Online Speculative Decoding

0

Sign in to get full access
Overview
- This paper introduces a new technique called "online speculative decoding" for improving the efficiency of large language models.
- The key idea is to use speculative decoding, where the model generates multiple candidate outputs in parallel, to reduce overall inference time.
- The authors propose various optimizations to make speculative decoding more practical and effective, such as dynamically adjusting the number of candidates.
- Experiments show the proposed techniques can significantly speed up language model inference with minimal accuracy degradation.
Plain English Explanation
Online Speculative Decoding is a new way to make large language models, like those used for tasks like text generation and translation, run faster. The core idea is to have the model generate multiple possible outputs at once, rather than just one, and then quickly pick the best one.
This "speculative decoding" approach can save a lot of time compared to the traditional approach of generating just a single output. However, generating too many candidates in parallel can also slow things down. So the researchers propose various optimizations to dynamically adjust the number of candidates based on the specific input, in order to find the sweet spot between speed and accuracy.
For example, Accelerating Speculative Decoding Using Dynamic Speculation Length describes a technique to automatically determine the optimal number of candidates to generate for each input. This helps ensure the model is running as efficiently as possible.
Overall, these innovations in Online Speculative Decoding can significantly speed up large language models without sacrificing much accuracy. This could enable faster and more responsive language AI systems for a variety of applications.
Technical Explanation
Online Speculative Decoding is a technique for improving the efficiency of large language models during inference. The key idea is to use
Traditionally, language models generate a single output sequence one token at a time. With speculative decoding, the model instead generates K candidate sequences simultaneously, and then selects the best one. This can be more efficient if the correct output is among the candidates, since the model doesn't have to waste time generating the full sequence for incorrect candidates.
The authors propose various optimizations to make speculative decoding more practical and effective. For example, Accelerating Speculative Decoding Using Dynamic Speculation Length describes a method to dynamically adjust the number of candidate sequences (K) based on the specific input, in order to find the right balance between speed and accuracy.
Experiments on benchmark language tasks show that online speculative decoding can significantly speed up inference time, often by 2-3x, with only a small degradation in task performance. The Unlocking the Efficiency of Large Language Model Inference: A Comprehensive Study paper provides a more in-depth analysis of the tradeoffs involved.
Critical Analysis
The research on online speculative decoding presents a promising approach for accelerating large language model inference. The core idea of generating multiple candidate outputs in parallel is intuitively appealing, and the proposed optimizations like dynamic speculation length help make it more practical.
That said, the paper does not address some potential limitations or open questions. For example, it's not clear how well the techniques would scale to extremely large models or very long output sequences. The Speculative Decoding for Multimodal Large Language Models paper explores applying speculative decoding to multimodal models, but more research is needed on the broader applicability.
Additionally, the SpecdEC: Boosting Speculative Decoding via Adaptive Candidate paper highlights that the optimal number of candidates can vary significantly based on factors like model size and task difficulty. Further work is needed to develop more robust and generalizable approaches for dynamically adjusting the speculation length.
Overall, the online speculative decoding techniques show promise, but there are still opportunities to build on this work and address some of the remaining challenges. Continued research in this area could lead to substantial improvements in the efficiency and real-world deployment of large language models.
Conclusion
Online Speculative Decoding presents a novel approach for accelerating the inference of large language models. By generating multiple candidate outputs in parallel and dynamically adjusting the speculation length, the techniques can significantly speed up model inference with minimal accuracy degradation.
These innovations could enable faster and more responsive language AI systems, benefiting a wide range of applications from translation to text generation. The research also highlights the importance of continued work to unlock the full efficiency potential of large language models, which will be crucial as these models become increasingly central to modern AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Online Speculative Decoding
Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Alvin Cheung, Zhijie Deng, Ion Stoica, Hao Zhang
Speculative decoding is a pivotal technique to accelerate the inference of large language models (LLMs) by employing a smaller draft model to predict the target model's outputs. However, its efficacy can be limited due to the low predictive accuracy of the draft model, particularly when faced with diverse text inputs and a significant capability gap between the draft and target models. We introduce online speculative decoding to address this challenge. The main idea is to continuously update the (multiple) draft model(s) on observed user query data. Adapting to query distribution mitigates the shifts between the training distribution of the draft model and the query distribution, enabling the draft model to more accurately predict the target model's outputs. We develop a prototype of online speculative decoding based on knowledge distillation and evaluate it using both synthetic and real query data. The results show a substantial increase in the token acceptance rate by 0.1 to 0.65, bringing 1.42x to 2.17x latency reduction. Our code is available at https://github.com/LiuXiaoxuanPKU/OSD.
Read more6/11/2024
0
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
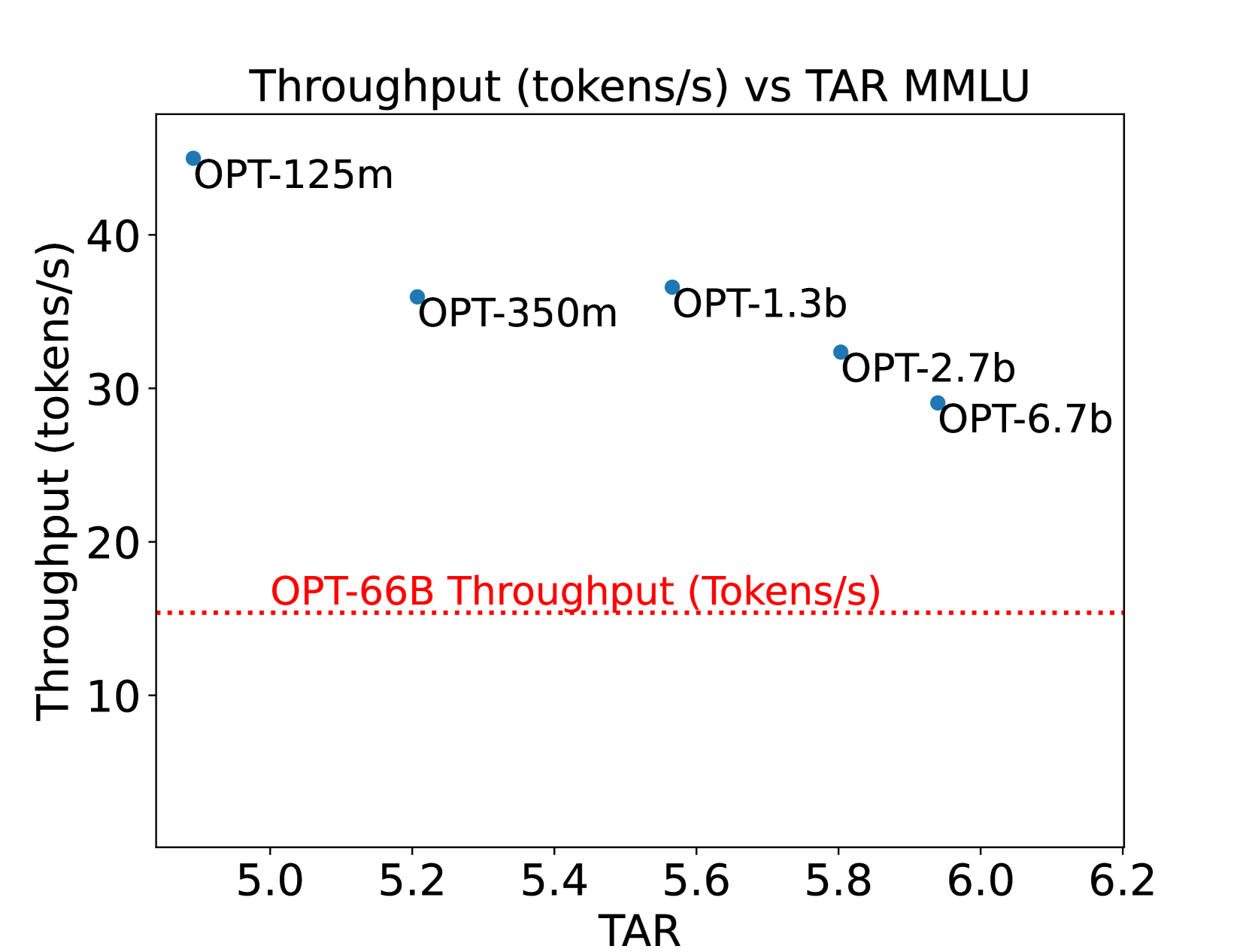
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 111% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
Read more8/13/2024

