OntoType: Ontology-Guided and Pre-Trained Language Model Assisted Fine-Grained Entity Typing

0
💬
Sign in to get full access
Overview
- The paper discusses a novel method called OntoType for fine-grained entity typing (FET) without requiring manual annotations.
- FET is an important task for extracting knowledge from unstructured text, but existing approaches rely on costly human-annotated datasets.
- The authors propose using pre-trained language models (PLMs) as a knowledge base, guided by an ontology, to generate weak supervision for FET.
- Their method, OntoType, follows a hierarchical ontological structure to ensemble multiple PLM prompting results and refine the type resolution using natural language inference.
Plain English Explanation
The paper presents a new way to categorize entities in text into detailed semantic types, without needing人手注释. This task, called fine-grained entity typing (FET), is crucial for extracting useful information from unstructured data like articles or social media posts.
However, the current methods for FET rely on having a large dataset where the entities have already been manually labeled with their types. This is a time-consuming and expensive process. The authors of this paper wanted to find a better solution.
Their idea is to use the knowledge stored in pre-trained language models (PLMs) like BERT or GPT as a source of information about entity types. By prompting these models with the text, they can generate potential type labels.
To make this work better, the authors also use an ontology - a hierarchical structure that defines how different entity types relate to each other. This helps the system choose the most appropriate types from the PLM outputs.
Finally, the method uses natural language inference to refine the type assignments based on the surrounding context. The result is a powerful FET system that can work without any manual annotations.
Technical Explanation
The proposed OntoType method follows a three-step process:
-
Type Candidate Generation: OntoType prompts multiple pre-trained language models (PLMs) with the entity mention and its context to generate a set of potential type candidates. It then aligns these candidate types with the ontological structure to select the most relevant ones.
-
Type Refinement: OntoType uses a natural language inference (NLI) model to refine the type assignments based on the local context. The NLI model assesses whether the entity mention and the candidate types are entailed by the surrounding text.
-
Type Resolution: OntoType resolves the final entity type by combining the type candidates from step 1 and the refined types from step 2, following the hierarchical structure of the ontology.
The authors evaluate OntoType on three benchmark datasets (Ontonotes, FIGER, and NYT) and show that it outperforms state-of-the-art zero-shot FET methods, as well as a typical large language model (LLM) like ChatGPT.
Critical Analysis
The paper demonstrates the potential of using pre-trained language models and ontologies to address the annotation bottleneck in fine-grained entity typing. However, there are a few areas where the research could be further improved or expanded:
-
Ontology Refinement: The authors acknowledge that refining the existing ontology structures could lead to further improvements in FET performance. Exploring methods to automatically curate and expand the ontologies could be a valuable direction for future work.
-
Generalization Across Domains: The evaluation in the paper is limited to a few narrow datasets. It would be important to assess the generalization of the OntoType method across a wider range of domains and text genres.
-
Interpretability and Transparency: As the authors rely on a combination of PLM outputs and NLI, it may be useful to provide more insight into the decision-making process and the relative contributions of each component.
-
Potential Biases: Like any system that leverages large language models, OntoType may inherit biases present in the training data. Analyzing and mitigating these biases should be a priority.
Overall, the OntoType approach is a promising step towards annotation-free fine-grained entity typing, with the potential to unlock the value of unstructured text data for knowledge extraction and other downstream tasks.
Conclusion
This paper introduces a novel method called OntoType for fine-grained entity typing (FET) that does not require manual annotations. OntoType leverages the knowledge stored in pre-trained language models, guided by an ontological structure, to generate weak supervision for the FET task.
The authors demonstrate that their approach outperforms state-of-the-art zero-shot FET methods, as well as a typical large language model like ChatGPT. This work highlights the potential of using ontologies and large language models to address the annotation bottleneck in knowledge extraction from unstructured text.
While the research shows promising results, there are opportunities to further improve the method, such as by refining the ontology structures and analyzing potential biases. Overall, the OntoType framework represents an important step forward in making fine-grained entity typing more accessible and scalable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
OntoType: Ontology-Guided and Pre-Trained Language Model Assisted Fine-Grained Entity Typing
Tanay Komarlu, Minhao Jiang, Xuan Wang, Jiawei Han
Fine-grained entity typing (FET), which assigns entities in text with context-sensitive, fine-grained semantic types, is a basic but important task for knowledge extraction from unstructured text. FET has been studied extensively in natural language processing and typically relies on human-annotated corpora for training, which is costly and difficult to scale. Recent studies explore the utilization of pre-trained language models (PLMs) as a knowledge base to generate rich and context-aware weak supervision for FET. However, a PLM still requires direction and guidance to serve as a knowledge base as they often generate a mixture of rough and fine-grained types, or tokens unsuitable for typing. In this study, we vision that an ontology provides a semantics-rich, hierarchical structure, which will help select the best results generated by multiple PLM models and head words. Specifically, we propose a novel annotation-free, ontology-guided FET method, OntoType, which follows a type ontological structure, from coarse to fine, ensembles multiple PLM prompting results to generate a set of type candidates, and refines its type resolution, under the local context with a natural language inference model. Our experiments on the Ontonotes, FIGER, and NYT datasets using their associated ontological structures demonstrate that our method outperforms the state-of-the-art zero-shot fine-grained entity typing methods as well as a typical LLM method, ChatGPT. Our error analysis shows that refinement of the existing ontology structures will further improve fine-grained entity typing.
Read more6/12/2024

