QueSTMaps: Queryable Semantic Topological Maps for 3D Scene Understanding

0

Sign in to get full access
Overview
- This paper introduces QueSTMaps, a novel approach to 3D scene understanding that combines semantic and topological information.
- QueSTMaps can be used to build queryable 3D maps of indoor environments, allowing for advanced scene understanding and interaction.
- The system leverages deep learning models to extract semantic information from 3D point clouds and construct a topological graph representation of the scene.
Plain English Explanation
QueSTMaps is a new way to build 3D maps of indoor spaces that are not only visually detailed, but also contain a deep understanding of the objects and layout of the environment. Rather than just creating a basic 3D model, QueSTMaps uses advanced AI techniques to analyze the 3D data and identify the different elements in the space, like furniture, walls, and doorways.
This semantic information is then used to construct a topological graph, which is a kind of map that shows how all the different parts of the space are connected and related to each other. This allows the system to not just display the 3D scene, but also answer complex queries about it, like "Where is the closest exit from this room?" or "What objects in this space are meant for sitting?"
By combining the visual and semantic understanding of the environment, QueSTMaps can enable a wide range of applications, from better navigation and interaction in virtual environments, to enhanced planning and decision-making for real-world spaces. The key innovation is this idea of creating a "queryable" 3D map that goes beyond just showing the geometry to also capture the underlying structure and meaning of the space.
Technical Explanation
The QueSTMaps approach starts by using deep learning models to extract semantic information from 3D point cloud data of indoor environments. This includes classifying the different objects and surfaces in the scene, as well as understanding their relationships and functions. Hierarchical Insights: Exploiting Structural Similarities for Reliable 3D, 3D Open Vocabulary Panoptic Segmentation in 2D-3D, and Unified Spatio-Temporal Tri-Perspective View Representation are examples of related work in this area.
The semantic information is then used to construct a topological graph representation of the scene, where the nodes correspond to objects or regions, and the edges represent their spatial and functional relationships. This allows the system to reason about the scene in terms of its underlying structure, rather than just its surface geometry. Semantic Flow: Learning Semantic Field in Dynamic Scenes and Quad-Query: Based Interpretable Neural Motion Planning explore related techniques for representing and reasoning about 3D environments.
By encoding the semantic and topological information in a queryable format, QueSTMaps enables a wide range of advanced scene understanding and interaction capabilities, such as natural language querying, path planning, and object retrieval. This goes beyond what is possible with traditional 3D maps or point cloud visualizations.
Critical Analysis
The QueSTMaps approach presents a promising direction for 3D scene understanding, but it also has some limitations and areas for further research. One key challenge is the accuracy and robustness of the deep learning models used for semantic segmentation and object detection, which can be sensitive to noise, occlusions, and variations in the input data.
Additionally, the construction of the topological graph relies on heuristics and assumptions about the spatial and functional relationships between objects, which may not always align with human intuition or the specific needs of a given application. Exploring more principled and adaptive approaches to building the topological representation could be an area for future work.
Finally, while the paper demonstrates the capabilities of QueSTMaps through a few example use cases, it would be valuable to see more comprehensive evaluations of the system's performance and applicability across a broader range of real-world scenarios and tasks.
Conclusion
Overall, the QueSTMaps approach represents an exciting step forward in 3D scene understanding, combining semantic and topological information to enable a new level of interaction and reasoning about indoor environments. By transitioning from simple 3D visualizations to queryable, semantically-aware representations, this work opens up new possibilities for enhanced navigation, planning, and decision-making in virtual and physical spaces.
As AI and robotics continue to advance, tools like QueSTMaps will become increasingly important for bridging the gap between the digital and physical worlds, and for developing intelligent systems that can truly understand and engage with their surroundings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
QueSTMaps: Queryable Semantic Topological Maps for 3D Scene Understanding
Yash Mehan, Kumaraditya Gupta, Rohit Jayanti, Anirudh Govil, Sourav Garg, Madhava Krishna
Understanding the structural organisation of 3D indoor scenes in terms of rooms is often accomplished via floorplan extraction. Robotic tasks such as planning and navigation require a semantic understanding of the scene as well. This is typically achieved via object-level semantic segmentation. However, such methods struggle to segment out topological regions like kitchen in the scene. In this work, we introduce a two-step pipeline. First, we extract a topological map, i.e., floorplan of the indoor scene using a novel multi-channel occupancy representation. Then, we generate CLIP-aligned features and semantic labels for every room instance based on the objects it contains using a self-attention transformer. Our language-topology alignment supports natural language querying, e.g., a place to cook locates the kitchen. We outperform the current state-of-the-art on room segmentation by ~20% and room classification by ~12%. Our detailed qualitative analysis and ablation studies provide insights into the problem of joint structural and semantic 3D scene understanding.
Read more4/10/2024
0
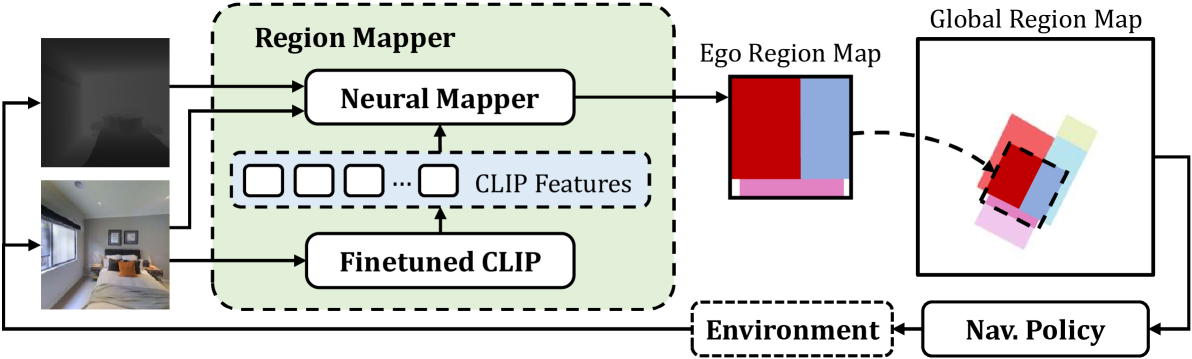
Mapping High-level Semantic Regions in Indoor Environments without Object Recognition
Roberto Bigazzi, Lorenzo Baraldi, Shreyas Kousik, Rita Cucchiara, Marco Pavone
Robots require a semantic understanding of their surroundings to operate in an efficient and explainable way in human environments. In the literature, there has been an extensive focus on object labeling and exhaustive scene graph generation; less effort has been focused on the task of purely identifying and mapping large semantic regions. The present work proposes a method for semantic region mapping via embodied navigation in indoor environments, generating a high-level representation of the knowledge of the agent. To enable region identification, the method uses a vision-to-language model to provide scene information for mapping. By projecting egocentric scene understanding into the global frame, the proposed method generates a semantic map as a distribution over possible region labels at each location. This mapping procedure is paired with a trained navigation policy to enable autonomous map generation. The proposed method significantly outperforms a variety of baselines, including an object-based system and a pretrained scene classifier, in experiments in a photorealistic simulator.
Read more4/16/2024

