ONNXPruner: ONNX-Based General Model Pruning Adapter
2404.08016
0
0

Abstract
Recent advancements in model pruning have focused on developing new algorithms and improving upon benchmarks. However, the practical application of these algorithms across various models and platforms remains a significant challenge. To address this challenge, we propose ONNXPruner, a versatile pruning adapter designed for the ONNX format models. ONNXPruner streamlines the adaptation process across diverse deep learning frameworks and hardware platforms. A novel aspect of ONNXPruner is its use of node association trees, which automatically adapt to various model architectures. These trees clarify the structural relationships between nodes, guiding the pruning process, particularly highlighting the impact on interconnected nodes. Furthermore, we introduce a tree-level evaluation method. By leveraging node association trees, this method allows for a comprehensive analysis beyond traditional single-node evaluations, enhancing pruning performance without the need for extra operations. Experiments across multiple models and datasets confirm ONNXPruner's strong adaptability and increased efficacy. Our work aims to advance the practical application of model pruning.
Create account to get full access
Overview
• This paper introduces ONNXPruner, a general model pruning adapter that leverages the ONNX (Open Neural Network Exchange) format to enable tree-level evaluation and pruning of deep neural networks.
• The key innovations of ONNXPruner include its ability to handle a wide range of neural network architectures, its support for both structured and unstructured pruning, and its efficient tree-level evaluation approach.
Plain English Explanation
• Model pruning is a technique used to reduce the size and complexity of deep learning models, making them faster and more efficient to use. [object Object], [object Object], and [object Object] are examples of previous research on model pruning.
• ONNXPruner is a tool that makes it easier to prune deep learning models by working with the ONNX format, which is a standard way of representing neural networks. This allows ONNXPruner to handle a wide variety of model architectures, rather than being limited to a specific type of model.
• ONNXPruner supports both "structured" pruning, where entire components of the model are removed, and "unstructured" pruning, where individual connections within the model are removed. This flexibility can help achieve better performance improvements while maintaining model accuracy.
• The key innovation in ONNXPruner is its "tree-level evaluation" approach, which allows it to efficiently analyze the structure of the neural network and identify the best parts to prune. This makes the pruning process faster and more effective than previous methods.
Technical Explanation
• ONNXPruner is designed to work with the ONNX format, which is a standard representation for deep learning models. This allows it to handle a wide range of neural network architectures, rather than being limited to a specific type of model.
• The paper introduces two key techniques used in ONNXPruner:
- Structured and Unstructured Pruning: ONNXPruner supports both structured pruning, where entire components of the model are removed, and unstructured pruning, where individual connections within the model are removed. This flexibility allows for better performance improvements while maintaining model accuracy.
- Tree-level Evaluation: ONNXPruner uses a tree-level evaluation approach to efficiently analyze the structure of the neural network and identify the best parts to prune. This makes the pruning process faster and more effective than previous methods.
• The paper presents experiments comparing ONNXPruner to other state-of-the-art pruning methods, demonstrating its superior performance in terms of model size reduction and inference speed improvements, while maintaining high accuracy.
Critical Analysis
• The paper does not discuss the potential limitations of the ONNXPruner approach, such as its applicability to more complex or specialized neural network architectures, or its performance on different types of tasks or datasets.
• Additionally, the paper does not explore the trade-offs between structured and unstructured pruning in depth, or provide guidance on when one approach may be more appropriate than the other.
• Further research could investigate the impact of ONNXPruner on the interpretability or robustness of the pruned models, as well as its performance on edge cases or adversarial examples.
Conclusion
• ONNXPruner is a promising tool for efficient model pruning, leveraging the ONNX format to enable tree-level evaluation and support for both structured and unstructured pruning techniques.
• The key innovations of ONNXPruner, including its flexibility, efficiency, and performance, have the potential to significantly improve the development and deployment of deep learning models, especially in resource-constrained environments.
