Online Bandit Learning with Offline Preference Data
2406.09574
0
0

Abstract
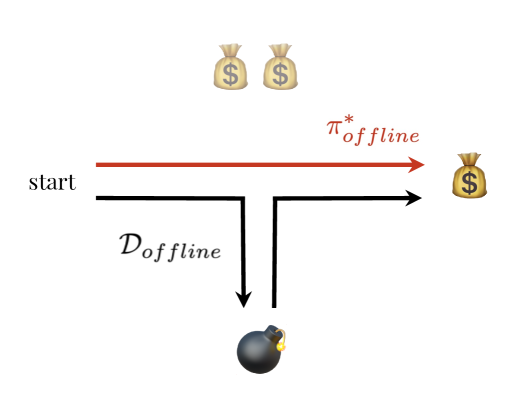
Reinforcement Learning with Human Feedback (RLHF) is at the core of fine-tuning methods for generative AI models for language and images. Such feedback is often sought as rank or preference feedback from human raters, as opposed to eliciting scores since the latter tends to be very noisy. On the other hand, RL theory and algorithms predominantly assume that a reward feedback is available. In particular, approaches for online learning that can be helpful in adaptive data collection via active learning cannot incorporate offline preference data. In this paper, we adopt a finite-armed linear bandit model as a prototypical model of online learning. We consider an offline preference dataset to be available generated by an expert of unknown 'competence'. We propose $texttt{warmPref-PS}$, a posterior sampling algorithm for online learning that can be warm-started with an offline dataset with noisy preference feedback. We show that by modeling the competence of the expert that generated it, we are able to use such a dataset most effectively. We support our claims with novel theoretical analysis of its Bayesian regret, as well as extensive empirical evaluation of an approximate algorithm which performs substantially better (almost 25 to 50% regret reduction in our studies) as compared to baselines.
Create account to get full access
Overview
- This paper introduces a new algorithm called Preference-Warmed Posterior Sampling (PWPS) for online bandit learning with offline preference data.
- The key idea is to leverage offline preference data to warm the posterior distribution of the bandit's parameters, leading to faster learning and improved performance.
- The authors demonstrate the effectiveness of PWPS on several benchmark problems and compare it to state-of-the-art bandit algorithms.
Plain English Explanation
The paper addresses the challenge of online bandit learning, where a system needs to make a series of decisions (e.g., which product to recommend to a user) and learn from the feedback it receives. Traditionally, these systems have been trained using data on the outcomes of past decisions. However, in many real-world scenarios, the available data may be in the form of preferences (e.g., users' rankings of products) rather than direct outcome information.
The authors' proposed algorithm, Preference-Warmed Posterior Sampling (PWPS), tackles this problem by using the offline preference data to "warm" the system's understanding of the underlying parameters that govern the bandit problem. This allows the system to start with a more informed prior, leading to faster learning and better performance in the online setting.
To illustrate, imagine you're building a recommender system for an e-commerce site. You have historical data on how users ranked different products, but not on which products they actually purchased. PWPS would use this preference data to initialize the system's beliefs about which products are likely to be popular, allowing it to make better recommendations right from the start, and learn more quickly as it gathers new feedback.
By incorporating offline preference data in this way, PWPS represents an advance over traditional bandit algorithms that rely solely on direct outcome data. The authors demonstrate its effectiveness on several benchmark problems, showing that it can outperform state-of-the-art approaches.
Technical Explanation
The authors consider the contextual bandit setting, where the system receives some context (e.g., information about the user or the current situation) and must choose an action (e.g., which product to recommend) from a set of available options. The goal is to maximize the expected reward (e.g., user satisfaction or sales) over time.
Traditionally, contextual bandit algorithms have been trained using direct outcome data, where the system observes the reward associated with each action it takes. However, in many real-world scenarios, the available data may be in the form of preference data, where the system only knows the relative rankings of different actions, but not their exact rewards.
To address this, the authors propose the Preference-Warmed Posterior Sampling (PWPS) algorithm. PWPS leverages the offline preference data to "warm" the system's posterior distribution over the underlying parameters that govern the bandit problem. This allows the system to start with a more informed prior, leading to faster learning and better performance in the online setting.
Specifically, PWPS works as follows:
- The system first learns a model of the preference data using techniques from contrastive preference learning.
