concern for deploying such a system in real-world applications.
Further research is needed to explore the robustness and generalization of the trained policy across a wider range of embodiments, environmental conditions, and real-world scenarios. Investigating the interpretability and transparency of the learned control strategies could also provide valuable insights for practical deployment and trust in the system.
Conclusion
The one-policy-to-rule-them-all approach presented in this paper represents an exciting step towards versatile and adaptable locomotion control for robotic systems. By training a single neural network policy to handle a diverse range of embodiments, the researchers have demonstrated the potential for [scalable and transferable control strategies](https://aimodels.fyi/papers/arxiv/scaling-cross-embodi ed-learning-one-policy-manipulation) that could enable more mobile and adaptable robotic platforms. Further research is needed to address the practical limitations and expand the capabilities of this approach, but the findings presented in this paper suggest a promising future for multi-purpose robotic locomotion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
Nico Bohlinger, Grzegorz Czechmanowski, Maciej Krupka, Piotr Kicki, Krzysztof Walas, Jan Peters, Davide Tateo
Deep Reinforcement Learning techniques are achieving state-of-the-art results in robust legged locomotion. While there exists a wide variety of legged platforms such as quadruped, humanoids, and hexapods, the field is still missing a single learning framework that can control all these different embodiments easily and effectively and possibly transfer, zero or few-shot, to unseen robot embodiments. We introduce URMA, the Unified Robot Morphology Architecture, to close this gap. Our framework brings the end-to-end Multi-Task Reinforcement Learning approach to the realm of legged robots, enabling the learned policy to control any type of robot morphology. The key idea of our method is to allow the network to learn an abstract locomotion controller that can be seamlessly shared between embodiments thanks to our morphology-agnostic encoders and decoders. This flexible architecture can be seen as a potential first step in building a foundation model for legged robot locomotion. Our experiments show that URMA can learn a locomotion policy on multiple embodiments that can be easily transferred to unseen robot platforms in simulation and the real world.
Read more9/11/2024
🏅
0
Meta-Reinforcement Learning for Universal Quadrupedal Locomotion Control
Fabrizio Di Giuro, Fatemeh Zargarbashi, Jin Cheng, Dongho Kang, Bhavya Sukhija, Stelian Coros
This work presents a deep reinforcement learning-based approach to develop a policy for robot-agnostic locomotion control. Our method involves training an agent equipped with memory, implemented as a recurrent policy, on a diverse set of procedurally generated quadruped robots. We demonstrate that the policies trained by our framework transfer seamlessly to both simulated and real-world quadrupeds not encountered during training, maintaining high-quality motion across platforms. Through a series of simulation and hardware experiments, we highlight the critical role of the recurrent unit in enabling generalization, rapid adaptation to changes in the robot's dynamic properties, and sample efficiency.
Read more7/26/2024

0
Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation
Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, Sergey Levine
Modern machine learning systems rely on large datasets to attain broad generalization, and this often poses a challenge in robot learning, where each robotic platform and task might have only a small dataset. By training a single policy across many different kinds of robots, a robot learning method can leverage much broader and more diverse datasets, which in turn can lead to better generalization and robustness. However, training a single policy on multi-robot data is challenging because robots can have widely varying sensors, actuators, and control frequencies. We propose CrossFormer, a scalable and flexible transformer-based policy that can consume data from any embodiment. We train CrossFormer on the largest and most diverse dataset to date, 900K trajectories across 20 different robot embodiments. We demonstrate that the same network weights can control vastly different robots, including single and dual arm manipulation systems, wheeled robots, quadcopters, and quadrupeds. Unlike prior work, our model does not require manual alignment of the observation or action spaces. Extensive experiments in the real world show that our method matches the performance of specialist policies tailored for each embodiment, while also significantly outperforming the prior state of the art in cross-embodiment learning.
