Online Residual Learning from Offline Experts for Pedestrian Tracking

0
Sign in to get full access
Overview
- The provided research paper discusses an approach for online residual learning from offline experts for pedestrian tracking.
- It aims to leverage the knowledge from pre-trained offline models to improve online tracking performance.
- The proposed method involves a novel residual learning framework that allows online models to adaptively learn from offline experts.
Plain English Explanation
The research paper presents a new way to improve real-time pedestrian tracking systems by incorporating knowledge from pre-trained "expert" models. Pedestrian tracking is an important task in computer vision, with applications in areas like surveillance, self-driving cars, and robotics.
Traditionally, online tracking models are trained solely on live data, which can be limited and may not capture the full complexity of real-world scenarios. The key insight of this paper is that we can leverage the knowledge learned by "offline" expert models that have been trained on larger, more diverse datasets.
The paper introduces a residual learning framework that allows the online tracking model to adaptively learn from the offline experts. Rather than simply using the offline model's outputs, the online model learns to predict the "residual" or difference between the offline predictions and the true target locations. This residual learning approach enables the online model to selectively incorporate the relevant knowledge from the offline experts, while also adapting to the unique characteristics of the current live data stream.
The authors demonstrate through experiments that this hybrid approach, which combines online and offline learning, can significantly improve the accuracy and robustness of real-time pedestrian tracking compared to using only online or offline models alone.
Technical Explanation
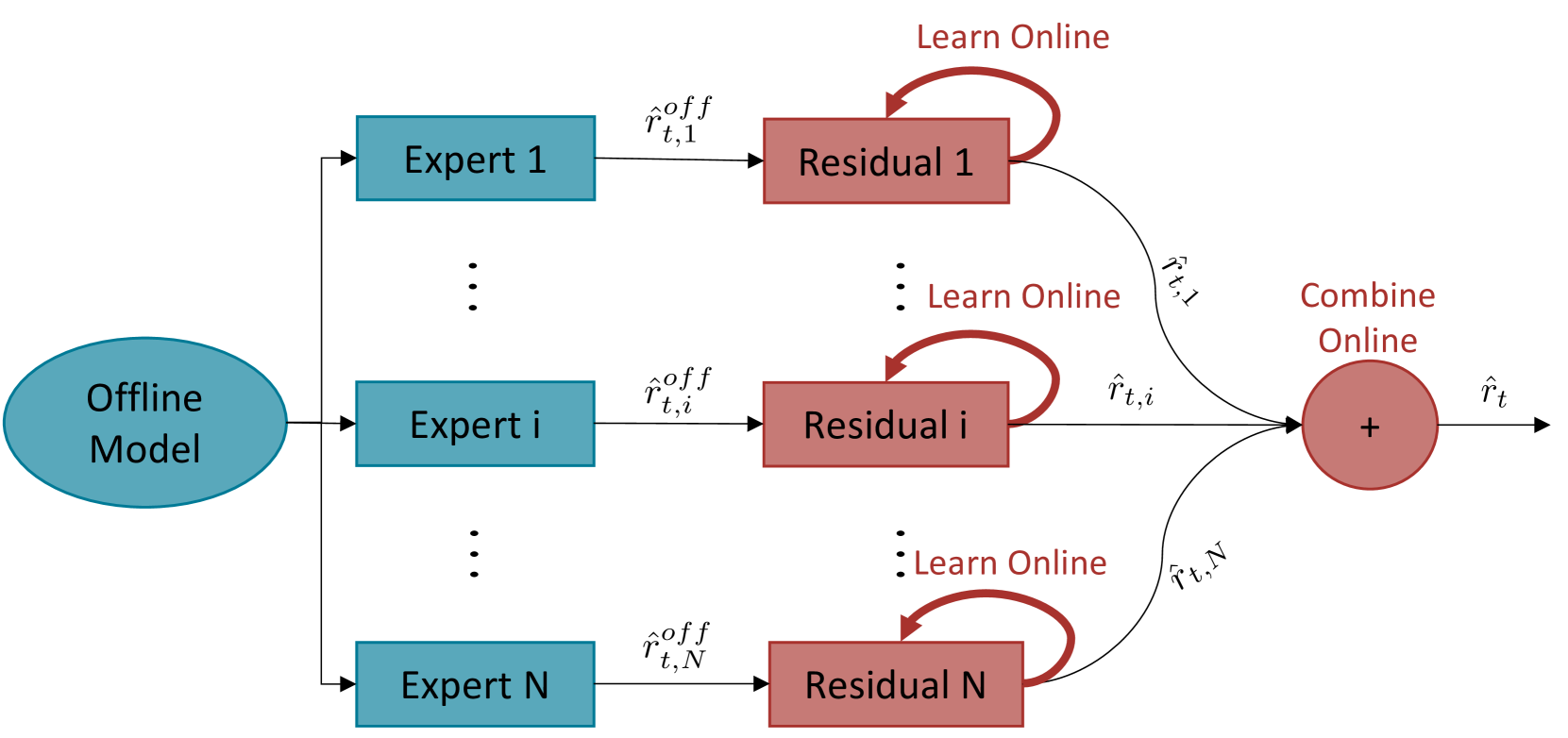
The paper introduces an Online Residual Learning (ORL) framework for pedestrian tracking that leverages pre-trained Offline Experts (OEs). The key components are:
-
Offline Experts: These are pre-trained deep neural network models that have been trained on large, diverse datasets to perform pedestrian tracking. They serve as a source of rich, general knowledge about pedestrian behavior and appearance.
-
Online Residual Learning: The online tracking model learns to predict the "residual" or difference between the OE's predictions and the true target locations. This allows the online model to selectively incorporate the relevant knowledge from the OEs while also adapting to the characteristics of the current live data.
-
Adaptive Combination: The online model dynamically adjusts the weight given to the OE's outputs based on their current performance on the live data. This helps the online model to optimally leverage the OEs throughout the tracking process.
The authors evaluate their ORL framework on several pedestrian tracking benchmarks and show that it outperforms both purely online approaches and simple combinations of online and offline models. The residual learning and adaptive combination mechanisms are key to enabling effective knowledge transfer from the pre-trained OEs to the online tracker.
