Structured Model Pruning for Efficient Inference in Computational Pathology
2404.08831
0
0
Abstract
Recent years have seen significant efforts to adopt Artificial Intelligence (AI) in healthcare for various use cases, from computer-aided diagnosis to ICU triage. However, the size of AI models has been rapidly growing due to scaling laws and the success of foundational models, which poses an increasing challenge to leverage advanced models in practical applications. It is thus imperative to develop efficient models, especially for deploying AI solutions under resource-constrains or with time sensitivity. One potential solution is to perform model compression, a set of techniques that remove less important model components or reduce parameter precision, to reduce model computation demand. In this work, we demonstrate that model pruning, as a model compression technique, can effectively reduce inference cost for computational and digital pathology based analysis with a negligible loss of analysis performance. To this end, we develop a methodology for pruning the widely used U-Net-style architectures in biomedical imaging, with which we evaluate multiple pruning heuristics on nuclei instance segmentation and classification, and empirically demonstrate that pruning can compress models by at least 70% with a negligible drop in performance.
Create account to get full access
Overview
- This paper proposes a structured model pruning approach to improve the efficiency of deep learning models in computational pathology.
- The method involves selectively removing less important model parameters to reduce the overall model size and inference time, while maintaining high task performance.
- The authors demonstrate the effectiveness of their approach on several medical image classification tasks, achieving significant model compression without sacrificing accuracy.
Plain English Explanation
Deep learning models have become incredibly powerful at tasks like medical image analysis, but they can also be very large and computationally intensive. This makes them challenging to deploy in real-world clinical settings, where speed and efficiency are crucial.
The researchers in this paper have developed a new technique called "structured model pruning" to make these models more efficient. The key idea is to carefully identify and remove parts of the model that aren't doing much useful work, kind of like trimming the fat from a piece of meat. This reduces the overall model size and speeds up the time it takes to make predictions, without significantly hurting the model's performance on the task at hand.
They tested this approach on several medical image classification problems, like diagnosing diseases from microscope slides. The results show they were able to [object Object] - making them up to 10 times smaller - while still maintaining high accuracy. This could be a big help in bringing these powerful AI tools into real-world clinical practice, where fast and efficient inference is essential.
Technical Explanation
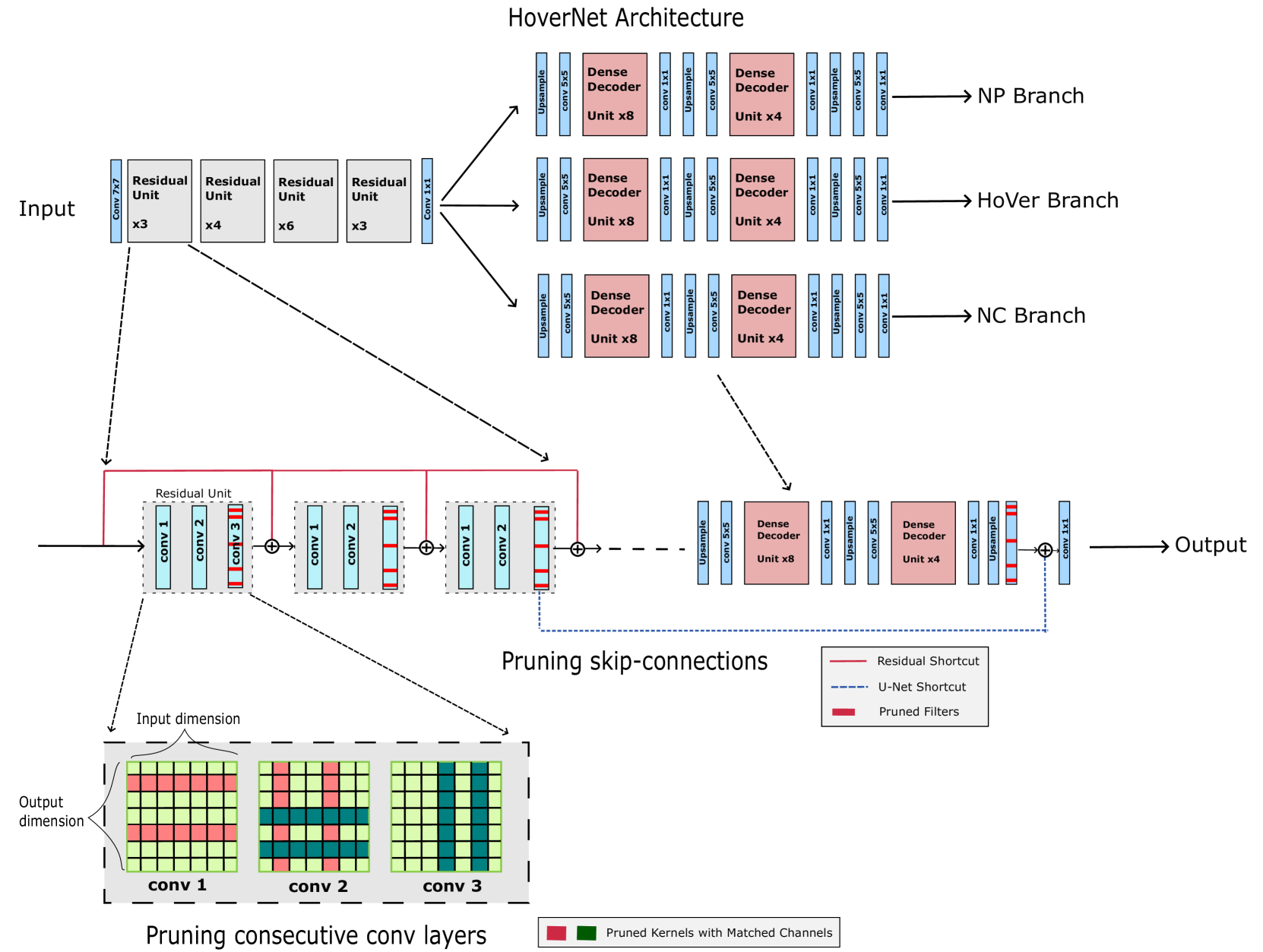
The authors propose a structured model pruning approach to achieve efficient inference in computational pathology tasks. Unlike unstructured pruning that removes individual weights, their method prunes entire filters or channels in the convolutional layers of the model in a structured way.
