COTET: Cross-view Optimal Transport for Knowledge Graph Entity Typing

0
🤿
Sign in to get full access
Overview
- The paper introduces a method called Cross-view Optimal Transport for knowledge graph Entity Typing (COTET) that aims to improve the task of knowledge graph entity typing.
- This task involves inferring missing entity type instances in knowledge graphs, which is important for knowledge graph extension.
- COTET effectively incorporates information about how entity types are clustered, capturing both high-level coarse-grained cluster knowledge and fine-grained type knowledge.
Plain English Explanation
Knowledge graphs are like digital encyclopedias that store information about the world in a structured way. Knowledge graph entity typing is the process of identifying the types or categories that different entities (like people, places, or things) belong to within these knowledge graphs.
The authors of this paper realized that previous methods for entity typing have mostly focused on using the information directly associated with an entity, like the text describing it. However, they argue that it's also important to consider how the different types of entities are related and clustered together.
The COTET method they introduce tries to capture both the fine-grained details about an entity's type as well as the broader, high-level clusters that those types belong to. It does this by generating multiple "views" of the entities and their types, and then aligning those views in a smart way to make better predictions about an entity's type.
The key insight is that looking at entities and types from different perspectives - like how they relate to each other directly, or how they are grouped into broader clusters - can provide valuable clues that improve the accuracy of the entity typing task. This is an important advancement that could help build more comprehensive and accurate knowledge graphs.
Technical Explanation
The COTET method proposed in this paper consists of three main modules:
-
Multi-view Generation and Encoder: This module captures structured knowledge about entities and types at different levels of granularity. It generates three different "views" of the data: entity-type, entity-cluster, and type-cluster-type. These views represent the entity-type relationships, the clustering of entities, and the clustering of types, respectively.
-
Cross-view Optimal Transport: This module takes the view-specific embeddings generated in the first step and aligns them into a unified space. It does this by minimizing the Wasserstein distance between the distributions of the different views, effectively transporting the embeddings to a common representation.
-
Pooling-based Entity Typing Prediction: This final module aggregates the prediction scores from the diverse neighbors of an entity using a mixture pooling mechanism. This allows the model to leverage information from multiple perspectives when making the final entity type predictions.
Additionally, the authors introduce a distribution-based loss function to help mitigate the problem of false negatives during training.
The key innovation of COTET is its ability to capture both the fine-grained type information and the coarse-grained clustering information about entities and types. By aligning these different views through optimal transport, the model can make more accurate type predictions for entities in the knowledge graph.
Critical Analysis
The authors make a compelling case for the importance of considering both fine-grained and coarse-grained knowledge when performing knowledge graph entity typing. Their COTET method represents a promising advance in this direction, as evidenced by its strong performance compared to existing baselines.
However, the paper does not address certain limitations or potential issues with the approach:
-
Scalability: The optimal transport component of COTET may become computationally expensive as the size of the knowledge graph grows. The authors should discuss strategies for improving the scalability of this module.
-
Interpretability: While the multi-view approach is intuitive, the paper does not provide much insight into how the different views contribute to the final predictions. Improving the interpretability of the model could make it easier to understand and debug.
-
Real-world Applicability: The experiments in the paper are conducted on standard benchmark datasets. It would be valuable to see how COTET performs on more diverse, real-world knowledge graphs with varying characteristics.
-
Robustness: The paper does not address how COTET might handle noisy or incomplete data, which is a common challenge in knowledge graph construction and maintenance.
Overall, the COTET method represents an important step forward in knowledge graph entity typing, and the authors have made a valuable contribution to the field. However, further research is needed to address the limitations and ensure the practical viability of the approach.
Conclusion
The COTET method introduced in this paper tackles the important task of knowledge graph entity typing by effectively incorporating both fine-grained type knowledge and coarse-grained cluster knowledge about entities and their relationships.
By generating multiple views of the data and aligning them through optimal transport, COTET is able to make more accurate type predictions for entities in the knowledge graph. This is a significant advancement over previous methods that have primarily relied on the contextual information directly associated with entities.
The authors' work highlights the importance of considering the dual nature of information inherent in knowledge graphs, and their COTET method represents an important step towards integrating semantic and structural knowledge for improved knowledge graph extension and type-oriented named entity recognition.