Critical Analysis
The paper presents a well-designed and compelling approach for leveraging offline expert knowledge to improve online pedestrian tracking. The technical contributions, including the residual learning framework and adaptive combination strategy, are novel and well-justified.
One potential limitation is the reliance on having access to high-quality pre-trained offline expert models. The performance of the ORL approach will be dependent on the capabilities of these OEs, and obtaining or training such models may not always be feasible in practice.
Additionally, the paper does not delve deeply into the interpretability or explainability of the residual learning process. It would be helpful to understand how the online model is selectively incorporating and adapting the offline knowledge, which could provide insights for further improvements.
Overall, the proposed ORL framework represents an important step forward in combining offline and online learning for robust and efficient real-time computer vision tasks like pedestrian tracking. Further research exploring the generalizability of this approach to other domains or its integration with other online learning techniques could be valuable.
Conclusion
The research paper introduces an Online Residual Learning (ORL) framework that effectively leverages pre-trained offline expert models to improve the performance of real-time pedestrian tracking systems. By learning the residual between the offline predictions and true target locations, the online model can adaptively incorporate relevant knowledge from the experts while maintaining the flexibility to adapt to the current live data stream.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements over both purely online and simple offline-online combination methods. This work highlights the potential benefits of hybrid learning approaches that judiciously blend offline and online knowledge for complex, real-world computer vision tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Online Residual Learning from Offline Experts for Pedestrian Tracking
Anastasios Vlachos, Anastasios Tsiamis, Aren Karapetyan, Efe C. Balta, John Lygeros
In this paper, we consider the problem of predicting unknown targets from data. We propose Online Residual Learning (ORL), a method that combines online adaptation with offline-trained predictions. At a lower level, we employ multiple offline predictions generated before or at the beginning of the prediction horizon. We augment every offline prediction by learning their respective residual error concerning the true target state online, using the recursive least squares algorithm. At a higher level, we treat the augmented lower-level predictors as experts, adopting the Prediction with Expert Advice framework. We utilize an adaptive softmax weighting scheme to form an aggregate prediction and provide guarantees for ORL in terms of regret. We employ ORL to boost performance in the setting of online pedestrian trajectory prediction. Based on data from the Stanford Drone Dataset, we show that ORL can demonstrate best-of-both-worlds performance.