• While the paper provides a solid technical foundation, further research and real-world deployment of ONNXPruner could yield additional insights and improvements to model pruning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Rethinking Pruning for Backdoor Mitigation: An Optimization Perspective
Nan Li, Haiyang Yu, Ping Yi
0
0
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks, posing concerning threats to their reliable deployment. Recent research reveals that backdoors can be erased from infected DNNs by pruning a specific group of neurons, while how to effectively identify and remove these backdoor-associated neurons remains an open challenge. Most of the existing defense methods rely on defined rules and focus on neuron's local properties, ignoring the exploration and optimization of pruning policies. To address this gap, we propose an Optimized Neuron Pruning (ONP) method combined with Graph Neural Network (GNN) and Reinforcement Learning (RL) to repair backdoor models. Specifically, ONP first models the target DNN as graphs based on neuron connectivity, and then uses GNN-based RL agents to learn graph embeddings and find a suitable pruning policy. To the best of our knowledge, this is the first attempt to employ GNN and RL for optimizing pruning policies in the field of backdoor defense. Experiments show, with a small amount of clean data, ONP can effectively prune the backdoor neurons implanted by a set of backdoor attacks at the cost of negligible performance degradation, achieving a new state-of-the-art performance for backdoor mitigation.
5/29/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024
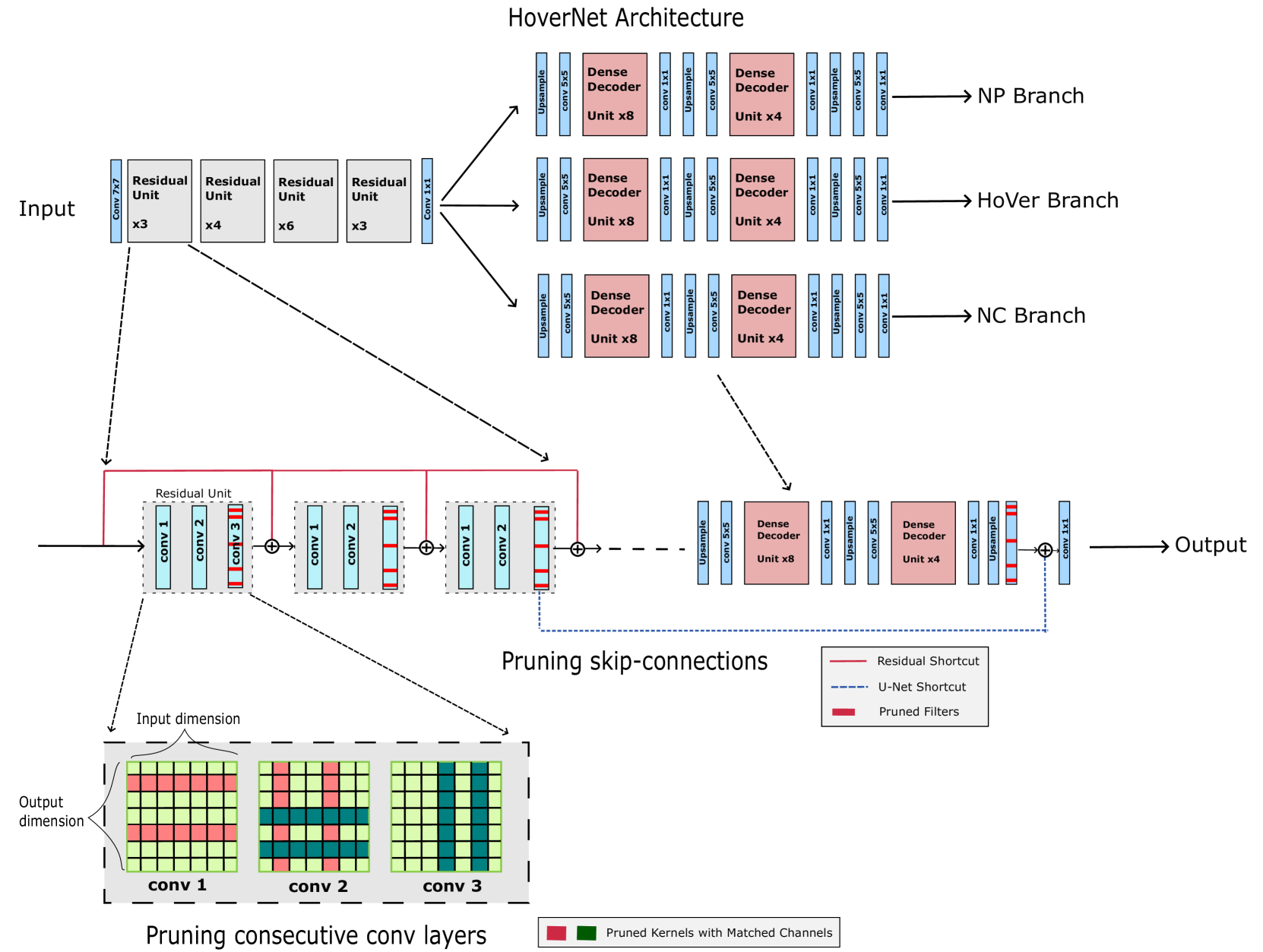
Structured Model Pruning for Efficient Inference in Computational Pathology
Mohammed Adnan, Qinle Ba, Nazim Shaikh, Shivam Kalra, Satarupa Mukherjee, Auranuch Lorsakul
0
0
Recent years have seen significant efforts to adopt Artificial Intelligence (AI) in healthcare for various use cases, from computer-aided diagnosis to ICU triage. However, the size of AI models has been rapidly growing due to scaling laws and the success of foundational models, which poses an increasing challenge to leverage advanced models in practical applications. It is thus imperative to develop efficient models, especially for deploying AI solutions under resource-constrains or with time sensitivity. One potential solution is to perform model compression, a set of techniques that remove less important model components or reduce parameter precision, to reduce model computation demand. In this work, we demonstrate that model pruning, as a model compression technique, can effectively reduce inference cost for computational and digital pathology based analysis with a negligible loss of analysis performance. To this end, we develop a methodology for pruning the widely used U-Net-style architectures in biomedical imaging, with which we evaluate multiple pruning heuristics on nuclei instance segmentation and classification, and empirically demonstrate that pruning can compress models by at least 70% with a negligible drop in performance.
