Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models

0

Sign in to get full access
Overview
- This paper introduces a novel approach for open-vocabulary 3D semantic segmentation using text-to-image diffusion models.
- The method allows for segmenting 3D scenes with a wide range of object categories without requiring bespoke training on each class.
- The technique leverages pre-trained text-to-image diffusion models to generate high-quality 2D semantic segmentation maps, which are then projected back into 3D space.
Plain English Explanation
The researchers have developed a new way to automatically identify and label different objects in 3D scenes, such as the objects in a room or the elements of a 3D model. Traditionally, this kind of 3D semantic segmentation has required training separate machine learning models for each specific type of object. However, this paper introduces a technique that can handle a much broader range of objects without needing to train individual models.
The key insight is to use powerful text-to-image diffusion models that have been pre-trained on a massive amount of online data. These models are able to understand the meaning of words and translate them into detailed 2D images. The researchers leverage this capability to generate 2D semantic segmentation maps directly from text descriptions of the objects. They then take these 2D segmentation maps and project them back into the 3D space, allowing for comprehensive 3D scene understanding.
This open-vocabulary approach is a significant advancement over previous methods that were limited to a fixed set of object categories. By tapping into the broad knowledge of text-to-image models, this new technique can be applied to segment 3D scenes containing a huge variety of different objects, without the need for bespoke training. This flexibility has important implications for real-world applications like augmented reality, robotics, and 3D content creation.
Technical Explanation
The paper proposes a novel framework for open-vocabulary 3D semantic segmentation that leverages pre-trained text-to-image diffusion models. The key innovation is to generate 2D semantic segmentation maps directly from textual object descriptions, and then project these back into the 3D scene.
The authors first obtain 3D point cloud data and corresponding camera parameters. They then use a pre-trained text-to-image diffusion model to generate high-quality 2D segmentation maps for each annotated object category. These 2D maps are projected back into the 3D space using the provided camera parameters, resulting in a training-free open-vocabulary 3D segmentation of the scene.
The generated 3D segmentation can then be refined using view selection and 3D captioning techniques to improve the accuracy and coherence of the final output.
Critical Analysis
The paper presents a compelling approach that addresses key limitations of prior work on 3D semantic segmentation. By leveraging powerful text-to-image diffusion models, the method can handle a much broader range of object categories without the need for bespoke training. This is a significant advantage over traditional techniques that are constrained to a fixed set of classes.
However, the authors acknowledge that the performance of the approach is dependent on the quality of the pre-trained text-to-image model. If the diffusion model has gaps in its knowledge or struggles with certain object types, this will translate to errors in the 3D segmentation. Further research is needed to understand the failure modes and robustness of this approach across diverse 3D scenes and object types.
Additionally, the paper does not provide a detailed analysis of the computational efficiency of the pipeline. Projecting 2D segmentation maps into 3D space and refining the results could potentially be computationally intensive, limiting the real-world applicability of the method. Future work should investigate ways to optimize the inference speed of the system.
Overall, this paper represents an exciting step forward in 3D semantic understanding, leveraging the powerful capabilities of text-to-image diffusion models. With further refinement and validation, the proposed approach could have significant impact on applications like augmented reality, robotics, and 3D content creation.
Conclusion
The researchers have developed a novel technique for open-vocabulary 3D semantic segmentation that leverages pre-trained text-to-image diffusion models. By generating 2D segmentation maps from textual object descriptions and projecting them into 3D space, the method can handle a much wider range of object categories compared to traditional approaches.
This flexibility has important implications for real-world applications that require robust 3D scene understanding, such as augmented reality, robotics, and 3D content creation. While the approach shows promising results, further research is needed to understand its limitations and optimize its computational efficiency. Overall, this paper represents an exciting advancement in the field of 3D semantic understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models
Xiaoyu Zhu, Hao Zhou, Pengfei Xing, Long Zhao, Hao Xu, Junwei Liang, Alexander Hauptmann, Ting Liu, Andrew Gallagher
In this paper, we investigate the use of diffusion models which are pre-trained on large-scale image-caption pairs for open-vocabulary 3D semantic understanding. We propose a novel method, namely Diff2Scene, which leverages frozen representations from text-image generative models, along with salient-aware and geometric-aware masks, for open-vocabulary 3D semantic segmentation and visual grounding tasks. Diff2Scene gets rid of any labeled 3D data and effectively identifies objects, appearances, materials, locations and their compositions in 3D scenes. We show that it outperforms competitive baselines and achieves significant improvements over state-of-the-art methods. In particular, Diff2Scene improves the state-of-the-art method on ScanNet200 by 12%.
Read more7/19/2024
0
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
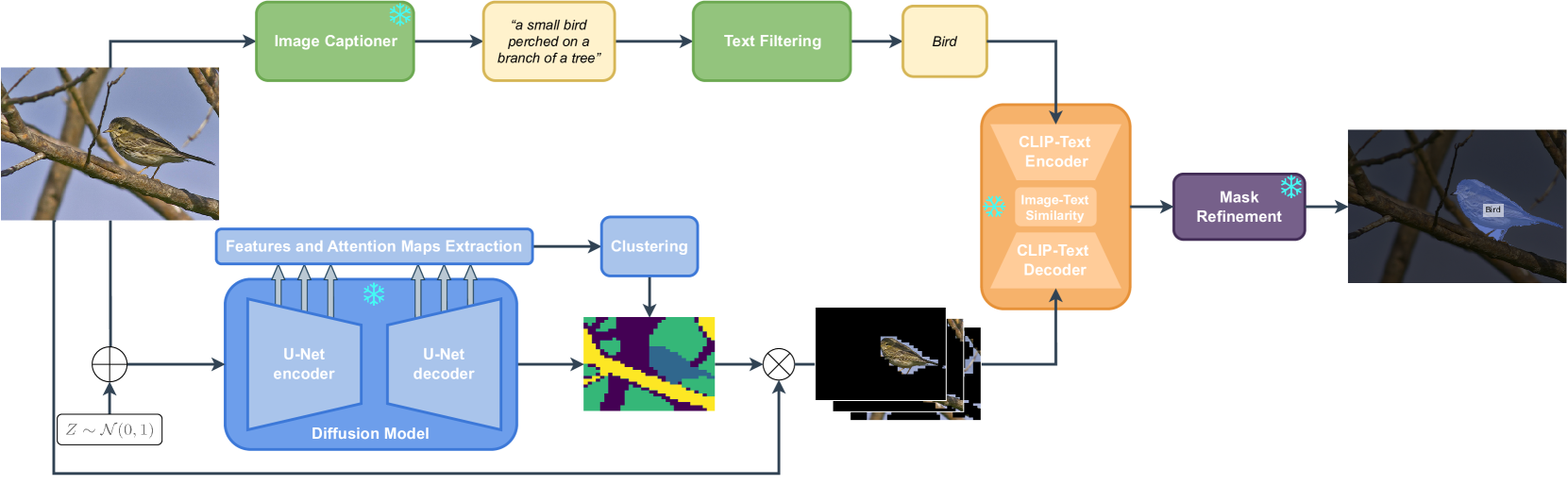
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
Read more4/1/2024