Read more9/10/2024
🏅
0
Residual Learning and Context Encoding for Adaptive Offline-to-Online Reinforcement Learning
Mohammadreza Nakhaei, Aidan Scannell, Joni Pajarinen
Offline reinforcement learning (RL) allows learning sequential behavior from fixed datasets. Since offline datasets do not cover all possible situations, many methods collect additional data during online fine-tuning to improve performance. In general, these methods assume that the transition dynamics remain the same during both the offline and online phases of training. However, in many real-world applications, such as outdoor construction and navigation over rough terrain, it is common for the transition dynamics to vary between the offline and online phases. Moreover, the dynamics may vary during the online fine-tuning. To address this problem of changing dynamics from offline to online RL we propose a residual learning approach that infers dynamics changes to correct the outputs of the offline solution. At the online fine-tuning phase, we train a context encoder to learn a representation that is consistent inside the current online learning environment while being able to predict dynamic transitions. Experiments in D4RL MuJoCo environments, modified to support dynamics' changes upon environment resets, show that our approach can adapt to these dynamic changes and generalize to unseen perturbations in a sample-efficient way, whilst comparison methods cannot.
Read more6/13/2024

0
Offline Reinforcement Learning with Imputed Rewards
Carlo Romeo, Andrew D. Bagdanov
Offline Reinforcement Learning (ORL) offers a robust solution to training agents in applications where interactions with the environment must be strictly limited due to cost, safety, or lack of accurate simulation environments. Despite its potential to facilitate deployment of artificial agents in the real world, Offline Reinforcement Learning typically requires very many demonstrations annotated with ground-truth rewards. Consequently, state-of-the-art ORL algorithms can be difficult or impossible to apply in data-scarce scenarios. In this paper we propose a simple but effective Reward Model that can estimate the reward signal from a very limited sample of environment transitions annotated with rewards. Once the reward signal is modeled, we use the Reward Model to impute rewards for a large sample of reward-free transitions, thus enabling the application of ORL techniques. We demonstrate the potential of our approach on several D4RL continuous locomotion tasks. Our results show that, using only 1% of reward-labeled transitions from the original datasets, our learned reward model is able to impute rewards for the remaining 99% of the transitions, from which performant agents can be learned using Offline Reinforcement Learning.
Read more7/16/2024

0
Predictive Linear Online Tracking for Unknown Targets
Anastasios Tsiamis, Aren Karapetyan, Yueshan Li, Efe C. Balta, John Lygeros
In this paper, we study the problem of online tracking in linear control systems, where the objective is to follow a moving target. Unlike classical tracking control, the target is unknown, non-stationary, and its state is revealed sequentially, thus, fitting the framework of online non-stochastic control. We consider the case of quadratic costs and propose a new algorithm, called predictive linear online tracking (PLOT). The algorithm uses recursive least squares with exponential forgetting to learn a time-varying dynamic model of the target. The learned model is used in the optimal policy under the framework of receding horizon control. We show the dynamic regret of PLOT scales with $mathcal{O}(sqrt{TV_T})$, where $V_T$ is the total variation of the target dynamics and $T$ is the time horizon. Unlike prior work, our theoretical results hold for non-stationary targets. We implement PLOT on a real quadrotor and provide open-source software, thus, showcasing one of the first successful applications of online control methods on real hardware.
Read more6/14/2024