0
Open-Set 3D Semantic Instance Maps for Vision Language Navigation -- O3D-SIM
Laksh Nanwani, Kumaraditya Gupta, Aditya Mathur, Swayam Agrawal, A. H. Abdul Hafez, K. Madhava Krishna
Humans excel at forming mental maps of their surroundings, equipping them to understand object relationships and navigate based on language queries. Our previous work SI Maps [1] showed that having instance-level information and the semantic understanding of an environment helps significantly improve performance for language-guided tasks. We extend this instance-level approach to 3D while increasing the pipeline's robustness and improving quantitative and qualitative results. Our method leverages foundational models for object recognition, image segmentation, and feature extraction. We propose a representation that results in a 3D point cloud map with instance-level embeddings, which bring in the semantic understanding that natural language commands can query. Quantitatively, the work improves upon the success rate of language-guided tasks. At the same time, we qualitatively observe the ability to identify instances more clearly and leverage the foundational models and language and image-aligned embeddings to identify objects that, otherwise, a closed-set approach wouldn't be able to identify.
Read more4/30/2024

0
Volumetric Semantically Consistent 3D Panoptic Mapping
Yang Miao, Iro Armeni, Marc Pollefeys, Daniel Barath
We introduce an online 2D-to-3D semantic instance mapping algorithm aimed at generating comprehensive, accurate, and efficient semantic 3D maps suitable for autonomous agents in unstructured environments. The proposed approach is based on a Voxel-TSDF representation used in recent algorithms. It introduces novel ways of integrating semantic prediction confidence during mapping, producing semantic and instance-consistent 3D regions. Further improvements are achieved by graph optimization-based semantic labeling and instance refinement. The proposed method achieves accuracy superior to the state of the art on public large-scale datasets, improving on a number of widely used metrics. We also highlight a downfall in the evaluation of recent studies: using the ground truth trajectory as input instead of a SLAM-estimated one substantially affects the accuracy, creating a large gap between the reported results and the actual performance on real-world data.
Read more7/9/2024