0
ToNER: Type-oriented Named Entity Recognition with Generative Language Model
Guochao Jiang, Ziqin Luo, Yuchen Shi, Dixuan Wang, Jiaqing Liang, Deqing Yang
In recent years, the fine-tuned generative models have been proven more powerful than the previous tagging-based or span-based models on named entity recognition (NER) task. It has also been found that the information related to entities, such as entity types, can prompt a model to achieve NER better. However, it is not easy to determine the entity types indeed existing in the given sentence in advance, and inputting too many potential entity types would distract the model inevitably. To exploit entity types' merit on promoting NER task, in this paper we propose a novel NER framework, namely ToNER based on a generative model. In ToNER, a type matching model is proposed at first to identify the entity types most likely to appear in the sentence. Then, we append a multiple binary classification task to fine-tune the generative model's encoder, so as to generate the refined representation of the input sentence. Moreover, we add an auxiliary task for the model to discover the entity types which further fine-tunes the model to output more accurate results. Our extensive experiments on some NER benchmarks verify the effectiveness of our proposed strategies in ToNER that are oriented towards entity types' exploitation.
Read more6/12/2024

0
Towards Ontology-Enhanced Representation Learning for Large Language Models
Francesco Ronzano, Jay Nanavati
Taking advantage of the widespread use of ontologies to organise and harmonize knowledge across several distinct domains, this paper proposes a novel approach to improve an embedding-Large Language Model (embedding-LLM) of interest by infusing the knowledge formalized by a reference ontology: ontological knowledge infusion aims at boosting the ability of the considered LLM to effectively model the knowledge domain described by the infused ontology. The linguistic information (i.e. concept synonyms and descriptions) and structural information (i.e. is-a relations) formalized by the ontology are utilized to compile a comprehensive set of concept definitions, with the assistance of a powerful generative LLM (i.e. GPT-3.5-turbo). These concept definitions are then employed to fine-tune the target embedding-LLM using a contrastive learning framework. To demonstrate and evaluate the proposed approach, we utilize the biomedical disease ontology MONDO. The results show that embedding-LLMs enhanced by ontological disease knowledge exhibit an improved capability to effectively evaluate the similarity of in-domain sentences from biomedical documents mentioning diseases, without compromising their out-of-domain performance.
Read more6/3/2024
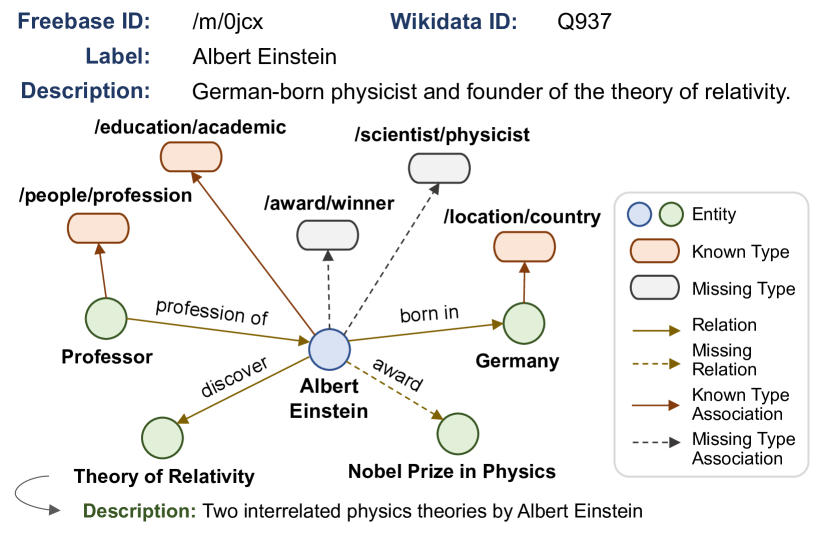
0
The Integration of Semantic and Structural Knowledge in Knowledge Graph Entity Typing
Muzhi Li, Minda Hu, Irwin King, Ho-fung Leung
The Knowledge Graph Entity Typing (KGET) task aims to predict missing type annotations for entities in knowledge graphs. Recent works only utilize the textit{textbf{structural knowledge}} in the local neighborhood of entities, disregarding textit{textbf{semantic knowledge}} in the textual representations of entities, relations, and types that are also crucial for type inference. Additionally, we observe that the interaction between semantic and structural knowledge can be utilized to address the false-negative problem. In this paper, we propose a novel textbf{underline{S}}emantic and textbf{underline{S}}tructure-aware KG textbf{underline{E}}ntity textbf{underline{T}}yping~{(SSET)} framework, which is composed of three modules. First, the textit{Semantic Knowledge Encoding} module encodes factual knowledge in the KG with a Masked Entity Typing task. Then, the textit{Structural Knowledge Aggregation} module aggregates knowledge from the multi-hop neighborhood of entities to infer missing types. Finally, the textit{Unsupervised Type Re-ranking} module utilizes the inference results from the two models above to generate type predictions that are robust to false-negative samples. Extensive experiments show that SSET significantly outperforms existing state-of-the-art methods.
Read more4/15/2024