Residual Learning and Context Encoding for Adaptive Offline-to-Online Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Offline reinforcement learning (RL) allows learning sequential behavior from fixed datasets
- Existing methods assume the transition dynamics remain the same during offline and online training
- In many real-world applications, the transition dynamics can change between offline and online phases, or even during online fine-tuning
- This paper proposes a residual learning approach to adapt to changing dynamics from offline to online RL
Plain English Explanation
Reinforcement learning is a type of machine learning where an agent learns to take actions in an environment to maximize a reward. Normally, the agent learns by interacting with the environment in real-time. Offline reinforcement learning allows the agent to learn from a fixed dataset, without directly interacting with the environment.
However, in the real world, the environment can change over time. For example, if the agent is learning to navigate rough terrain, the terrain may change between the initial training and when the agent is deployed. Existing methods for offline RL and fine-tuning assume the environment dynamics stay the same. But this is often not the case.
To address this, the authors propose a "residual learning" approach. The key idea is to have the agent learn a representation of the current environment that can predict how the dynamics have changed from the initial offline training. This allows the agent to adapt its behavior to the new environment during the online fine-tuning phase.
Technical Explanation
The paper proposes a residual learning approach to handle changes in transition dynamics between the offline and online phases of reinforcement learning. The main components are:
-
Offline RL: The agent is first trained on a fixed offline dataset using a standard RL algorithm, such as ensemble of successor representations or domain knowledge integration.
-
Context Encoder: During online fine-tuning, the agent trains a "context encoder" network to learn a representation of the current environment. This representation captures how the dynamics have changed from the offline dataset.
-
Residual Correction: The agent uses the context encoder's output to apply a residual correction to the outputs of the offline RL policy. This allows the agent to adapt its behavior to the changed environment.
The authors evaluate this approach on modified MuJoCo environments from the D4RL benchmark, where the transition dynamics change when the environment is reset. The results show that the residual learning method can adapt to these dynamic changes and generalize to unseen perturbations more effectively than comparison methods that assume static dynamics.
Critical Analysis
The paper addresses an important practical challenge in applying offline RL to real-world problems, where the environment dynamics may shift between the offline training and online deployment phases. The proposed residual learning approach is a promising solution to this problem.
However, the authors acknowledge that their method relies on the ability to reset the environment to the same initial state during fine-tuning, which may not always be feasible in real-world applications. Additionally, the paper only evaluates the approach on simulated environments, and further research is needed to test its performance on more complex, real-world tasks.
It would also be valuable to explore how the context encoder's representation could be used to not only adapt the policy, but also update the offline model of the environment dynamics. This could potentially lead to more sample-efficient online fine-tuning by allowing the agent to learn about the changed dynamics more quickly.
Conclusion
This paper presents a novel approach to address the challenge of changing environment dynamics in offline reinforcement learning. By incorporating a context encoder to learn a representation of the current environment and applying a residual correction to the offline policy, the agent can adapt its behavior to the changed dynamics in a sample-efficient manner.
While the paper focuses on simulated environments, the proposed residual learning method has the potential to enable more robust and versatile offline RL systems that can be deployed in real-world applications where the environment is subject to unpredictable changes. Further research is needed to explore the broader applicability of this technique and how it can be extended to handle more complex real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Residual Learning and Context Encoding for Adaptive Offline-to-Online Reinforcement Learning
Mohammadreza Nakhaei, Aidan Scannell, Joni Pajarinen
Offline reinforcement learning (RL) allows learning sequential behavior from fixed datasets. Since offline datasets do not cover all possible situations, many methods collect additional data during online fine-tuning to improve performance. In general, these methods assume that the transition dynamics remain the same during both the offline and online phases of training. However, in many real-world applications, such as outdoor construction and navigation over rough terrain, it is common for the transition dynamics to vary between the offline and online phases. Moreover, the dynamics may vary during the online fine-tuning. To address this problem of changing dynamics from offline to online RL we propose a residual learning approach that infers dynamics changes to correct the outputs of the offline solution. At the online fine-tuning phase, we train a context encoder to learn a representation that is consistent inside the current online learning environment while being able to predict dynamic transitions. Experiments in D4RL MuJoCo environments, modified to support dynamics' changes upon environment resets, show that our approach can adapt to these dynamic changes and generalize to unseen perturbations in a sample-efficient way, whilst comparison methods cannot.
Read more6/13/2024
🏅
0
Offline Reinforcement Learning from Datasets with Structured Non-Stationarity
Johannes Ackermann, Takayuki Osa, Masashi Sugiyama
Current Reinforcement Learning (RL) is often limited by the large amount of data needed to learn a successful policy. Offline RL aims to solve this issue by using transitions collected by a different behavior policy. We address a novel Offline RL problem setting in which, while collecting the dataset, the transition and reward functions gradually change between episodes but stay constant within each episode. We propose a method based on Contrastive Predictive Coding that identifies this non-stationarity in the offline dataset, accounts for it when training a policy, and predicts it during evaluation. We analyze our proposed method and show that it performs well in simple continuous control tasks and challenging, high-dimensional locomotion tasks. We show that our method often achieves the oracle performance and performs better than baselines.