- It then uses this preference model to initialize the posterior distribution over the bandit's parameters, before starting the online learning process.
- During the online phase, PWPS uses posterior sampling to select actions, updating the posterior distribution after each interaction.
The authors demonstrate the effectiveness of PWPS on several benchmark problems, including contextual bandits with real-world datasets and synthetic data. They show that PWPS can outperform state-of-the-art bandit algorithms, such as TS-UCB and Value-Incentivized Preference Optimization (VIPO), in terms of cumulative reward and other performance metrics.
Critical Analysis
The paper provides a novel and well-designed approach to incorporating offline preference data into online bandit learning. The authors' key contribution is the Preference-Warmed Posterior Sampling (PWPS) algorithm, which effectively leverages the preference data to warm the system's prior beliefs and accelerate learning.
One potential limitation of the approach is that it relies on the assumption that the preference data is representative of the true reward distribution. If the preferences do not align well with the actual rewards, the warmed prior may lead to suboptimal performance. The authors acknowledge this and suggest that further research is needed to understand the impact of data quality and distribution mismatch on PWPS's performance.
Additionally, the paper focuses on the contextual bandit setting, but many real-world applications may involve more complex decision-making scenarios, such as reinforcement learning or preference learning from interactive feedback. It would be interesting to see how the PWPS approach could be extended to these more general settings.
Overall, the paper presents a promising new direction for leveraging offline preference data to enhance online decision-making. The authors' RLHF workflow demonstrates the potential for this type of approach to improve the performance and sample efficiency of AI systems that interact with humans.
Conclusion
The paper introduces the Preference-Warmed Posterior Sampling (PWPS) algorithm, which effectively incorporates offline preference data into online bandit learning. By using the preference data to warm the system's prior beliefs, PWPS is able to achieve faster learning and better performance compared to traditional bandit algorithms that rely solely on direct outcome data.
The authors' work represents an important step forward in leveraging diverse sources of feedback to train more capable and sample-efficient AI systems. As AI systems become more pervasive in our lives, techniques like PWPS that can learn effectively from limited data will be crucial for developing AI that is safe, reliable, and aligned with human preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
0
0
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
6/27/2024
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024
🏅
Online Iterative Reinforcement Learning from Human Feedback with General Preference Model
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
0
0
We study Reinforcement Learning from Human Feedback (RLHF) under a general preference oracle. In particular, we do not assume that there exists a reward function and the preference signal is drawn from the Bradley-Terry model as most of the prior works do. We consider a standard mathematical formulation, the reverse-KL regularized minimax game between two LLMs for RLHF under general preference oracle. The learning objective of this formulation is to find a policy so that it is consistently preferred by the KL-regularized preference oracle over any competing LLMs. We show that this framework is strictly more general than the reward-based one, and propose sample-efficient algorithms for both the offline learning from a pre-collected preference dataset and online learning where we can query the preference oracle along the way of training. Empirical studies verify the effectiveness of the proposed framework.
4/26/2024
📶
Contrastive Preference Learning: Learning from Human Feedback without RL
Joey Hejna, Rafael Rafailov, Harshit Sikchi, Chelsea Finn, Scott Niekum, W. Bradley Knox, Dorsa Sadigh
0
0
Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular paradigm for aligning models with human intent. Typically RLHF algorithms operate in two phases: first, use human preferences to learn a reward function and second, align the model by optimizing the learned reward via reinforcement learning (RL). This paradigm assumes that human preferences are distributed according to reward, but recent work suggests that they instead follow the regret under the user's optimal policy. Thus, learning a reward function from feedback is not only based on a flawed assumption of human preference, but also leads to unwieldy optimization challenges that stem from policy gradients or bootstrapping in the RL phase. Because of these optimization challenges, contemporary RLHF methods restrict themselves to contextual bandit settings (e.g., as in large language models) or limit observation dimensionality (e.g., state-based robotics). We overcome these limitations by introducing a new family of algorithms for optimizing behavior from human feedback using the regret-based model of human preferences. Using the principle of maximum entropy, we derive Contrastive Preference Learning (CPL), an algorithm for learning optimal policies from preferences without learning reward functions, circumventing the need for RL. CPL is fully off-policy, uses only a simple contrastive objective, and can be applied to arbitrary MDPs. This enables CPL to elegantly scale to high-dimensional and sequential RLHF problems while being simpler than prior methods.
5/1/2024