0
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
Jacob K Christopher, Brian R Bartoldson, Bhavya Kailkhura, Ferdinando Fioretto
Speculative decoding has emerged as a widely adopted method to accelerate large language model inference without sacrificing the quality of the model outputs. While this technique has facilitated notable speed improvements by enabling parallel sequence verification, its efficiency remains inherently limited by the reliance on incremental token generation in existing draft models. To overcome this limitation, this paper proposes an adaptation of speculative decoding which uses discrete diffusion models to generate draft sequences. This allows parallelization of both the drafting and verification steps, providing significant speed-ups to the inference process. Our proposed approach, Speculative Diffusion Decoding (SpecDiff), is validated on standard language generation benchmarks and empirically demonstrated to provide a up to 8.7x speed-up over standard generation processes and up to 2.5x speed-up over existing speculative decoding approaches.
Read more8/20/2024

0
Graph-Structured Speculative Decoding
Zhuocheng Gong, Jiahao Liu, Ziyue Wang, Pengfei Wu, Jingang Wang, Xunliang Cai, Dongyan Zhao, Rui Yan
Speculative decoding has emerged as a promising technique to accelerate the inference of Large Language Models (LLMs) by employing a small language model to draft a hypothesis sequence, which is then validated by the LLM. The effectiveness of this approach heavily relies on the balance between performance and efficiency of the draft model. In our research, we focus on enhancing the proportion of draft tokens that are accepted to the final output by generating multiple hypotheses instead of just one. This allows the LLM more options to choose from and select the longest sequence that meets its standards. Our analysis reveals that hypotheses produced by the draft model share many common token sequences, suggesting a potential for optimizing computation. Leveraging this observation, we introduce an innovative approach utilizing a directed acyclic graph (DAG) to manage the drafted hypotheses. This structure enables us to efficiently predict and merge recurring token sequences, vastly reducing the computational demands of the draft model. We term this approach Graph-structured Speculative Decoding (GSD). We apply GSD across a range of LLMs, including a 70-billion parameter LLaMA-2 model, and observe a remarkable speedup of 1.73$times$ to 1.96$times$, significantly surpassing standard speculative decoding.
Read more7/24/2024