Read more5/29/2024
🏅
0
Model-Based Reinforcement Learning with Multi-Task Offline Pretraining
Minting Pan, Yitao Zheng, Yunbo Wang, Xiaokang Yang
Pretraining reinforcement learning (RL) models on offline datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in dynamics and behaviors across various tasks. We present a model-based RL method that learns to transfer potentially useful dynamics and action demonstrations from offline data to a novel task. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the task relevance for both dynamics representation transfer and policy transfer. We build a time-varying, domain-selective distillation loss to generate a set of offline-to-online similarity weights. These weights serve two purposes: (i) adaptively transferring the task-agnostic knowledge of physical dynamics to facilitate world model training, and (ii) learning to replay relevant source actions to guide the target policy. We demonstrate the advantages of our approach compared with the state-of-the-art methods in Meta-World and DeepMind Control Suite.
Read more6/6/2024
0
Online Residual Learning from Offline Experts for Pedestrian Tracking
Anastasios Vlachos, Anastasios Tsiamis, Aren Karapetyan, Efe C. Balta, John Lygeros
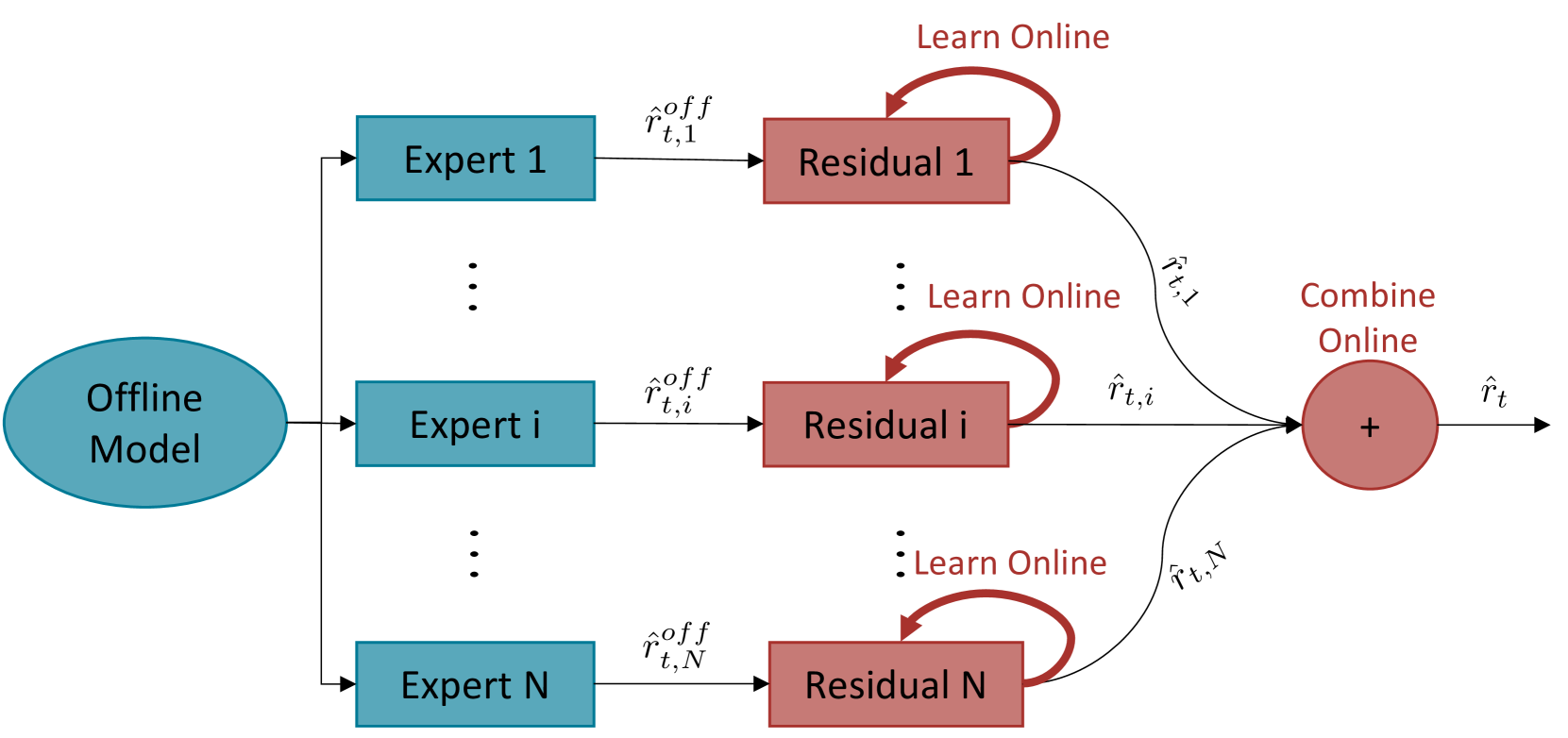
In this paper, we consider the problem of predicting unknown targets from data. We propose Online Residual Learning (ORL), a method that combines online adaptation with offline-trained predictions. At a lower level, we employ multiple offline predictions generated before or at the beginning of the prediction horizon. We augment every offline prediction by learning their respective residual error concerning the true target state online, using the recursive least squares algorithm. At a higher level, we treat the augmented lower-level predictors as experts, adopting the Prediction with Expert Advice framework. We utilize an adaptive softmax weighting scheme to form an aggregate prediction and provide guarantees for ORL in terms of regret. We employ ORL to boost performance in the setting of online pedestrian trajectory prediction. Based on data from the Stanford Drone Dataset, we show that ORL can demonstrate best-of-both-worlds performance.
Read more9/10/2024