While the method shows promise, further research is needed to address scalability, interpretability, and robustness concerns. Nonetheless, this paper makes a valuable contribution to the field and paves the way for more advanced techniques in knowledge graph management and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
COTET: Cross-view Optimal Transport for Knowledge Graph Entity Typing
Zhiwei Hu, V'ictor Guti'errez-Basulto, Zhiliang Xiang, Ru Li, Jeff Z. Pan
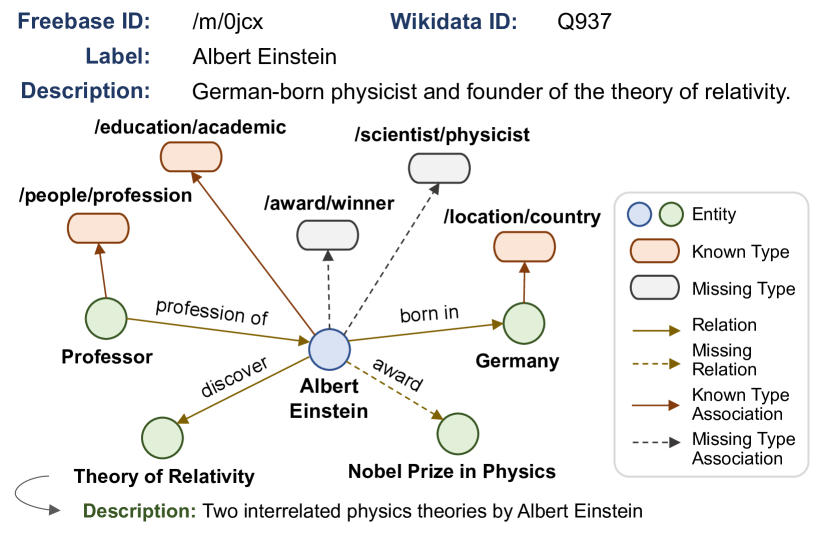
Knowledge graph entity typing (KGET) aims to infer missing entity type instances in knowledge graphs. Previous research has predominantly centered around leveraging contextual information associated with entities, which provides valuable clues for inference. However, they have long ignored the dual nature of information inherent in entities, encompassing both high-level coarse-grained cluster knowledge and fine-grained type knowledge. This paper introduces Cross-view Optimal Transport for knowledge graph Entity Typing (COTET), a method that effectively incorporates the information on how types are clustered into the representation of entities and types. COTET comprises three modules: i) Multi-view Generation and Encoder, which captures structured knowledge at different levels of granularity through entity-type, entity-cluster, and type-cluster-type perspectives; ii) Cross-view Optimal Transport, transporting view-specific embeddings to a unified space by minimizing the Wasserstein distance from a distributional alignment perspective; iii) Pooling-based Entity Typing Prediction, employing a mixture pooling mechanism to aggregate prediction scores from diverse neighbors of an entity. Additionally, we introduce a distribution-based loss function to mitigate the occurrence of false negatives during training. Extensive experiments demonstrate the effectiveness of COTET when compared to existing baselines.
Read more5/24/2024
0
The Integration of Semantic and Structural Knowledge in Knowledge Graph Entity Typing
Muzhi Li, Minda Hu, Irwin King, Ho-fung Leung
The Knowledge Graph Entity Typing (KGET) task aims to predict missing type annotations for entities in knowledge graphs. Recent works only utilize the textit{textbf{structural knowledge}} in the local neighborhood of entities, disregarding textit{textbf{semantic knowledge}} in the textual representations of entities, relations, and types that are also crucial for type inference. Additionally, we observe that the interaction between semantic and structural knowledge can be utilized to address the false-negative problem. In this paper, we propose a novel textbf{underline{S}}emantic and textbf{underline{S}}tructure-aware KG textbf{underline{E}}ntity textbf{underline{T}}yping~{(SSET)} framework, which is composed of three modules. First, the textit{Semantic Knowledge Encoding} module encodes factual knowledge in the KG with a Masked Entity Typing task. Then, the textit{Structural Knowledge Aggregation} module aggregates knowledge from the multi-hop neighborhood of entities to infer missing types. Finally, the textit{Unsupervised Type Re-ranking} module utilizes the inference results from the two models above to generate type predictions that are robust to false-negative samples. Extensive experiments show that SSET significantly outperforms existing state-of-the-art methods.
Read more4/15/2024

0
Quantum Theory and Application of Contextual Optimal Transport
Nicola Mariella, Albert Akhriev, Francesco Tacchino, Christa Zoufal, Juan Carlos Gonzalez-Espitia, Benedek Harsanyi, Eugene Koskin, Ivano Tavernelli, Stefan Woerner, Marianna Rapsomaniki, Sergiy Zhuk, Jannis Born
Optimal Transport (OT) has fueled machine learning (ML) across many domains. When paired data measurements $(boldsymbol{mu}, boldsymbol{nu})$ are coupled to covariates, a challenging conditional distribution learning setting arises. Existing approaches for learning a $textit{global}$ transport map parameterized through a potentially unseen context utilize Neural OT and largely rely on Brenier's theorem. Here, we propose a first-of-its-kind quantum computing formulation for amortized optimization of contextualized transportation plans. We exploit a direct link between doubly stochastic matrices and unitary operators thus unravelling a natural connection between OT and quantum computation. We verify our method (QontOT) on synthetic and real data by predicting variations in cell type distributions conditioned on drug dosage. Importantly we conduct a 24-qubit hardware experiment on a task challenging for classical computers and report a performance that cannot be matched with our classical neural OT approach. In sum, this is a first step toward learning to predict contextualized transportation plans through quantum computing.
Read more6/4/2024
💬
0
OntoType: Ontology-Guided and Pre-Trained Language Model Assisted Fine-Grained Entity Typing
Tanay Komarlu, Minhao Jiang, Xuan Wang, Jiawei Han
Fine-grained entity typing (FET), which assigns entities in text with context-sensitive, fine-grained semantic types, is a basic but important task for knowledge extraction from unstructured text. FET has been studied extensively in natural language processing and typically relies on human-annotated corpora for training, which is costly and difficult to scale. Recent studies explore the utilization of pre-trained language models (PLMs) as a knowledge base to generate rich and context-aware weak supervision for FET. However, a PLM still requires direction and guidance to serve as a knowledge base as they often generate a mixture of rough and fine-grained types, or tokens unsuitable for typing. In this study, we vision that an ontology provides a semantics-rich, hierarchical structure, which will help select the best results generated by multiple PLM models and head words. Specifically, we propose a novel annotation-free, ontology-guided FET method, OntoType, which follows a type ontological structure, from coarse to fine, ensembles multiple PLM prompting results to generate a set of type candidates, and refines its type resolution, under the local context with a natural language inference model. Our experiments on the Ontonotes, FIGER, and NYT datasets using their associated ontological structures demonstrate that our method outperforms the state-of-the-art zero-shot fine-grained entity typing methods as well as a typical LLM method, ChatGPT. Our error analysis shows that refinement of the existing ontology structures will further improve fine-grained entity typing.
Read more6/12/2024