Read more8/22/2024
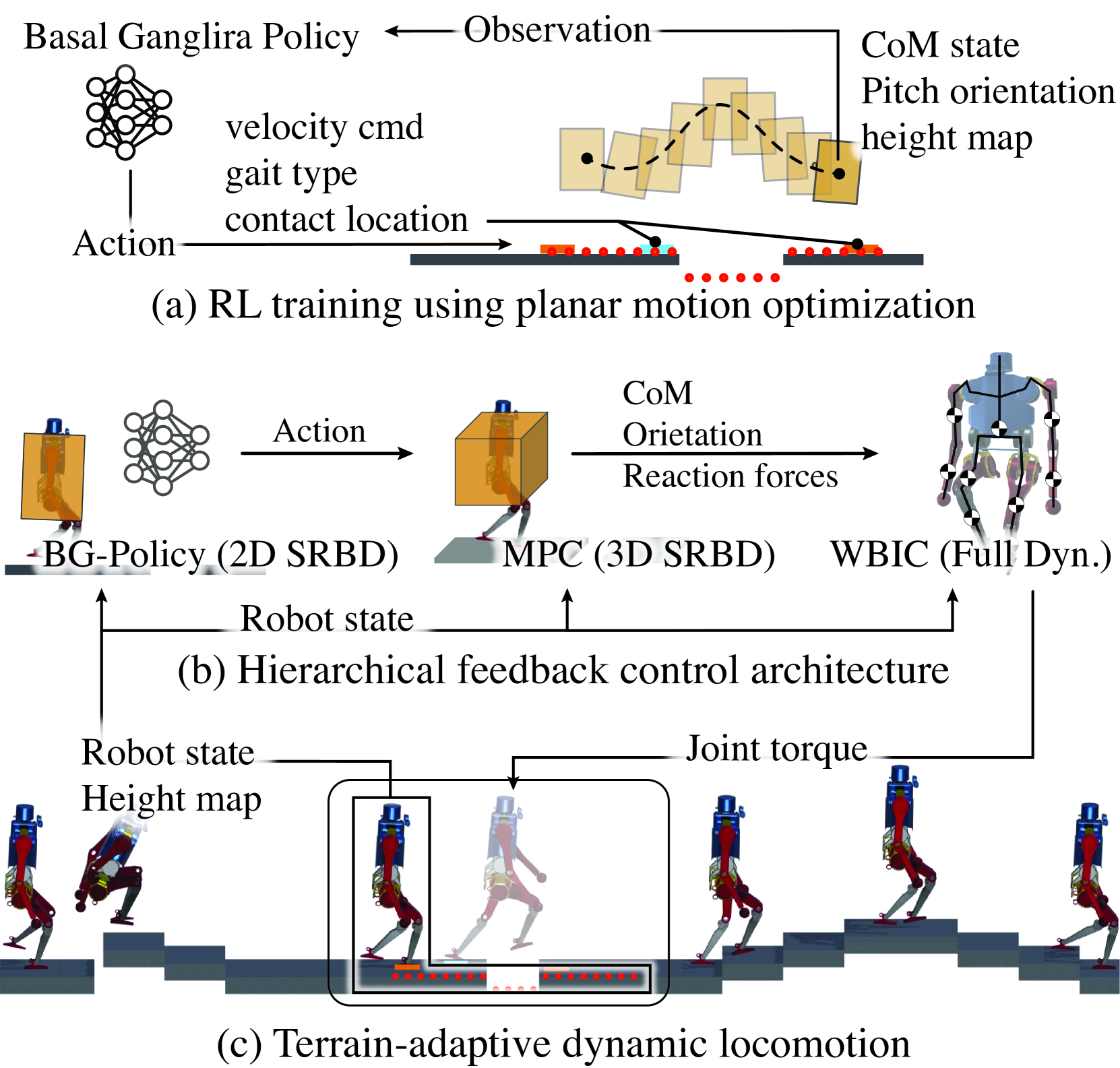
0
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
Shangqun Yu, Nisal Perera, Daniel Marew, Donghyun Kim
This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
Read more7/30/2024