4/16/2024
NeuroPrune: A Neuro-inspired Topological Sparse Training Algorithm for Large Language Models
Amit Dhurandhar, Tejaswini Pedapati, Ronny Luss, Soham Dan, Aurelie Lozano, Payel Das, Georgios Kollias
0
0
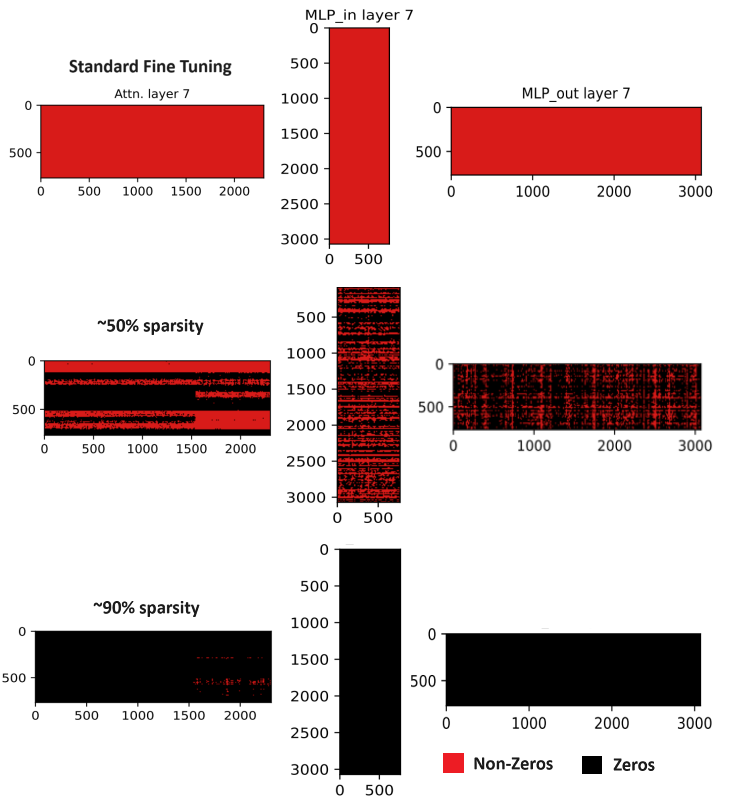
Transformer-based Language Models have become ubiquitous in Natural Language Processing (NLP) due to their impressive performance on various tasks. However, expensive training as well as inference remains a significant impediment to their widespread applicability. While enforcing sparsity at various levels of the model architecture has found promise in addressing scaling and efficiency issues, there remains a disconnect between how sparsity affects network topology. Inspired by brain neuronal networks, we explore sparsity approaches through the lens of network topology. Specifically, we exploit mechanisms seen in biological networks, such as preferential attachment and redundant synapse pruning, and show that principled, model-agnostic sparsity approaches are performant and efficient across diverse NLP tasks, spanning both classification (such as natural language inference) and generation (summarization, machine translation), despite our sole objective not being optimizing performance. NeuroPrune is competitive with (or sometimes superior to) baselines on performance and can be up to $10$x faster in terms of training time for a given level of sparsity, simultaneously exhibiting measurable improvements in inference time in many cases.
6/6/2024