0
Enhancing Label-efficient Medical Image Segmentation with Text-guided Diffusion Models
Chun-Mei Feng
Aside from offering state-of-the-art performance in medical image generation, denoising diffusion probabilistic models (DPM) can also serve as a representation learner to capture semantic information and potentially be used as an image representation for downstream tasks, e.g., segmentation. However, these latent semantic representations rely heavily on labor-intensive pixel-level annotations as supervision, limiting the usability of DPM in medical image segmentation. To address this limitation, we propose an enhanced diffusion segmentation model, called TextDiff, that improves semantic representation through inexpensive medical text annotations, thereby explicitly establishing semantic representation and language correspondence for diffusion models. Concretely, TextDiff extracts intermediate activations of the Markov step of the reverse diffusion process in a pretrained diffusion model on large-scale natural images and learns additional expert knowledge by combining them with complementary and readily available diagnostic text information. TextDiff freezes the dual-branch multi-modal structure and mines the latent alignment of semantic features in diffusion models with diagnostic descriptions by only training the cross-attention mechanism and pixel classifier, making it possible to enhance semantic representation with inexpensive text. Extensive experiments on public QaTa-COVID19 and MoNuSeg datasets show that our TextDiff is significantly superior to the state-of-the-art multi-modal segmentation methods with only a few training samples.
Read more7/9/2024
📈
0
Grounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion Model
Xiaolong Li, Jiawei Mo, Ying Wang, Chethan Parameshwara, Xiaohan Fei, Ashwin Swaminathan, CJ Taylor, Zhuowen Tu, Paolo Favaro, Stefano Soatto
In this paper, we propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model. Multi-view diffusion models, such as MVDream, have shown to generate high-fidelity 3D assets using score distillation sampling (SDS). However, applied naively, these methods often fail to comprehend compositional text prompts, and may often entirely omit certain subjects or parts. To address this issue, we first advocate leveraging text-guided 4-view images as the bottleneck in the text-to-3D pipeline. We then introduce an attention refocusing mechanism to encourage text-aligned 4-view image generation, without the necessity to re-train the multi-view diffusion model or craft a high-quality compositional 3D dataset. We further propose a hybrid optimization strategy to encourage synergy between the SDS loss and the sparse RGB reference images. Our method consistently outperforms previous state-of-the-art (SOTA) methods in generating compositional 3D assets, excelling in both quality and accuracy, and enabling diverse 3D from the same text prompt.
Read more4/30/2024