They start by training a full-size model on the target task, then use a series of techniques to identify the least important filters/channels. These include [object Object], [object Object], and [object Object]. The pruned model is then fine-tuned to recover any lost performance.
The authors evaluate their approach on several medical image classification tasks, including breast cancer detection and lymph node metastasis identification. They achieve [object Object] (up to 10x reduction in parameters) while maintaining high accuracy, demonstrating the effectiveness of structured pruning for efficient inference in computational pathology.
Critical Analysis
The authors provide a thorough analysis of their structured pruning technique and its impact on model performance and efficiency. However, a few potential limitations and areas for future work are worth noting:
- The pruning strategy is largely heuristic-based, and more principled, data-driven approaches could potentially yield further improvements.
- The experiments are limited to a few specific medical imaging tasks, and the generalization of the technique to other domains or modalities is not established.
- The tradeoffs between different pruning strategies (e.g., channel vs. filter pruning) are not extensively explored.
- The impact of pruning on other important metrics, such as model robustness or interpretability, is not investigated.
Further research could address these areas and explore the broader applicability of structured pruning for efficient deployment of deep learning models in real-world clinical settings.
Conclusion
This paper presents a structured model pruning approach that can significantly compress deep learning models used in computational pathology, without compromising their task performance. By selectively removing less important model components, the authors demonstrate the ability to achieve up to 10x reduction in model size and inference time, which could be crucial for practical deployment of these powerful AI tools in clinical workflows. The technical insights and empirical results provided in this work contribute to the ongoing efforts to make deep learning more efficient and practical for real-world applications in healthcare and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
Rapid Deployment of DNNs for Edge Computing via Structured Pruning at Initialization
Bailey J. Eccles, Leon Wong, Blesson Varghese
0
0
Edge machine learning (ML) enables localized processing of data on devices and is underpinned by deep neural networks (DNNs). However, DNNs cannot be easily run on devices due to their substantial computing, memory and energy requirements for delivering performance that is comparable to cloud-based ML. Therefore, model compression techniques, such as pruning, have been considered. Existing pruning methods are problematic for edge ML since they: (1) Create compressed models that have limited runtime performance benefits (using unstructured pruning) or compromise the final model accuracy (using structured pruning), and (2) Require substantial compute resources and time for identifying a suitable compressed DNN model (using neural architecture search). In this paper, we explore a new avenue, referred to as Pruning-at-Initialization (PaI), using structured pruning to mitigate the above problems. We develop Reconvene, a system for rapidly generating pruned models suited for edge deployments using structured PaI. Reconvene systematically identifies and prunes DNN convolution layers that are least sensitive to structured pruning. Reconvene rapidly creates pruned DNNs within seconds that are up to 16.21x smaller and 2x faster while maintaining the same accuracy as an unstructured PaI counterpart.
4/29/2024
🤖
Investigation of Energy-efficient AI Model Architectures and Compression Techniques for Green Fetal Brain Segmentation
Szymon Mazurek, Monika Pytlarz, Sylwia Malec, Alessandro Crimi
0
0
Artificial intelligence have contributed to advancements across various industries. However, the rapid growth of artificial intelligence technologies also raises concerns about their environmental impact, due to associated carbon footprints to train computational models. Fetal brain segmentation in medical imaging is challenging due to the small size of the fetal brain and the limited image quality of fast 2D sequences. Deep neural networks are a promising method to overcome this challenge. In this context, the construction of larger models requires extensive data and computing power, leading to high energy consumption. Our study aims to explore model architectures and compression techniques that promote energy efficiency by optimizing the trade-off between accuracy and energy consumption through various strategies such as lightweight network design, architecture search, and optimized distributed training tools. We have identified several effective strategies including optimization of data loading, modern optimizers, distributed training strategy implementation, and reduced floating point operations precision usage with light model architectures while tuning parameters according to available computer resources. Our findings demonstrate that these methods lead to satisfactory model performance with low energy consumption during deep neural network training for medical image segmentation.
5/28/2024
💬
Structural Pruning of Pre-trained Language Models via Neural Architecture Search
Aaron Klein, Jacek Golebiowski, Xingchen Ma, Valerio Perrone, Cedric Archambeau
0
0
Pre-trained language models (PLM), for example BERT or RoBERTa, mark the state-of-the-art for natural language understanding task when fine-tuned on labeled data. However, their large size poses challenges in deploying them for inference in real-world applications, due to significant GPU memory requirements and high inference latency. This paper explores neural architecture search (NAS) for structural pruning to find sub-parts of the fine-tuned network that optimally trade-off efficiency, for example in terms of model size or latency, and generalization performance. We also show how we can utilize more recently developed two-stage weight-sharing NAS approaches in this setting to accelerate the search process. Unlike traditional pruning methods with fixed thresholds, we propose to adopt a multi-objective approach that identifies the Pareto optimal set of sub-networks, allowing for a more flexible and automated compression process.
5/6/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024